


V. Manipulation de fichiers▲
Une fois que l'exécution d'un programme est terminée, toutes les données qu'il a créées et stockées dans des variables sont supprimées de la mémoire. Pour pouvoir stocker des informations de manière permanente, il faut les sauvegarder dans des fichiers. Ce chapitre commence par présenter quelques notions liées au concept de fichier, puis enchaine en voyant comment créer et modifier des fichiers textes et binaires.
V-A. Fichier▲
Un fichier est une abstraction d'une partie de la mémoire qui représente une information. Celle-ci peut prendre différentes formes : un document texte, une image, un son, une vidéo, un exécutable… Au plus bas niveau, toute information est stockée de la même manière, à savoir comme une séquence de bits (kitxmlcodeinlinelatexdvp0finkitxmlcodeinlinelatexdvp ou kitxmlcodeinlinelatexdvp1finkitxmlcodeinlinelatexdvp) qu'il faut interpréter pour obtenir l'information de haut niveau représentée.
Plusieurs opérations peuvent être réalisées avec des fichiers. On peut tout d'abord en créer et en supprimer et lire et modifier leur contenu. Un fichier est également caractérisé par plusieurs informations que l'on peut obtenir, telles que son nom, sa taille, sa date de création et de dernière modification, ses permissions d'accès, etc. Toutes ces opérations peuvent être réalisées en Python, à l'aide de fonctions faisant essentiellement partie des modules os, os.path et shutil qui font le relais entre l'interpréteur Python et le système d'exploitation (Linux, Windows, MacOS…), qui est le seul à avoir directement accès aux disques. On ne va pas détailler toutes ces opérations ici, mais se concentrer sur la lecture et l'écriture de fichiers.
On distingue couramment deux types de fichiers, qui seront manipulés à des niveaux différents :
- un fichier texte est constitué d'une séquence de caractères, permettant de stocker une chaine de caractères sur disque. Un fichier .py contenant le code source d'un programme Python est un exemple d'un tel fichier ;
- un fichier binaire est constitué d'une séquence de bits, organisés en paquets de huit, appelés octets. Un fichier .png avec une image est un exemple d'un tel fichier.
La seule raison pour laquelle on différencie ces deux types de fichiers est que Python propose des fonctions spécifiques différentes permettant de facilement les manipuler. Dans l'absolu, il n'y a qu'un seul type de fichiers, les fichiers texte étant également des fichiers binaires.
V-A-1. Créer et modifier un fichier▲
Pour manipuler un fichier, que ce soit en mode texte ou binaire, il y a trois principales étapes à suivre.
- Il faut d'abord ouvrir le fichier désiré, en lecture ou en écriture. S'il s'agit d'un nouveau fichier, il doit être avant tout créé.
- Une fois le fichier ouvert, on va pouvoir effectuer des opérations de lecture et d'écriture sur ce dernier.
- Enfin, une fois que l'on a terminé, il faut fermer le fichier pour libérer les ressources allouées par le système d'exploitation.
Deux erreurs peuvent survenir lorsqu'on manipule un fichier. Tout d'abord, il se peut que le fichier que l'on tente d'ouvrir n'existe pas, dans lequel cas une erreur de type FileNotFoundError est générée. Ensuite, durant la lecture ou l'écriture, différentes situations d'erreur peuvent survenir comme le disque qui devient plein, l'utilisateur qui n'a pas les droits suffisants pour lire/écrire un fichier, etc. Dans toutes ces situations, une erreur de type IOError survient, signalant en fait une erreur d'entrée/sortie. Si on veut un programme robuste, il faudra les traiter à l'aide d'un try-except.
L'exception IOError est en fait une erreur générique d'entrée/sortie et on peut se limiter à gérer cette dernière. Néanmoins, il est parfois utile de gérer ses cas particuliers, parmi lesquels on a :
- FileNotFoundError si le fichier n'existe pas ;
- FileExistsError si le fichier existe déjà ;
- PermissionError si le programme n'a pas les droits d'accès nécessaires sur le fichier ;
- et IsADirectoryError si le fichier est en fait un dossier.
V-A-1-a. Chemin▲
Lorsqu'on veut créer un nouveau fichier ou en ouvrir un existant pour le lire ou le modifier, il faut préciser l'endroit où il est stocké, en spécifiant son chemin. Deux types de chemins sont possibles : relatif ou absolu.
