


V. Séquence▲
Jusqu'à présent, on a vu comment manipuler des nombres, des booléens et des chaines de caractères. Dans ce chapitre, on va découvrir les séquences, un type de données permettant de représenter une suite ordonnée de données. En réalité, les chaines de caractères sont un exemple de séquence ; il s'agit en effet d'une suite de caractères rangés dans un ordre bien déterminé. Ce chapitre présente trois types de séquences de base existant en Python : les listes, les tuples et les intervalles. Il présente également deux structures de données couramment utilisées. Enfin, il termine avec le concept d'itérateur qui permet de parcourir facilement les éléments d'une collection d'éléments.
V-A. Liste▲
Une liste est un type de données qui permet de contenir une liste de valeurs. La manière la plus simple d'en définir une consiste à en préciser toutes les valeurs, dans l'ordre désiré et séparées par des virgules, le tout délimité par des crochets. Une liste vide se déclare simplement avec deux crochets ([]). Une liste contenant, dans l'ordre, les entiers de kitxmlcodeinlinelatexdvp1finkitxmlcodeinlinelatexdvp à kitxmlcodeinlinelatexdvp5finkitxmlcodeinlinelatexdvp, se déclare comme suit :
numbers = [1, 2, 3, 4, 5]
La variable numbers contient donc une liste de cinq éléments, chacun étant un nombre entier. La taille d'une liste est le nombre d'éléments qu'elle contient; on peut l'obtenir grâce à la fonction len. On peut afficher une liste avec la fonction print et obtenir son type avec la fonction type :
2.
print(numbers)
print(type(numbers))
L'exécution de ces deux instructions dévoile que la variable numbers contient bien une liste de cinq éléments (les nombres entiers de kitxmlcodeinlinelatexdvp1finkitxmlcodeinlinelatexdvp à kitxmlcodeinlinelatexdvp5finkitxmlcodeinlinelatexdvp) et qu'elle est de type list :
[1, 2, 3, 4, 5]Chaque élément de la liste possède un indice qui permet d'y accéder, c'est-à-dire d'obtenir sa valeur. Le premier élément d'une liste est celui d'indice kitxmlcodeinlinelatexdvp0finkitxmlcodeinlinelatexdvp, le deuxième celui d'indice kitxmlcodeinlinelatexdvp1finkitxmlcodeinlinelatexdvp…
Pour obtenir un élément de la liste, il suffit de faire suivre le nom de la variable de l'indice désiré entre crochets. L'instruction suivante affiche l'élément à l'indice kitxmlcodeinlinelatexdvp0finkitxmlcodeinlinelatexdvp de la liste stockée dans la variable numbers, c'est-à-dire son premier élément :
print(numbers[0])
La figure 1 représente visuellement la liste numbers. Vous y voyez clairement qu'il s'agit d'une séquence ordonnée d'éléments, chacun ayant un indice. Le premier indice est kitxmlcodeinlinelatexdvp0finkitxmlcodeinlinelatexdvp et le dernier indice est kitxmlcodeinlinelatexdvpn - 1finkitxmlcodeinlinelatexdvp, si kitxmlcodeinlinelatexdvpnfinkitxmlcodeinlinelatexdvp représente la taille de la liste.
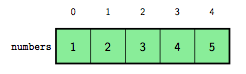
À l'aide de la fonction len et avec une boucle while, on peut parcourir une liste, c'est-à-dire passer en revue chacun de ses éléments pour, par exemple, les afficher. Pour cela, il suffit d'utiliser une variable comme valeur d'indice, initialisée à kitxmlcodeinlinelatexdvp0finkitxmlcodeinlinelatexdvp et incrémentée de kitxmlcodeinlinelatexdvp1finkitxmlcodeinlinelatexdvp jusqu'à atteindre kitxmlcodeinlinelatexdvpn - 1finkitxmlcodeinlinelatexdvp, si kitxmlcodeinlinelatexdvpnfinkitxmlcodeinlinelatexdvp représente la taille de la liste.
L'exemple suivant parcourt tous les éléments de la liste numbers à l'aide d'une boucle while, pour les afficher l'un après l'autre :
2.
3.
4.
i = 0
while i < len(numbers):
print(numbers[i])
i += 1
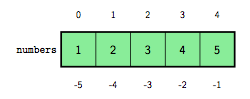
En Python, on peut également utiliser un nombre négatif comme indice, pour accéder aux éléments d'une liste à partir de la fin. Ainsi, l'indice kitxmlcodeinlinelatexdvp-1finkitxmlcodeinlinelatexdvp correspond au dernier élément de la liste, l'indice kitxmlcodeinlinelatexdvp-2finkitxmlcodeinlinelatexdvp à l'avant-dernier… comme l'illustre la figure 2. Pour parcourir tous les éléments d'une liste à l'envers, on peut écrire la boucle suivante :
2.
