


I. Dictionnaire▲
On a vu les séquences dans la première partie du livre, et on va découvrir d'autres structures de données dans ce chapitre. On commence avec les ensembles qui sont étendus par l'ajout d'une valeur sur chacun de leurs éléments pour obtenir des dictionnaires. On voit également comment imbriquer des structures de données pour en créer des complexes. Enfin, on termine avec une introduction aux bases de données.
I-A. Ensemble▲
Un ensemble est une collection d'éléments distincts. Contrairement aux séquences que l'on a vues précédemment, les éléments d'un ensemble ne sont pas ordonnés et il ne contient pas d'éléments dupliqués.
I-A-1. Définition d'un ensemble▲
Python propose le type de données set pour représenter les ensembles. On peut créer un ensemble en listant tous ses éléments, séparés par des virgules, et en délimitant le tout avec des accolades. L'exemple suivant crée un ensemble avec cinq nombres entiers :
numbers = {42, -2, 0, 7, 11}Plusieurs opérations et fonctions applicables aux séquences le sont également aux ensembles. On peut notamment connaitre la taille d'un ensemble avec la fonction len et tester si un élément en fait partie ou non avec l'opérateur in. On ne peut par contre pas accéder aux éléments d'un ensemble à partir d'un indice, comme avec les séquences, puisqu'il s'agit d'une collection non ordonnée d'éléments. On ne peut donc parcourir les éléments d'un ensemble qu'avec la boucle for. L'exemple suivant illustre ces différentes opérations :
Comme on peut le constater sur le résultat de l'exécution de ces instructions, le type de la variable numbers est bien set :
2.
3.
4.
5.
6.
7.
8.
9.
10.
{0, 42, 11, -2, 7}
5
False
<class 'set'>
0
42
11
-2
7
Notez que l'affichage des éléments de l'ensemble peut tout à fait changer d'une exécution à l'autre. En effet, puisque les éléments d'un ensemble ne sont pas ordonnés, il n'y a pas d'unique ordre de parcours. La boucle for garantit juste que chaque élément de l'ensemble sera visité une fois.
Il y a deux autres manières courantes de créer un ensemble. Tout d'abord, on peut en créer un nouveau par compréhension, tout comme on l'a déjà fait avec les séquences. Par exemple, pour définir l'ensemble des entiers inférieurs à kitxmlcodeinlinelatexdvp100finkitxmlcodeinlinelatexdvp qui sont à la fois divisibles par kitxmlcodeinlinelatexdvp3finkitxmlcodeinlinelatexdvp et kitxmlcodeinlinelatexdvp7finkitxmlcodeinlinelatexdvp, on écrit :
S = {n for n in range(100) if n % 3 == 0 and n % 7 == 0}Cette notation est très similaire à celle utilisée en mathématiques pour définir des ensembles où on aurait écrit :
kitxmlcodelatexdvpS = \Big\{ n \in \mathbb{N} \textrm{ avec } 0 \leq n < 100 \quad\Big|\quad n \textrm{ est divisible par } 3 \textrm{ et } 7 \Big\}.finkitxmlcodelatexdvpEnsuite, on peut également créer un ensemble à partir d'une séquence. On utilise pour cela la fonction set en lui passant comme paramètre la séquence sur base de laquelle il faut créer l'ensemble. Voici deux exemples créant un ensemble, à partir d'une liste et d'une chaine de caractères :
Puisqu'un ensemble ne peut contenir de doublons, ils seront automatiquement supprimés comme on le voit sur le résultat de l'exécution :
{0, 42, 12, -1}
{'r', '!', 'o', 'c', 'C', 'i'}Si on veut définir un ensemble vide, il faut utiliser la fonction set :
emptyset = set()En effet, comme on le verra à la section suivante, la notation {} permet de définir un dictionnaire vide.
I-A-1-a. Modification d'un ensemble▲
Une fois un ensemble créé, il est possible d'en obtenir des informations ou de le modifier en utilisant des fonctions dédiées aux ensembles. On a déjà vu les fonctions len et in, dans la section précédente, qui permettent respectivement de connaitre la taille de l'ensemble et de tester l'appartenance d'un élément à un ensemble.
Une fois un ensemble créé, on peut le modifier, c'est-à-dire lui ajouter ou retirer des valeurs. On utilise pour cela les fonctions add et remove, qu'il faut appliquer sur la variable contenant l'ensemble. L'exemple suivant crée un ensemble, lui retire deux valeurs et en ajoute une :
2.
3.
4.
5.
6.