Un chemin relatif décrit l'endroit où se trouve le fichier par rapport à l'endroit d'où est exécuté le programme. On peut connaitre le répertoire courant à l'aide de la fonction getcwd du module os :
import os
print(os.getcwd())Si on exécute ce programme sur une machine avec MacOS, on pourrait, par exemple, obtenir le résultat suivant :
/Users/combefis/DesktopUn chemin relatif localise un fichier par rapport au répertoire courant. Si on indique juste un nom de fichier, cela revient à le chercher dans le répertoire courant. Si le chemin que l'on demande contient des répertoires, ils seront suivis à partir du répertoire courant. Enfin, on peut utiliser la notation spéciale ../ pour remonter d'un répertoire. Le tableau de la figure 1 reprend des chemins relatifs avec le chemin absolu correspondant, en supposant que l'on se trouve dans le répertoire courant montré ci-dessus.
|
Chemin relatif |
Chemin absolu |
|---|---|
|
Sélectionnez |
Sélectionnez |
|
Sélectionnez |
Sélectionnez |
|
Sélectionnez |
Sélectionnez |
|
Sélectionnez |
Sélectionnez |
Un chemin absolu donne donc la position d'un fichier à partir de la racine du disque. On peut transformer un chemin relatif en un absolu à l'aide de la fonction abspath du module os.path. De plus, on peut tester si un chemin correspond à un fichier qui se trouve réellement sur le disque avec la fonction exists du même module.
L'exemple suivant teste si un fichier référencé par un chemin relatif existe sur le disque, et affiche un message signalant l'existence ou non du fichier :
2.
3.
4.
5.
6.
7.
8.
9.
import os.path
path = 'data.txt'
print('Le fichier', os.path.abspath(path), end=' ')
if os.path.exists(path):
print('existe.')
else:
print('n\'existe pas.')
Si le fichier en question n'existe pas, on obtiendra le résultat suivant lors de l'exécution du programme :
Le fichier /Users/combefis/Desktop/data.txt n'existe pas.Attention qu'il y a des différences sous Windows. Tout d'abord, la racine du disque est indiquée par un nom de lecteur, comme C:\, par exemple. De plus, le séparateur utilisé entre les répertoires est \ au lieu de /.
V-B. Fichier texte▲
Un fichier texte est composé d'une séquence de caractères. Parmi ceux-ci, on retrouve le caractère de saut de ligne et on peut donc également voir un fichier texte comme une séquence de lignes.
Comme dit précédemment, un fichier texte n'est qu'un fichier binaire. Les bits stockés dans le fichier sont en fait lus par blocs qui sont ensuite interprétés comme des caractères. Cette traduction se fait en suivant l'encodage qui a été utilisé pour sauvegarder le fichier. Python travaille par défaut avec l'encodage UTF-8, où chaque caractère par blocs de 8 bits. Ce principe est détaillé plus loin dans cette section.
V-B-1. Ouverture et fermeture▲
L'ouverture d'un fichier se fait à l'aide de la fonction prédéfinie open. Il suffit de lui passer en paramètre le chemin du fichier à ouvrir. La fonction renvoie un identifiant vers le fichier ouvert, que l'on pourra ensuite utiliser pour lire et écrire dans le fichier. Deux exceptions peuvent survenir lors de l'ouverture d'un fichier, FileNotFoundError si le fichier n'a pas été trouvé et IOError pour les autres erreurs.
L'exemple suivant tente d'ouvrir le fichier data.txt et affiche l'identifiant renvoyé par la fonction open, avant de le refermer :
L'exécution du programme affiche le résultat suivant, qui dévoile plusieurs informations par rapport au fichier ouvert :
<_io.TextIOWrapper name='data.txt' mode='r' encoding='UTF-8'>La variable file contient donc une référence vers un objet de type io.TextIOWrapper. On peut voir trois attributs de cet objet :
- le nom du fichier ouvert est data.txt (name) ;
- le fichier est ouvert en mode lecture seule (mode) ;
- et enfin, l'encodage utilisé est UTF-8 (encoding).
Une fois que l'on a fini avec le fichier, il faut le fermer pour libérer les ressources qui ont été allouées en mémoire pour son traitement. Pour cela, on fait simplement appel à la méthode close.