3.
4.
i = -1
while i >= -len(numbers):
print(numbers[i])
i -= 1
Enfin, les listes sont hétérogènes, c'est-à-dire que leurs éléments peuvent sans soucis être de types différents. Par exemple, on pourrait représenter une adresse par une liste contenant la rue, le numéro, le code postal, la ville et le pays. Voici comment on pourrait stocker l'adresse du cabinet du Premier ministre belge :
address = ["Rue de la Loi", 16, 1000, "Bruxelles", "Belgique"]
V-A-1. Modification d'une liste▲
Une fois créée, une liste peut être modifiée en changeant la valeur de ses éléments ou en en supprimant. On peut simplement voir une liste comme plusieurs variables, chacune étant accédée par son indice. Dès lors, on utilise simplement l'opérateur d'affectation pour modifier un élément d'une liste. Par exemple, pour modifier son premier élément, il suffit d'écrire :
numbers[0] = 15
Pour supprimer un élément d'une liste, il faut utiliser la fonction prédéfinie del, en lui indiquant l'élément à supprimer. La fonction s'occupera de décaler tous les autres éléments, de sorte qu'il n'y ait pas de « trous » dans la liste. Voyons cela avec l'exemple suivant :
2.
3.
print(numbers)
del(numbers[2])
print(numbers)
On supprime donc l'élément d'indice kitxmlcodeinlinelatexdvp2finkitxmlcodeinlinelatexdvp, à savoir le troisième élément de la liste. Le résultat de l'exécution de ces trois instructions montre bien que l'élément kitxmlcodeinlinelatexdvp3finkitxmlcodeinlinelatexdvp a été retiré et que les autres éléments ont été décalés :
[15, 2, 3, 4, 5]
[15, 2, 4, 5]V-A-1-a. Slicing▲
Une autre opération que l'on peut faire sur les listes est le slicing. Elle consiste à extraire une sous-liste à partir d'une liste. On utilise de nouveau les crochets, mais en spécifiant deux indices, à savoir celui du début (inclus) et celui de la fin (non inclus) de la sous-liste à extraire, séparés par un deux-points (:).
Par exemple, pour extraire la sous-liste constituée des deuxième et troisième éléments d'une liste, il faut démarrer à l'indice kitxmlcodeinlinelatexdvp1finkitxmlcodeinlinelatexdvp et aller jusque l'indice kitxmlcodeinlinelatexdvp3finkitxmlcodeinlinelatexdvp (c'est-à-dire l'indice kitxmlcodeinlinelatexdvp4finkitxmlcodeinlinelatexdvp non inclus). L'exemple ci-dessous affiche donc [2, 3, 4] lors de son exécution :
2.
numbers = [1, 2, 3, 4, 5]
print(numbers[1:4])
Si on ne précise pas de premier indice, la sous-liste commencera au début de la liste (comme si on avait mis kitxmlcodeinlinelatexdvp0finkitxmlcodeinlinelatexdvp). De même, ne pas indiquer le second indice fera terminer la sous-liste au bout de la liste (comme si on avait mis la taille de la liste). L'exemple suivant affiche [1, 2, 3] et [4, 5], à savoir les trois premiers éléments et les deux derniers :
2.
print(numbers[:3])
print(numbers[3:])
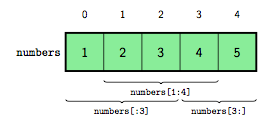
La figure 3 montre les sous-listes correspondant à plusieurs opérations de slicing effectuées sur une liste. On y voit clairement que le premier indice renseigné est inclus alors que le second est exclu.
V-A-1-a-i. Insertion d'éléments▲
Le slicing permet également d'insérer des éléments dans une liste. Pour cela, il suffit d'affecter une nouvelle valeur à une sous-liste vide. La valeur à affecter doit être une liste. Analysons l'exemple suivant :
2.