S = {1, 2, 3, 4}
S.remove(1)
S.remove(2)
S.add(5)
print(S)
Comme on peut le constater sur le résultat de l'exécution de ces instructions, l'ensemble qui contenait cinq éléments au départ ne contient plus que les trois éléments kitxmlcodeinlinelatexdvp3finkitxmlcodeinlinelatexdvp, kitxmlcodeinlinelatexdvp4finkitxmlcodeinlinelatexdvp et kitxmlcodeinlinelatexdvp5finkitxmlcodeinlinelatexdvp :
{3, 4, 5}Si on tente de supprimer un élément qui ne fait pas partie de l'ensemble, la fonction remove provoquera une erreur lors de l'exécution. Il existe également une fonction discard qui, elle, ne produira pas d'erreur. Enfin, il existe également une fonction pop qui permet d'obtenir l'un des éléments de l'ensemble, le retirant de ce dernier.
I-A-1-b. Opération ensembliste▲
Comme on le verra en détail plus loin, Python est un langage de programmation très riche qui permet notamment de définir des opérations spécifiques à chaque nouveau type de données.
En l'occurrence, il est possible d'effectuer des opérations ensemblistes sur les données de type set. La figure 1 illustre le résultat de ces différentes opérations, étant donné deux ensembles kitxmlcodeinlinelatexdvpAfinkitxmlcodeinlinelatexdvp et kitxmlcodeinlinelatexdvpBfinkitxmlcodeinlinelatexdvp :
- la différence entre kitxmlcodeinlinelatexdvpAfinkitxmlcodeinlinelatexdvp et kitxmlcodeinlinelatexdvpBfinkitxmlcodeinlinelatexdvp, notée kitxmlcodeinlinelatexdvpA \setminus Bfinkitxmlcodeinlinelatexdvp, contient tous les éléments de kitxmlcodeinlinelatexdvpAfinkitxmlcodeinlinelatexdvp sauf ceux appartenant également à kitxmlcodeinlinelatexdvpBfinkitxmlcodeinlinelatexdvp ;
- l'union des ensembles kitxmlcodeinlinelatexdvpAfinkitxmlcodeinlinelatexdvp et kitxmlcodeinlinelatexdvpBfinkitxmlcodeinlinelatexdvp, notée kitxmlcodeinlinelatexdvpA \cup Bfinkitxmlcodeinlinelatexdvp, contient tous les éléments se trouvant soit dans kitxmlcodeinlinelatexdvpAfinkitxmlcodeinlinelatexdvp, soit dans kitxmlcodeinlinelatexdvpBfinkitxmlcodeinlinelatexdvp (ou dans les deux) ;
- l'intersection des ensembles kitxmlcodeinlinelatexdvpAfinkitxmlcodeinlinelatexdvp et kitxmlcodeinlinelatexdvpBfinkitxmlcodeinlinelatexdvp, notée kitxmlcodeinlinelatexdvpA \cap Bfinkitxmlcodeinlinelatexdvp, contient tous les éléments se trouvant à la fois dans kitxmlcodeinlinelatexdvpAfinkitxmlcodeinlinelatexdvp et dans kitxmlcodeinlinelatexdvpBfinkitxmlcodeinlinelatexdvp.
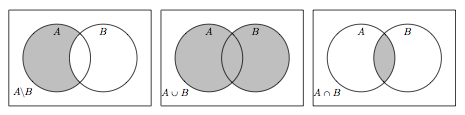
Comme on le verra plus loin dans ce livre, le langage Python permet de redéfinir des opérateurs pour tout nouveau type de données. En l'occurrence, les opérations ensemblistes de différence, d'union et d'intersection sont respectivement calculées par les opérateurs -, | et &. Voici un exemple utilisant ces trois opérateurs :
2.
3.
4.
5.
6.
A = {1, 2, 3, 4}
B = {3, 4, 5}
print(A - B)
print(A & B)
print(A | B)
Voici le diagramme de Venn reprenant les deux ensembles kitxmlcodeinlinelatexdvpAfinkitxmlcodeinlinelatexdvp et kitxmlcodeinlinelatexdvpBfinkitxmlcodeinlinelatexdvp, ainsi que leurs différents éléments :
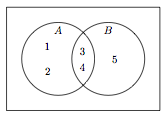
Le résultat de l'exécution de ces instructions correspond bien aux résultats attendus des opérations ensemblistes, et est conforme à ce que l'on peut observer sur le diagramme de Venn :
{1, 2}
{3, 4}
{1, 2, 3, 4, 5}Tout comme c'est le cas avec les opérateurs arithmétiques, on peut également construire des affectations composées à partir des opérateurs ensemblistes. Cela nous offre donc une autre possibilité pour modifier un ensemble. Étant donné un ensemble A, les deux séquences d'instructions suivantes sont (presque) équivalentes :
2.
3.
4.
5.
6.
7.