V-B-1-a. Mode d'ouverture▲
Par défaut, un fichier texte est ouvert en lecture seule, c'est-à-dire que seules les opérations permettant de lire son contenu sont autorisées. D'autres modes d'ouverture sont possibles, et peuvent être spécifiés comme deuxième paramètre de la fonction open. Un mode est décrit par un ou plusieurs caractères ayant chacun une signification particulière, repris dans le tableau de la figure 2.
|
Caractère |
Description |
|---|---|
|
r |
Lecture (par défaut) |
|
w |
Écriture (avec remise à zéro) |
|
x |
Création exclusive (erreur si fichier déjà existant) |
|
a |
Écriture (avec ajout à la fin) |
|
b |
Mode binaire |
|
t |
Mode texte (par défaut) |
Par défaut, le mode d'ouverture d'un fichier est rt, à savoir que l'accès se fait en mode texte et en lecture seule. Pour écrire dans un fichier, on utilisera le mode w ou a. Dans les deux cas, le fichier ouvert est créé s'il n'existe pas. Si le fichier existe, son contenu est complètement effacé dans le premier cas, et l'écriture démarre à la fin du contenu dans le second cas. Enfin, le mode x permet de générer une erreur de type FileExistsError si le fichier existe déjà.
V-B-1-b. Lecture▲
Pour lire un fichier texte, préalablement ouvert, plusieurs méthodes sont utilisables. Le plus facile consiste à utiliser la méthode read qui va lire l'intégralité du fichier et renvoyer son contenu sous forme d'une chaine de caractères. Lors de la lecture, une exception de type IOError peut se produire, si le disque est corrompu ou s'il est déconnecté pendant la lecture, par exemple. Le programme suivant affiche l'intégralité du contenu du fichier data.txt :
Malgré que cette méthode soit très pratique, elle n'est pas forcément recommandée, surtout lorsque le fichier à lire est gros. En effet, la totalité du fichier va être lue depuis le disque et être placée dans une variable Python, ce qui va consommer de la mémoire.
V-B-1-b-i. Lecture ligne par ligne▲
Parfois, on souhaite pouvoir lire les lignes d'un fichier séparément. Une fois le fichier lu intégralement, on pourrait parcourir la chaine de caractères ainsi obtenue et identifier les lignes en repérant les caractères de retour à la ligne (\n sous Linux et MacOS et \r\n sous Windows).
Pour faciliter les choses, il existe une méthode readlines qui renvoie une liste de chaines de caractères, dont chaque élément correspond à une ligne. Les instructions suivantes ouvrent le fichier data.txt en lecture seule pour récupérer son contenu comme une liste de lignes qui sont ensuite affichées à l'aide d'une boucle for :
Si on suppose que le fichier data.txt possède cinq lignes, chacune contenant juste un chiffre allant de kitxmlcodeinlinelatexdvp1finkitxmlcodeinlinelatexdvp à kitxmlcodeinlinelatexdvp5finkitxmlcodeinlinelatexdvp, le résultat de l'exécution du programme serait le suivant :
2.
3.
4.
5.
6.
7.
8.
9.
1
2
3
4
5
Comme vous le constatez, il y a une série de lignes vides dans l'affichage produit. La méthode readlines ne supprime en fait pas le caractère de fin de ligne dans le résultat qu'elle renvoie. Si on ne veut pas de ce ou ces caractères de fin de ligne, il faut s'en débarrasser manuellement. Pour ce faire, on peut, par exemple, utiliser la méthode rstrip des chaines de caractères qui permet de supprimer tous les caractères blancs (espace, tabulation, retour à la ligne…) qui se trouvent à la droite d'une chaine de caractères. Il suffit donc de remplacer la boucle for par :
for line in content:
print(line.rstrip())V-B-1-b-ii. Itérateur de lignes▲
Avec la méthode readlines, on a le même problème qu'avec read, à savoir que l'intégralité du fichier est lue en une fois, et doit donc être stockée en mémoire. Une autre solution consiste à utiliser un itérateur sur le fichier ouvert, que l'on va pouvoir parcourir à l'aide d'une boucle for. De nouveau, le ou les caractères de retour à la ligne seront inclus et doivent être supprimés avec rstrip si on n'en veut pas. Voici la nouvelle version de la lecture du fichier data.txt :
Le premier avantage est que le code est beaucoup plus compact et lisible. Le deuxième avantage est que le fichier est lu au fur et à mesure sur le disque, et pas intégralement comme avec les deux solutions précédentes.