3.
numbers = [1, 2, 3, 4, 5]
numbers[2:2] = [0]
print(numbers)
La sous-liste [2:2] ne contient aucun élément. La deuxième instruction remplace cette sous-liste vide par la liste [0], c'est-à-dire qu'on insère la valeur kitxmlcodeinlinelatexdvp0finkitxmlcodeinlinelatexdvp comme nouvel élément d'indice kitxmlcodeinlinelatexdvp2finkitxmlcodeinlinelatexdvp dans la liste numbers. Les autres éléments de la liste sont automatiquement décalés. L'exécution du programme affiche :
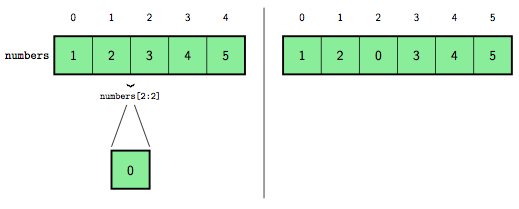
[1, 2, 0, 3, 4, 5]La figure 4 illustre comment cette insertion se déroule. On y voit à gauche la sous-liste ainsi que la nouvelle liste qui va la remplacer et à droite le résultat après affectation de la nouvelle valeur à la sous-liste.
Voici trois autres exemples qui montrent comment insérer un élément au début et à la fin d'une liste, et comment en modifier un élément quelconque :
2.
3.
4.
5.
6.
7.
8.
numbers[0:0] = [0]
print(numbers)
numbers[6:6] = [6]
print(numbers)
numbers[3:4] = [42]
print(numbers)
La première instruction remplace la sous-liste commençant à l'indice kitxmlcodeinlinelatexdvp0finkitxmlcodeinlinelatexdvp et se terminant à l'indice kitxmlcodeinlinelatexdvp0finkitxmlcodeinlinelatexdvp (non inclus), par la sous-liste [0]; c'est-à-dire que l'élément kitxmlcodeinlinelatexdvp0finkitxmlcodeinlinelatexdvp est inséré en début de liste. La troisième instruction, quant à elle, insère l'élément kitxmlcodeinlinelatexdvp6finkitxmlcodeinlinelatexdvp en fin de liste. Enfin, la cinquième instruction remplace l'élément d'indice kitxmlcodeinlinelatexdvp3finkitxmlcodeinlinelatexdvp par kitxmlcodeinlinelatexdvp42finkitxmlcodeinlinelatexdvp. On aurait évidemment pu simplement écrire numbers[3] = 42. L'exécution de ces instructions affiche donc :
[0, 1, 2, 3, 4, 5]
[0, 1, 2, 3, 4, 5, 6]
[0, 1, 2, 42, 4, 5, 6]Notez que l'on peut simplement utiliser numbers[:0] pour insérer un élément au début d'une liste et numbers[len(numbers):] pour insérer un élément à sa fin. En utilisant le slicing, on peut également remplacer ou insérer plusieurs éléments en une fois, étant donné qu'on remplace en fait une sous-liste par une nouvelle liste. Voici, par exemple, comment remplacer les quatre derniers éléments d'une liste par deux éléments :
2.
numbers[3:7] = [3, 4]
print(numbers)
Une fois la première instruction exécutée, la liste contiendra alors cinq éléments au lieu de sept. L'exécution des deux instructions affiche :
[0, 1, 2, 3, 4]Les trois premiers éléments de la liste ont été conservés et la sous-liste des quatre derniers éléments a été remplacée par la liste [3, 4].
V-A-1-a-ii. Suppression d'éléments▲
On peut supprimer plusieurs éléments d'une liste en combinant la fonction del avec l'opérateur de slicing. Voici un exemple où l'on supprime tous les éléments de la liste, sauf le premier et le dernier :
2.
3.
numbers = [1, 2, 3, 4, 5]
del(numbers[1:4])
print(numbers)
Le résultat de l'exécution de ces trois instructions montre bien que les trois éléments centraux de la liste ont été supprimés :
[1, 5]La fonction del permet en fait de supprimer une variable de la mémoire. L'exemple suivant provoque une erreur d'exécution, car on tente d'afficher une variable qui n'existe plus, puisqu'elle a été supprimée :
2.
3.
a = 3
del(a)
print(a)
Traceback (most recent call last):
File "program.py", line 3, in <module>
print(a)
NameError: name 'a' is not definedV-A-1-b. Concaténation et répétition▲
Il est possible de créer une nouvelle liste en concaténant deux listes existantes. On utilise pour cela l'opérateur de concaténation (+) comme pour les chaines de caractères. L'exemple suivant crée une nouvelle liste en en concaténant deux existantes :
2.