# Appel de fonction
A.add(6)
A.remove(4)
# Opération ensembliste
A |= {6}
A -= {4}
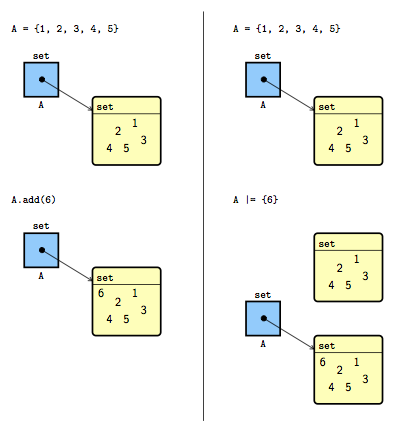
Pourquoi ces opérations ne sont-elles pas complètement équivalentes ? Pour vraiment le comprendre, il faudra attendre le prochain chapitre sur les objets, mais on peut néanmoins déjà comprendre l'intuition grâce à la figure 2 qui montre la situation en mémoire.
Sur la gauche, on peut voir la situation en mémoire avant et après exécution de l'instruction A.add(6). L'ensemble contenu dans la variable A a été modifié et contient un élément supplémentaire.
Sur la droite, on peut voir la situation en mémoire avant et après exécution de l'instruction A |= {6}. La valeur de la variable A a été modifiée et contient un nouvel ensemble, résultat de l'union de l'ensemble A original avec l'ensemble {6}. L'ensemble qui était originellement référencé par la variable A reste en mémoire, mais n'est plus accessible.
I-A-1-c. Ensemble non modifiable▲
Terminons cette section en nous penchant sur l'aspect modifiable des éléments d'un ensemble, mais également de l'ensemble en tant que tel.
La première contrainte importante concernant les éléments d'un ensemble est qu'ils doivent être non modifiables. Voyons cela avec l'exemple suivant qui tente de créer un ensemble contenant des listes :
A = {[0], [1, 2, 3]}Les listes étant modifiables, on ne peut en utiliser comme éléments d'un ensemble et une erreur d'exécution est produite par l'interpréteur :
2.
3.
4.
Traceback (most recent call last):
File "program.py", line 1, in <module>
A = {[0], [1, 2, 3]}
TypeError: unhashable type: 'list'
Et qu'en est-il des ensembles ? Comme on l'a vu précédemment, un ensemble est modifiable puisqu'on peut lui ajouter ou retirer des éléments une fois créé, notamment avec add et remove.
Il est possible de définir un ensemble non modifiable, c'est-à-dire que l'on ne pourra pas le modifier une fois créé. Pour cela, on utilise simplement le type frozenset au lieu du type set. Tout ce que l'on a vu précédemment pour les ensembles, à l'exception des opérations de modification, est également applicable aux frozenset.
L'exemple suivant crée un ensemble non modifiable et tente de lui ajouter un élément :
A = frozenset([1, 2, 3])
A.add(6)Puisque la variable A contient un ensemble non modifiable, une erreur se produit lors de l'exécution :
2.
3.
4.
Traceback (most recent call last):
File "program.py", line 2, in <module>
A.add(6)
AttributeError: 'frozenset' object has no attribute 'add'
Néanmoins, notez que l'instruction A |= {6} s'exécute sans produire d'erreur. Après son exécution, la variable A contiendra un nouvel ensemble, à savoir frozenset({1, 2, 3, 6}). On n'a donc pas modifié l'ensemble originellement présent dans A, mais on lui a affecté un nouvel ensemble non modifiable.
I-B. Dictionnaire▲
Un autre type de données très utilisé est le dictionnaire. Il s'agit d'un ensemble de paires associant une clé et une valeur. Ce type est également appelé tableau associatif dans d'autres langages de programmation.
Dans un même dictionnaire, chaque clé est unique. On peut en fait voir un dictionnaire comme une extension des séquences, où chaque élément est identifié de manière unique, non plus par un indice, mais par une clé. Une clé peut être une donnée de n'importe quel type, pour autant qu'elle soit non modifiable.
I-B-1. Définition d'un dictionnaire▲
On peut créer un dictionnaire en listant toutes ses paires clé-valeur, séparées par des virgules, et en délimitant le tout avec des accolades. L'exemple ci-dessous crée un dictionnaire contenant trois paires stockant les numéros de téléphone internes des employés d'une entreprise :
phone = {'Quentin': 8723, 'Cédric': 2837, 'Jonathan': 4872}Un dictionnaire vide se déclare avec des accolades vides ({}). L'accès aux éléments d'un dictionnaire se fait également avec des crochets, comme pour les séquences, si ce n'est que l'on utilise la clé de l'élément qui nous intéresse comme indice. La plupart des opérations applicables aux séquences le sont également aux dictionnaires, comme le montre l'exemple suivant :
Comme on peut le constater sur le résultat de l'exécution, la variable phone est bien un dictionnaire puisque son type est dict :
2.
3.
4.
5.
6.
7.
8.