V-B-1-b-iii. Écriture▲
Voyons maintenant comment écrire un fichier texte. L'ouverture et la fermeture du fichier fonctionnent exactement de la même manière que pour la lecture, si ce n'est que le mode doit inclure w ou a. De nouveau, une exception de type IOError peut se produire, si le disque devient plein pendant l'écriture, par exemple.
Pour écrire dans un fichier, on utilise la méthode write qui ajoute la chaine de caractères reçue en paramètre dans le fichier. L'exemple suivant écrit la table de multiplication de kitxmlcodeinlinelatexdvp7finkitxmlcodeinlinelatexdvp dans le fichier data.txt :
On ouvre d'abord le fichier en mode écriture avec w. On écrit ensuite une première ligne avant de rentrer dans une boucle pour afficher les lignes de la table de multiplication. Remarquez que l'on doit manuellement ajouter le retour à la ligne dans la chaine de caractères envoyée à la fonction write. Voici le fichier data.txt produit par ce programme :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
Table de 7 :
0 x 7 = 0
1 x 7 = 7
2 x 7 = 14
3 x 7 = 21
4 x 7 = 28
5 x 7 = 35
6 x 7 = 42
7 x 7 = 49
8 x 7 = 56
9 x 7 = 63
Quelques remarques sont à soulever par rapport à l'écriture dans un fichier texte.
- Lorsqu'on fait une écriture de fichier, sa fermeture à la fin des opérations avec la méthode close est très importante. En effet, sans cet appel, il se peut que les données ne soient pas écrites sur le disque, mais uniquement dans la mémoire tampon du système d'exploitation. Le fichier créé sera donc vide sur le disque.
- Avec le mode w, si le fichier existe, son contenu est complètement effacé et l'écriture commence à son début. Pour éviter cela, il faut soit utiliser le mode a, dans lequel l'écriture commence après le contenu actuel du fichier s'il existe déjà, soit utiliser le mode x qui provoque une erreur de type FileExistsError si le fichier existe déjà, ou enfin tester avant si le fichier existe ou non, avec la fonction exists du module os.path.
- Enfin, si on utilise le caractère \n pour la fin de ligne, elles ne seront pas forcément valables sur tous les systèmes d'exploitation. Le ou les caractères qui identifient une fin de ligne se trouvent dans la variable globale os.linesep du module os.
V-B-1-b-iv. Encodage▲
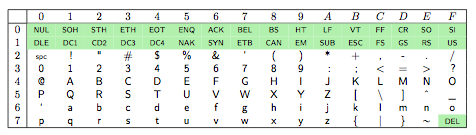
En informatique, tout caractère est en fait associé à un identifiant numérique qui est typiquement un nombre entier. Cette correspondance est établie dans une table de caractères. Par exemple, la table de caractères ASCII ou iso-646 (l'American Standard Code for Information Interchange (ASCII) a été développé pour représenter les caractères anglais) contient un total de kitxmlcodeinlinelatexdvp128finkitxmlcodeinlinelatexdvp caractères et est utilisée pour représenter les caractères anglais. Cette dernière est reprise à la figure 3, où l'identifiant numérique de chaque caractère est obtenu en additionnant le produit du numéro de sa ligne par kitxmlcodeinlinelatexdvp16finkitxmlcodeinlinelatexdvp avec le numéro de sa colonne (sachant que kitxmlcodeinlinelatexdvpA = 10finkitxmlcodeinlinelatexdvp, kitxmlcodeinlinelatexdvpB = 11finkitxmlcodeinlinelatexdvp…).
Deux fonctions prédéfinies permettent d'effectuer la conversion entre un caractère et son identifiant numérique correspondant. La fonction ord donne l'identifiant numérique correspondant à un caractère tandis que la fonction chr fait l'opération inverse. Examinons l'exemple suivant :
Le caractère | doit avoir comme code kitxmlcodeinlinelatexdvp7 \times 16 + 12 = 124finkitxmlcodeinlinelatexdvp et le caractère dont le code est kitxmlcodeinlinelatexdvp65 = 4 \times 16 + 1finkitxmlcodeinlinelatexdvp est le A. Ces calculs sont confirmés par le résultat de l'exécution des deux instructions :
124
AÀ la table de caractères, il faut associer une méthode d'encodage, c'est-à-dire une manière de représenter chaque identifiant numérique en une suite de bits. Pour l'ASCII, ce n'est pas très compliqué, il suffit de kitxmlcodeinlinelatexdvp7finkitxmlcodeinlinelatexdvp bits pour chaque caractère afin de pouvoir tous les représenter et c'est ce qui est fait.
V-B-1-b-v. Unicode▲
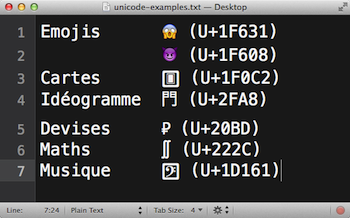
Python fonctionne avec la table de caractères Unicode (ISO 10646), un standard d'échange de texte qui a vu le jour en 1987. Cette table comporte plus de kitxmlcodeinlinelatexdvp128000finkitxmlcodeinlinelatexdvp caractères (la liste de tous les caractères Unicode peut être consultée sur le site web suivant : http://unicode-table.com/) dans sa dernière version.
De plus, Python utilise l'encodage UTF-8 pour représenter les caractères Unicode, dans lequel l'unité de base est un bloc de kitxmlcodeinlinelatexdvp8finkitxmlcodeinlinelatexdvp bits. Cet encodage est compatible avec l'ASCII, c'est-à-dire que ses kitxmlcodeinlinelatexdvp128finkitxmlcodeinlinelatexdvp caractères ont le même identifiant numérique.
Comme le montre la figure 4, Unicode contient beaucoup de caractères, permettant ainsi de couvrir toutes les langues du monde et encore plus, comme les emojis, par exemple.
V-B-1-b-vi. Séquence d'échappement▲
Si on souhaite insérer un caractère Unicode dans une chaine de caractères, sans savoir le taper directement au clavier, on peut utiliser une séquence d'échappement comme on a vu au chapitre 2.
Pour insérer un caractère Unicode, il suffit d'écrire \u ou \U suivi de l'identifiant numérique du caractère voulu. La différence entre les deux notations est que la première se limite aux identifiants représentables sur 16 bits alors que la seconde permet d'aller jusque 32 bits.
Par exemple, pour écrire le symbole de l'intégrale double et l'emoji étonné/effrayé, il suffit d'écrire les instructions suivantes :
print('\u222C')
print('\U0001F631')V-B-1-b-vii. Choix de l'encodage▲
Lorsqu'on lit ou écrit un fichier texte dont l'encodage n'est pas UTF-8, il faut le préciser lors de l'ouverture à l'aide du paramètre nommé encoding. Évidemment, on sera du coup limité par rapport aux caractères que l'on pourra lire et écrire.
Par exemple, le programme suivant provoque une erreur d'exécution, car on tente d'écrire un caractère n'étant pas dans la table ASCII alors que le fichier a été créé suivant cet encodage :
2.
3.
4.
Traceback (most recent call last):
File "program.py", line 3, in <module>
file.write('€')
UnicodeEncodeError: 'ascii' codec can't encode character '\u20ac' in position 0: ordinal not in range(128)
V-C. Gestionnaire de contexte▲
Pour lire ou écrire un fichier, il faut commencer par l'ouvrir et terminer en le fermant, toutes les opérations sur le fichier se passant entre ces deux opérations. C'est ce que l'on appelle un contexte dans lequel on rentre pour pouvoir effectuer une série d'opérations avant de le quitter. Python propose une construction permettant de rendre le code plus lisible dans de telles situations, et c'est le sujet de cette section.
V-C-1. Fermeture du fichier▲
Comme on l'a déjà dit plusieurs fois, il est important de fermer un fichier ouvert une fois que les opérations sur ce dernier sont finies. Le problème qui peut survenir avec tous les exemples que l'on a vus précédemment est que, si une exception se produit pendant la lecture ou l'écriture du fichier, l'exécution saute dans le bloc except correspondant et la fermeture n'aura jamais lieu.
Pour résoudre ce problème, on pourrait se dire qu'il suffit de placer la fermeture du fichier dans un bloc finally pour être sûr qu'elle soit exécutée à tous les coups :
Cette solution n'est pas encore idéale, car une erreur sera produite par le close dans le cas où le fichier n'a pas su être ouvert. En effet, dans ce cas, la variable file n'existe pas et on se retrouve avec l'erreur suivante :
2.