{'Jonathan': 4872, 'Quentin': 8723, 'Cédric': 2837}
3
2837
True
<class 'dict'>
Jonathan : 4872
Quentin : 8723
Contrairement aux séquences, où l'opérateur in agit sur ses éléments, il permet, dans un dictionnaire, de tester si une valeur est une clé de ce dernier. La boucle for agit également sur les clés, permettant de les parcourir. On se rend également compte qu'un dictionnaire est modifiable puisqu'on peut notamment appliquer l'opérateur del.
Enfin, un dictionnaire est bel et bien un ensemble, et non pas une séquence. Du coup, ses éléments, qui sont des paires clé-valeur, ne sont pas ordonnés. Il n'y a dès lors aucune garantie que deux parcours de ses clés se fassent toujours dans le même ordre.
On peut également créer un dictionnaire par compréhension, tout comme on peut le faire pour les séquences et les ensembles. Créons, par exemple, un dictionnaire associant à chaque entier impair compris entre kitxmlcodeinlinelatexdvp1finkitxmlcodeinlinelatexdvp et kitxmlcodeinlinelatexdvp10finkitxmlcodeinlinelatexdvp (les clés), son carré (les valeurs) :
squares = {n : n ** 2 for n in range(1,10) if n % 2 != 0}
print(squares)On constate bien que les clés du dictionnaire squares sont les entiers impairs voulus, et que les valeurs associées sont à chaque fois leur carré :
{1: 1, 3: 9, 9: 81, 5: 25, 7: 49}Enfin, on peut également créer un dictionnaire à partir d'une liste de paires clé-valeur, représentées par des tuples. Pour cela, on passe par la fonction dict :
price = dict([('pear', 1.10), ('lemon', 0.85), ('pear', 1.00)])
print(price)Puisqu'un dictionnaire ne peut pas contenir plusieurs fois la même clé, en cas de doublons, seule la dernière présente dans la liste sera retenue. Comme on a deux fois la clé pear dans la liste passée en paramètre à la fonction dict, seule la valeur associée à la dernière sera retenue, à savoir kitxmlcodeinlinelatexdvp1.0finkitxmlcodeinlinelatexdvp. C'est bien ce que l'on observe sur le résultat de l'exécution :
{'lemon': 0.85, 'pear': 1.0}I-B-1-a. Modification d'un dictionnaire▲
Le dictionnaire est un type modifiable, c'est-à-dire que l'on va pouvoir modifier les valeurs des paires clé-valeur qu'il contient, mais également lui ajouter ou retirer de telles paires. Modifier la valeur d'une paire se fait comme avec les listes, c'est-à-dire avec les crochets en précisant la clé de la paire que l'on veut modifier. Ainsi, pour changer le prix des citrons, on écrit l'instruction suivante :
price['lemon'] = 0.90Si la clé que l'on avait spécifiée dans l'instruction précédente n'existait pas dans le dictionnaire, une nouvelle paire clé-valeur aurait été ajoutée. C'est donc ainsi que l'on ajoute un élément à un dictionnaire :
price['apple'] = 1.00
print(price)Cette instruction a donc ajouté une nouvelle paire dont la clé est 'apple' et la valeur est kitxmlcodeinlinelatexdvp1.00finkitxmlcodeinlinelatexdvp, comme on peut le constater sur le résultat de l'exécution :
{'pear': 1.0, 'lemon': 0.9, 'apple': 1.0}Pour supprimer un élément du dictionnaire, comme on l'a précédemment vu, il suffit d'utiliser la fonction del. Par exemple, pour supprimer la paire correspondant aux poires, on écrit :
del(price['pear'])I-B-1-b. Parcours d'un dictionnaire▲
Il existe plusieurs manières de parcourir un dictionnaire. Comme on a vu en début de section, on peut utiliser la boucle for qui va parcourir ses différentes clés. On accède ensuite aux valeurs associées aux clés avec les crochets :
for fruit in price:
print(fruit, price[fruit], sep=' : ')L'exécution de cette boucle affiche le résultat suivant :
apple : 1.0
lemon : 0.9Rappelez-vous bien que l'ordre n'est pas déterminé et peut donc être différent entre deux exécutions, puisqu'un dictionnaire est un ensemble.
On peut récupérer toutes les clés d'un dictionnaire grâce à la fonction keys et tous ses éléments grâce à la fonction items, toutes deux à appliquer sur le dictionnaire duquel on veut extraire les informations. Ces deux fonctions renvoient respectivement des données de type dict_keys et dict_items. Ce sont des séquences que l'on peut transformer en listes avec la fonction list. L'exemple suivant et son résultat illustrent cela :
2.
3.
4.