3.
4.
5.
Fichier introuvable.
Traceback (most recent call last):
File "program.py", line 9, in <module>
print(file)
NameError: name 'file' is not defined
On va donc rajouter un nouveau bloc try qui va exclure l'ouverture du fichier, pour pouvoir lui attacher un bloc finally qui ferme le fichier. On sera ainsi certain que si le fichier a été ouvert, il sera d'office fermé. Le programme devient donc :
Ce code devient difficilement lisible, mais propose une solution élégante pour s'assurer de la fermeture du fichier, et donc de la libération des ressources, dans tous les cas.
V-C-1-a. Instruction with▲
Python propose l'instruction with pour proprement gérer un contexte et automatiquement libérer les ressources au moment où le contexte est quitté. Voyons d'abord comment l'exemple précédent se réécrit :
On utilise donc le mot réservé with suivi de l'appel de fonction qui crée l'objet qui sera utilisé dans le contexte, à savoir le fichier. On peut affecter le résultat renvoyé par la fonction à une variable en plaçant le nom désiré après le mot réservé as. Le bloc de code qui suit sera exécuté dans le contexte et la variable initialisée par le with y sera accessible. Une fois la fin de ce bloc atteint, la ressource du contexte sera libérée, c'est-à-dire que le fichier sera fermé.
On peut ouvrir plusieurs contextes avec la même instruction with. Il suffit pour cela de les séparer par des virgules, chacun ayant sa propre variable associée, évidemment. Voici, par exemple, comment on pourrait très facilement copier le contenu du fichier texte a.txt vers le fichier b.txt :
Une fois le bloc with terminé, les deux fichiers ouverts sont automatiquement fermés. Pour être complet, il faudrait évidemment ajouter la gestion des erreurs d'entrée/sortie sur cet exemple. De plus, ce serait mieux de vérifier que le fichier destination n'existe pas déjà si on veut éviter que ce dernier ne soit écrasé, en utilisant le mode x, par exemple.
V-D. Fichier binaire▲
Maintenant que l'on sait manipuler des fichiers textes, intéressons-nous à la manipulation de bas niveau, à savoir aux fichiers binaires. L'avantage par rapport aux fichiers textes est qu'ils sont plus compacts en termes d'espace occupé et également plus rapide à lire et écrire. Par contre, la difficulté avec ces fichiers est qu'il faut, pour pouvoir les manipuler, connaitre précisément l'organisation des données en leur sein.
L'ouverture et la fermeture d'un fichier binaire se font de la même manière qu'avec un fichier texte, si ce n'est qu'il faut spécifier le bon mode. Il suffit d'ajouter b dans le descripteur de mode, pour signaler qu'il s'agit d'un fichier binaire. Pour la lecture, on utilise donc rb et l'écriture se définit avec wb. Pour ouvrir le fichier binaire data.bin en lecture, il suffit d'écrire :
V-D-1. Lecture et écriture d'objets avec pickle▲
Le module pickle propose plusieurs fonctions qui vont permettre de directement lire et écrire des objets Python au format binaire depuis un fichier, sans que l'on ait besoin de savoir comment ils sont convertis en binaire. L'avantage de cette façon de procéder réside donc dans sa simplicité d'utilisation.
V-D-1-a. Écriture▲
Commençons par voir comment écrire des données dans un fichier binaire avec le module pickle. L'exemple suivant écrit une chaine de caractères suivie d'une liste de cinq nombres entiers dans le fichier data.bin, en mode binaire :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
import pickle
name = 'Temperature (2016)'
data = [12, -9, 7, 112, 99]
try:
with open('data.bin', 'wb') as file:
pickle.dump(name, file, pickle.HIGHEST_PROTOCOL)
pickle.dump(data, file, pickle.HIGHEST_PROTOCOL)
except (IOError, pickle.PicklingError):
print('Erreur d\'écriture.')
Après avoir importé le module pickle, on ouvre le fichier data.bin en mode binaire et en écriture. On utilise ensuite la fonction dump du module pickle pour écrire un objet dans le fichier. Cette fonction nécessite trois paramètres : une référence vers l'objet à écrire, une référence vers le fichier où écrire et enfin une option. Cette dernière définit notamment la manière avec laquelle les objets sont traduits en binaire et est souvent simplement fixée à pickle.HIGHEST_PROTOCOL.