5.
dict_keys(['apple', 'lemon'])
dict_items([('apple', 1.0), ('lemon', 0.9)])
['apple', 'lemon']
[('apple', 1.0), ('lemon', 0.9)]
Enfin, on peut également directement parcourir les paires d'un dictionnaire en utilisant la fonction items :
for key, value in price.items():
print(key, value, sep=' : ')I-B-1-c. Dictionnaire et tuple nommé▲
Un dictionnaire ressemble à un tuple nommé pour certains points, mais il s'agit bel et bien de deux types de données différents. Voici les différences entre ces deux types :
- un tuple nommé est une séquence et ses éléments sont donc ordonnés, ce qui n'est pas le cas d'un dictionnaire qui est un ensemble de paires ;
- un tuple nommé est non modifiable alors que le dictionnaire l'est ;
- les attributs d'un tuple nommé doivent être des chaines de caractères alors que les clés d'un dictionnaire peuvent être n'importe quelle donnée non modifiable.
I-C. Imbrication de données▲
Les éléments que l'on peut stocker dans les séquences, les ensembles et les dictionnaires peuvent être de n'importe quel type, sauf pour les ensembles et pour les clés des dictionnaires qui doivent être non modifiables. On peut imbriquer une structure de données dans une autre, pour construire des structures plus complexes. On a déjà vu quelques exemples dans les sections précédentes, et on va maintenant analyser cette possibilité dans le détail.
I-C-1. Liste à deux dimensions▲
Commençons avec les listes imbriquées, c'est-à-dire une liste dont les éléments sont eux-mêmes des listes. On va commencer par créer deux listes de nombres entiers, puis utiliser ces deux listes comme éléments d'une troisième liste :
2.
3.
4.
5.
A = [1, 2]
B = [3, 4, 5]
L = [A, B]
print(L)
Lorsqu'on exécute ces instructions, on obtient le résultat suivant qui montre bien que les éléments de la liste L sont des listes :
[[1, 2], [3, 4, 5]]On n'est pas obligé de préalablement créer les listes qui seront imbriquées, et on peut directement écrire :
L = [[1, 2], [3, 4, 5]]La figure 3 montre tout ce qui est créé en mémoire lors de l'exécution de cette instruction. On voit d'abord que la variable L est une référence vers une liste à deux éléments. Le premier élément de cette liste est lui-même une référence vers une autre liste, qui contient trois nombres entiers tandis que le second élément référence une liste à deux éléments.
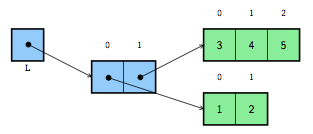
Si on parcourt les éléments de la liste L, et que l'on affiche leur type, on se rend compte directement qu'il s'agit bien de listes comme le montrent l'exemple suivant et le résultat de son exécution :
<class 'list'>
<class 'list'>On peut donc accéder aux deux listes imbriquées avec les notations L[0] et L[1]. Comment ensuite accéder aux éléments de ces listes imbriquées ? Il suffit en fait de faire un accès multiple en rajoutant encore des crochets. Ainsi, la notation L[1][2] permettra d'accéder au troisième élément (celui d'indice kitxmlcodeinlinelatexdvp2finkitxmlcodeinlinelatexdvp) de la deuxième liste imbriquée (celle d'indice kitxmlcodeinlinelatexdvp1finkitxmlcodeinlinelatexdvp), à savoir la valeur kitxmlcodeinlinelatexdvp5finkitxmlcodeinlinelatexdvp.
Lorsque toutes les listes imbriquées ont la même taille, on dit que l'on a créé une liste à deux dimensions. On peut comparer une telle structure aux matrices utilisées en mathématiques. Une telle structure est caractérisée par un nombre de lignes et de colonnes. Analysons l'exemple suivant :
M = [[1, 2, 3], [4, 5, 6]]La variable M contient une référence vers une liste à deux éléments, ces derniers étant tous deux des listes de nombres entiers à trois éléments. On représente en fait la matrice suivante :
kitxmlcodelatexdvpM = \left(\begin{array}{ccc} 1 & 2 & 3 \\ 4 & 5 & 6 \end{array}\right),finkitxmlcodelatexdvpqui possède deux lignes et trois colonnes. On peut obtenir le nombre de lignes avec len(M) et le nombre de colonnes avec len(M[0]), pour autant que la matrice ne soit pas vide. Chaque élément de la liste à deux dimensions est accessible avec la notation M[i][j] où l'indice kitxmlcodeinlinelatexdvpifinkitxmlcodeinlinelatexdvp représente celui de la ligne et l'indice kitxmlcodeinlinelatexdvpjfinkitxmlcodeinlinelatexdvp celui de la colonne.
Pour parcourir tous les éléments d'une liste à deux dimensions, il faudra utiliser deux boucles imbriquées, que ce soit une while ou une for. Voici comment on peut parcourir la liste M avec les deux types de boucles :
Ces boucles vont simplement afficher tous les éléments de la liste à deux dimensions, l'un en dessous de l'autre, en la parcourant ligne par ligne.
I-C-1-a. Liste multidimensionnelle▲
On peut aisément aller plus loin et augmenter la dimension d'une liste. Par exemple, une liste à trois dimensions est simplement une liste de listes de listes. Pour accéder aux valeurs de la liste tridimensionnelle, il faudra dès lors spécifier trois indices. Par exemple, pour la liste suivante :
data = [[[1], [2, 3]], [[4, 5, 6]]]On accède à la valeur kitxmlcodeinlinelatexdvp1finkitxmlcodeinlinelatexdvp avec data[0][0][0] et à la valeur kitxmlcodeinlinelatexdvp6finkitxmlcodeinlinelatexdvp avec data[1][0][2]. De manière générale, on évite toutefois de monter en dimensions, car cela rend les listes plus complexes, notamment pour accéder à leurs éléments et les manipuler. Autant les listes à deux dimensions sont encore assez répandues, celles à trois dimensions sont déjà plus rares et ne parlons même pas des dimensions supérieures.
I-C-1-b. Structure imbriquée▲
Ce que l'on vient de voir avec les listes peut s'appliquer aux autres structures de données que l'on a vues jusqu'à présent, en respectant certaines contraintes.
Tout d'abord, tout ce que l'on peut imbriquer dans une liste, on peut également le faire avec des tuples. On a déjà vu que l'on pouvait imbriquer des listes dans une liste, et on peut également y imbriquer des tuples. On pourrait, par exemple, stocker une liste de coordonnées dans le plan comme suit :
coords = [(0,0), (7,-2), (4,5), (-3,-9)]On peut également imbriquer des ensembles dans une liste. Par exemple, on pourrait vouloir stocker une liste de lunches, par ordre de préférence :
2.
3.
4.
5.
6.
lunches = [
{'apple', 'banana', 'grape'},
{'yogurt', 'cereals'},
{'bread', 'cheese', 'ham'},
{'sausage'}
]
Remarquez que la liste a été déclarée sur plusieurs lignes, afin de la rendre plus lisible. Une telle notation est autorisée et même recommandée lorsque vous déclarez des structures complexes.
Enfin, il n'y a aucun problème à stocker des dictionnaires dans une liste. L'exemple suivant montre comment on pourrait stocker ses contacts par ordre alphabétique des prénoms :
2.
3.
4.
5.
contacts = [
{'firstname': 'Alexis', 'lastname': 'King'},
{'firstname': 'Brice', 'lastname': 'Monster'},
{'firstname': 'Sébastien', 'lastname': 'Adams'}
]
Concernant les ensembles, on a vu que l'on ne pouvait y stocker que des valeurs non modifiables. On ne va donc pas pouvoir y imbriquer des listes, des ensembles (on peut néanmoins imbriquer des ensembles non modifiables, obtenus avec frozenset, dans des ensembles) ou des dictionnaires. On peut, par exemple, imbriquer des tuples dans un ensemble. Voici, par exemple, un ensemble reprenant, pour différents athlètes, les résultats réalisés en mètres pour trois lancers de javelot consécutifs :
2.
3.
4.
5.
results = {
(90.73, 89.23, 90.12),
(87.23, 90.11, 88.12),
(90.88, 88.61, 89.91)
}
La même restriction s'applique aux clés d'un dictionnaire qui doivent donc être des valeurs non modifiables. On peut, par exemple, utiliser un tuple comme clé d'un dictionnaire. L'exemple suivant associe une personne à une série de coordonnées dans le plan :
2.
3.
4.
5.
6.
config = {
(0, 0): 'Arnaud',
(2, 1): 'Louis',
(-1, 3): 'Marie',
(3, -1): 'Dan'
}
Si on désire pouvoir placer plusieurs personnes à une même coordonnée, et se rappelant que les clés d'un dictionnaire doivent être uniques, on va devoir imbriquer une liste dans le dictionnaire :
2.
3.
4.
5.
6.
config = {
(0, 0): ['Arnaud', 'Pierre'],
(2, 1): ['Louis'],
(-1, 3): ['Marie', 'Éric', 'Tom'],
(3, -1): ['Dan']
}
Comme on le verra à la section suivante, on va aussi pouvoir imbriquer des dictionnaires ensemble afin de construire des structures complexes permettant de représenter de véritables bases de données.
I-C-1-c. Copie▲
Terminons cette section en s'intéressant à la copie de structures de données, qui peut parfois se révéler délicate sachant qu'une variable ne contient pas toute la structure de données, mais uniquement une référence vers l'emplacement en mémoire où elle est stockée. En effet, comme on l'a vu à la section 5.1, lorsqu'on affecte à une variable une autre variable qui contient une référence vers une liste, on crée un alias. Les deux variables contiennent une référence vers la même zone mémoire, contenant la liste, et permettent donc d'agir sur la même liste. Revoyons cela avec l'exemple suivant :
2.
3.
4.
5.