Comme on peut le voir sur la figure 5, le fichier généré par l'exécution de ce programme est bel et bien un fichier binaire, pas lisible directement avec un éditeur texte.
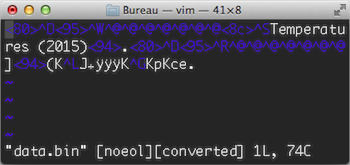
L'écriture d'un objet dans un fichier binaire peut générer une erreur de type pickle.PicklingError si jamais l'objet ne peut pas être converti. De plus, l'exception de type IOError est toujours possible en cas d'erreur d'écriture dans le fichier.
V-D-1-a-i. Lecture▲
Pour lire un fichier binaire, on utilise simplement la fonction load du module pickle. Il faut lire les objets successivement dans le fichier, avec autant d'appels que nécessaires à la fonction load. Les instructions suivantes lisent le fichier qui a été écrit par l'exemple précédent :
La fonction load prend en seul paramètre une référence vers le fichier dans lequel elle doit lire un objet. Cette lecture peut provoquer une erreur de type pickle.UnpicklingError si jamais l'objet ne sait pas être lu depuis le fichier. De nouveau, une exception de type IOError peut se produire, en cas d'erreur de lecture cette fois-ci.
L'exécution du programme récupère bien les deux objets qui étaient stockés dans le fichier data.bin, comme en témoigne le résultat affiché :
Temperature (2016)
[12, -9, 7, 112, 99]V-D-1-b. Lecture et écriture de données primitives avec struct▲
Le module struct permet également de lire et écrire dans un fichier binaire, mais à un niveau plus bas. Il offre en effet des fonctions permettant de lire et écrire des données primitives ; on effectue avec ce dernier des manipulations brutes de données binaires.
V-D-1-b-i. Encodage/décodage de chaines de caractères▲
Comme on l'a vu précédemment, un caractère n'est rien d'autre qu'un nombre entier, à savoir son identifiant numérique. On peut convertir une chaine de caractères en la suite d'octets correspondants, à l'aide de la méthode encode, qui prend en paramètre l'encodage désiré. On obtient en retour un objet bytes, qui représente une liste d'octets.
L'exemple suivant encode une chaine de caractères en UTF-8 et affiche la liste des différents octets correspondants :
2.
3.
4.
5.
6.
7.
s = 'Hello'
data = s.encode('utf-8')
print(type(data))
print(data)
for b in data:
print(b)
2.
3.
4.
5.
6.
7.
<class 'bytes'>
b'Hello'
72
101
108
108
111
Comme on peut le constater sur le résultat de l'exécution, la variable data est bien de type bytes. De plus, si on affiche simplement la variable, Python affiche la chaine de caractères correspondante, préfixée d'un b pour se rappeler que c'est une séquence d'octets et pas de caractères. Enfin, la boucle for qui parcourt data affiche bien cinq nombres entiers, qui sont les identifiants numériques des lettres du mot « Hello ».
Dans l'autre sens, on peut convertir une séquence d'octets représentée par un objet bytes en une chaine de caractères avec la méthode decode. Pour reconvertir la variable data en une chaine de caractères, on écrit l'instruction suivante :
print(data.decode('utf-8'))L'exécution de cette instruction affiche bien Hello, sans le préfixe b cette fois-ci puisqu'il s'agit d'une chaine de caractères de type str :
HelloV-D-1-b-ii. Écriture▲
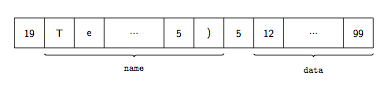
Reprenons le même exemple que précédemment, à savoir l'écriture d'une chaine de caractères et d'une liste d'entiers. Pour utiliser le module struct, il faut avant tout définir précisément le format de la donnée à écrire, octet par octet. La figure 6 montre comment on va stocker ces données dans le fichier :
- On commence par écrire un nombre entier, qui représente le nombre de caractères que contient la chaine à écrire ;
- Viennent ensuite les caractères de la chaine en question ;
- Puis on écrit de nouveau un nombre entier, qui représente cette fois-ci le nombre d'éléments de la liste d'entiers ;
- Et on termine avec les éléments de la liste.
Pour écrire une séquence d'octets dans un fichier binaire, on utilise la fonction pack du module struct. Cette dernière prend en paramètres une chaine de caractères qui décrit le type de la donnée à écrire et la donnée en question. Le tableau de la figure 7 reprend les principaux descripteurs de type de donnée à utiliser avec la fonction pack.
|
Caractère |
Description |
|---|---|
|
h |
Nombre entier signé (court) |
|
H |
Nombre entier non signé (court) |
|
i |
Nombre entier signé |
|
I |
Nombre entier non signé |
|
f |
Nombre flottant |
|
c |
Caractère |
|
s |
Chaine de caractères |
|
? |
Booléen |
Pour écrire dans le fichier binaire, on passe par la méthode write, comme avec les fichiers texte, à qui on passe en paramètre le résultat de l'appel de la fonction pack. Voici comment l'exemple précédent, qui écrit une chaine de caractères suivie d'une liste de nombres entiers, se réécrit avec le module struct :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
import struct
name = 'Temperature (2016)'
data = [12, -9, 7, 112, 99]
try:
with open('data.bin', 'wb') as file:
file.write(struct.pack('H', len(name)))
for c in name:
file.write(struct.pack('c', c.encode('utf-8')))
file.write(struct.pack('H', len(data)))
for elem in data:
file.write(struct.pack('h', elem))
except IOError:
print('Erreur d\'écriture.')
On écrit donc le nombre de caractères de la chaine comme un entier (H) puis, grâce à une boucle, chacun des caractères (c) encodé avec UTF-8. On suit exactement le même principe pour la liste d'entiers.
On aurait pu écrire les données d'une autre manière, en passant directement à pack tous les caractères ou tous les nombres entiers en une fois. Il suffit pour cela de faire précéder le descripteur de type de donnée par le nombre d'éléments à écrire.
On peut donc modifier l'exemple précédent en remplaçant les instructions qui font l'écriture avec les suivantes :
V-D-1-b-iii. Lecture▲
La lecture d'un fichier binaire créé avec struct se fait avec la fonction unpack qui prend deux paramètres, à savoir le format décrivant le type de donnée à lire et la séquence d'octets lue à l'aide de la fonction read sur le fichier. La fonction unpack renvoie un tuple avec les données qu'elle a lues, ce qui fait que lorsqu'on ne souhaite lire qu'un seul élément, il va falloir récupérer le premier élément du tuple comme on peut le voir sur l'exemple suivant qui lit le fichier créé précédemment :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
import struct
try:
with open('data.bin', 'rb') as file:
n = struct.unpack('H', file.read(2))[0]
name = ''
for i in range(n):
raw = struct.unpack('c', file.read(1))
name += raw[0].decode('utf-8')
n = struct.unpack('H', file.read(2))[0]
data = []
for i in range(n):
raw = struct.unpack('h', file.read(2))
data.append(raw[0])
print(name, data, sep='\n')
except IOError:
print('Erreur de lecture.')
Lorsqu'on effectue la lecture dans le fichier, avec la méthode read, il faut préciser le nombre d'octets que l'on veut lire. Un nombre entier non signé court occupe deux octets et un caractère en occupe un.
Notez enfin que ce programme de lecture fonctionne évidemment avec les deux manières d'écrire que l'on vient de voir. En effet, les deux façons de procéder écrivent les données dans le même ordre dans le fichier binaire. Il est donc très important de bien définir le format dans lequel les données sont écrites, ce qui permet de lire et écrire des fichiers écrits avec le module struct.
Tout comme pour l'écriture, on peut simplifier la lecture en lisant directement plusieurs données du même type :
Le module struct est plus complexe à utiliser que le module pickle, ce dernier écrivant directement et automatiquement des objets Python dans un fichier binaire, alors qu'il faut soi-même définir le format lorsqu'on utilise le module struct. Par contre, l'avantage du module struct est qu'il génère un fichier binaire bien plus compact. Pour l'exemple que l'on a utilisé, on se retrouve avec un fichier qui fait kitxmlcodeinlinelatexdvp33finkitxmlcodeinlinelatexdvp octets au lieu de kitxmlcodeinlinelatexdvp63finkitxmlcodeinlinelatexdvp pour le fichier créé avec le module pickle.