L = [1, 2, 3]
A = L
A[0] = 42
print(L)
Alors que l'on pourrait croire, de prime abord, que la variable A contient une copie de la liste référencée par la variable L, ce n'est effectivement pas le cas. Les variables A et L sont des alias vers la même liste, qui n'existe donc qu'une seule fois en mémoire. On peut le constater avec le résultat de l'exécution :
[42, 2, 3]Pour faire une réelle copie, il faut passer par la fonction prédéfinie list qui va, elle, créer une nouvelle liste en mémoire, avec le même contenu que celle passée en paramètre. Pour faire une véritable copie, l'exemple précédent doit donc se réécrire comme suit :
2.
3.
4.
5.
L = [1, 2, 3]
A = list(L)
A[0] = 42
print(L)
Cette fois-ci, le code affiche bien ce que l'on attend :
[1, 2, 3]Ce comportement est exactement le même pour toutes les autres structures de données que l'on a vues jusqu'à présent. Il ne pose évidemment aucun souci pour les structures de données non modifiables comme les chaines de caractères, les tuples ou les intervalles.
Pour les autres structures, il faudra à chaque fois passer par la fonction prédéfinie correspondant à la structure de données pour en faire une copie, à savoir list, set et dict.
I-C-1-c-i. Module copy▲
La méthode de copie que l'on vient de voir permet en réalité de faire une copie en surface. Pour comprendre cette notion, attardons-nous un moment sur l'exemple suivant :
2.
3.
4.
5.
L = [[1, 2], [3, 4, 5]]
A = list(L)
A[1][0] = 42
print(L)
Bien que l'on ait fait une copie de la liste référencée par la variable L dans la variable A, après avoir modifié cette copie à partir de la variable A, on observe le résultat suivant après exécution :
[[1, 2], [42, 4, 5]]Pour comprendre ce qui s'est passé, il faut examiner la situation en mémoire, après exécution des deux premières instructions, illustrée à la figure 4. On y voit donc que la liste directement référencée par la variable L a bel et bien été copiée, cette copie étant référencée par la variable A. La subtilité, c'est que les listes qui sont référencées par ces deux listes sont, elles, uniques et c'est dans ces listes que se trouvent les valeurs de la liste à deux dimensions.
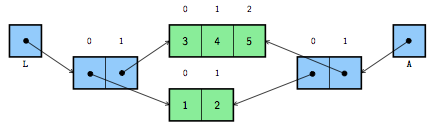
Si on le souhaite, il est également possible de faire une copie en profondeur, c'est-à-dire que tous les niveaux de la structure de données seront copiés, même les imbriquées.
Pour cela, on va faire appel au module copy qui propose deux fonctions :
- copy permet de faire une copie en surface ;
- deepcopy permet de faire une copie en profondeur.
L'exemple précédent avec une copie en profondeur se réécrit simplement comme suit, sans oublier d'importer le module copy évidemment :
2.
3.
4.
5.
6.
7.
import copy
L = [[1, 2], [3, 4, 5]]
A = copy.deepcopy(L)
A[1][0] = 42
print(L)
Le résultat de l'exécution montre que l'on a bel et bien une copie intégrale de la liste L :
[[1, 2], [3, 4, 5]]La copie en profondeur copie donc intégralement toutes les structures imbriquées. Cela a deux conséquences immédiates : la copie prendra plus de temps et la consommation mémoire globale du programme sera plus grande. Lorsqu'on fait une copie, il est dès lors important de se poser la question de savoir ce que l'on veut en faire. Si c'est uniquement pour la consulter, un simple alias suffira, et si c'est pour la modifier, selon la profondeur des modifications envisagées, le choix se portera vers une copie en surface ou en profondeur.
I-D. Base de données▲
On peut utiliser des dictionnaires pour construire des simples bases de données. Une base de données est une collection de données organisées selon un format choisi. La gestion de ces données est confiée à un système de gestion de bases de données (SGBD), un ensemble de logiciels permettant notamment d'interroger la base de données pour en extraire des informations et de gérer le stockage physique de ces données.
I-D-1. Format JSON▲
Le format JSON (acronyme de JavaScript Object Notation, ce format provient du monde JavaScript) est utilisé pour représenter des objets. C'est un format qui dérive de la notation des objets du langage JavaScript. Il est utilisé pour représenter de l'information structurée et, comme vous pourrez le constater, ressemble fort aux dictionnaires Python.
Un document JSON est un ensemble de paires constituées d'une étiquette et d'une valeur ou d'une liste de valeurs. On sépare les paires par des virgules, le tout entre accolades. Pour les listes de valeurs, on sépare les valeurs par des virgules, le tout entre crochets. Enfin, une valeur peut elle-même être un document JSON et les étiquettes doivent être écrites entre guillemets doubles (vous pouvez vérifier la validité d'un document JSON en ligne, à l'adresse suivante : http://jsonlint.com/).
Voici un exemple de document JSON qui représente un carnet de contacts, reprenant leurs nom, prénom et numéro de téléphone :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
{
"name": "Carnet de contacts de Sébastien Combéfis",
"contacts": [
{
"firstname": "Cédric",
"lastname": "Marchand",
"phone": 2837
},
{
"firstname": "Jonathan",
"lastname": "Verlant-Chenet",
"phone": 4872
},
{
"firstname": "Quentin",
"lastname": "Lurkin",
"phone": 8723
}
]
}
Ce document JSON contient, à la base, deux paires dont les étiquettes sont name et contacts. La valeur de la première paire est une chaine de caractères et celle de la seconde paire est une liste de documents JSON. Elle en contient trois identiques contenant chacun trois étiquettes (firstname, lastname et phone) dont les valeurs sont des chaines de caractères pour les deux premières et un nombre entier pour la troisième.
I-D-1-a. Base de données orientée document▲
Les documents JSON sont utilisés pour construire des bases de données orientées document. Dans de telles bases de données, les éléments stockés peuvent être des documents JSON. Un tel type de base de données supporte essentiellement quatre opérations que l'on résume avec l'acronyme CRUD (Create, Read, Update, and Delete) :
- création et ajout d'un nouveau document ;
- lecture et récupération d'un document par une recherche ;
- mise à jour d'un document existant par modification, ajout ou suppression de paires ;
- suppression d'un document existant.
Ces quatre opérations sont nécessaires pour avoir un système complet. Si on considère l'implémentation d'une base de données orientée documents à l'aide de Python, en utilisant les dictionnaires pour stocker les documents JSON, il est assez simple d'implémenter ces quatre opérations à l'aide de celles utilisables sur les dictionnaires.
I-D-1-b. Sérialisation et désérialisation▲
Un document JSON peut toujours être transformé en un dictionnaire Python ; cette opération s'appelle la désérialisation. L'opération inverse, appelée sérialisation, tente de convertir un dictionnaire Python en un document JSON. Cette seconde opération n'est pas toujours possible, les dictionnaires Python étant plus riches que ce qui est permis en JSON. On relève notamment les différences majeures suivantes :
- les étiquettes des paires d'un document JSON doivent être des chaines de caractères alors qu'elles peuvent être n'importe quelle donnée non modifiable dans un dictionnaire Python ;
- les types de données autorisés pour les valeurs des paires d'un document JSON sont limités aux chaines de caractères, booléens, nombres entiers et flottants, listes et documents JSON imbriqués alors qu'il y a beaucoup plus de types autorisés dans un dictionnaire Python.
Les deux opérations de sérialisation et de désérialisation peuvent être faites à partir de fonctions disponibles dans le module json. La fonction dumps correspond à la sérialisation et la fonction loads désérialise un document JSON.
Le premier exemple construit un dictionnaire Python et le sérialise en un document JSON qui est ensuite affiché. Le résultat renvoyé par la fonction dumps est de type chaine de caractères :
2.
3.
4.
5.
6.
7.
8.
9.
import json
bb = {'seasons': 5, 'genre': ['crime drama', 'thriller']}
skins = {'seasons': 7, 'genre': ['teen drama', 'comedy drama']}
tvshows = {'Breaking Bad': bb, 'Skins': skins}
document = json.dumps(tvshows, indent=4)
print(type(document))
print(document)
Le paramètre nommé indent de la fonction dumps permet d'obtenir un joli formatage du document JSON, comme on le voit sur le résultat de l'exécution :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
<class 'str'>
{
"Breaking Bad": {
"genre": [
"crime drama",
"thriller"
],
"seasons": 5
},
"Skins": {
"genre": [
"teen drama",
"comedy drama"
],
"seasons": 7
}
}
Voyons maintenant l'opération inverse, à savoir la création d'un dictionnaire Python à partir d'une chaine de caractères contenant un document JSON. On utilise donc pour cela la fonction loads comme le montre l'exemple suivant :
2.
3.
4.
5.
6.
7.
import json
document = '{"Belgium":{"capital":"Brussels","languages":["french","dutch","german"]},"China":{"capital":"Beijing","languages":["mandarin chinese"]}}'
countries = json.loads(document)
print(type(countries))
print(countries['China'])
La variable countries, qui stocke le résultat renvoyé par la fonction loads, contient bien un dictionnaire comme on peut le constater sur le résultat de l'exécution :
<class 'dict'>
{'languages': ['mandarin chinese'], 'capital': 'Beijing'}Les deux fonctions dumps et loads provoquent une erreur lors de l'exécution lorsqu'un problème de format de données est présent. La sérialisation échouera si le dictionnaire Python passé en paramètre comporte des éléments interdits par le format JSON. La désérialisation échouera si la chaîne de caractères passée en paramètre ne représente pas un document JSON valide.