3.
a = [1, 2, 3]
b = [4, 5]
numbers = a + b
On peut également construire une liste en répétant plusieurs fois une liste, c'est-à-dire la concaténer plusieurs fois d'affilée. On utilise pour cela l'opérateur de copie (*), comme dans l'exemple suivant :
2.
a = [1, 2] * 4
print(a)
L'effet de l'opérateur de copie est que la liste [1, 2] est copiée quatre fois, ces copies étant ensuite concaténées pour créer une nouvelle liste. L'exécution de ces deux instructions affiche donc :
[1, 2, 1, 2, 1, 2, 1, 2]V-A-1-c. Appartenance▲
On doit souvent tester si un élément donné appartient à une liste ou non, c'est-à-dire si cet élément fait partie de ceux de la liste. Une solution immédiate à ce problème consiste à utiliser une boucle pour parcourir les éléments de la liste et rechercher celui qu'on veut. On pourrait, par exemple, définir une fonction contains qui fait ce travail :
2.
3.
4.
5.
6.
7.
def contains(data, element):
i = 0
while i < len(data):
if data[i] == element:
return True
i += 1
return False
La boucle compare chaque élément de la liste (data) avec la valeur recherchée (element). Si on l'a trouvée, on quitte immédiatement la fonction en renvoyant la valeur True. Sinon, on finit par atteindre la fin du corps de la fonction et on renvoie False. Mais Python propose en fait un opérateur d'appartenance (in) qui permet de directement tester si un élément fait partie d'une liste ou non. Les deux instructions suivantes sont équivalentes et affichent toutes les deux True :
2.
print(contains(a, 4))
print(4 in a)
On peut également tester si un élément ne fait pas partie d'une liste en utilisant not in. Les deux instructions suivantes sont équivalentes et affichent toutes les deux False :
2.
print(not contains(a, 2))
print(2 not in a)
V-A-1-d. Copie▲
Si on souhaite faire une copie d'une liste, on ne peut pas s'y prendre n'importe comment. Voyons l'exemple suivant :
2.
3.
4.
5.
6.
a = [1, 2, 3]
b = a
a[0] = 42
print(a)
print(b)
La première instruction crée une liste de trois éléments et la stocke dans la variable a. Vient ensuite la deuxième instruction dont on pourrait penser qu'elle fait une copie de la liste stockée dans a pour la stocker dans b. On modifie ensuite le premier élément de la liste a et on affiche les deux listes. Voici le résultat de l'exécution de ces instructions :
[42, 2, 3]
[42, 2, 3]On voit que les listes a et b sont toutes les deux modifiées, car il n'y a en fait pas eu de copie de la liste. Les variables a et b permettent d'accéder à la même liste en mémoire, comme l'illustre la figure 5. Une variable contient en fait une référence vers la zone mémoire où se trouve stockée la valeur qu'elle représente, et pas la valeur directement. Ce sont ces adresses mémoires qui sont pareilles dans les variables a et b.
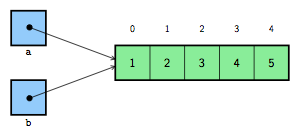
Pour réaliser une copie d'une liste, on peut utiliser le slicing. En effet, pour rappel, le slicing extrait une nouvelle liste correspondant à une sous-liste. Dès lors, pour faire une copie d'une liste existante, il suffit de faire un slicing qui reprend simplement toute la liste. On spécifie pour cela les bornes kitxmlcodeinlinelatexdvp0finkitxmlcodeinlinelatexdvp et la longueur de la liste, ou juste rien. Analysons l'exemple suivant :
2.
3.
4.
5.
6.
7.
8.
9.
a = [1, 2, 3]
b = a[0:len(a)]
c = b[:]
a[0] = -1
b[0] = -2
print(a)
print(b)
print(c)
On commence par créer une copie de la liste a que l'on stocke dans la variable b. On fait ensuite une copie de la liste b que l'on stocke dans la variable c. On modifie ensuite les listes a et b pour enfin afficher les valeurs des trois listes. Au vu du résultat de l'exécution, on peut confirmer qu'on a bien fait des copies des listes :
[-1, 2, 3]
[-2, 2, 3]
[1, 2, 3]V-A-1-e. Comparaison▲
Enfin, un dernier type d'opération que l'on peut vouloir faire entre deux listes consiste à les comparer. Pour tester si deux listes sont identiques, il suffit d'utiliser l'opérateur d'égalité (==). Deux listes sont égales si elles possèdent le même nombre d'éléments et que ceux situés aux mêmes indices sont égaux.
On peut également comparer deux listes en utilisant les opérateurs >, <, >= et <=. Dans ce cas, les listes sont comparées en suivant l'ordre lexicographique. Les premiers éléments de chaque liste sont d'abord comparés entre eux. Si celui de la première liste est plus petit (resp. plus grand) que celui de la seconde liste, alors la première liste est plus petite (resp. plus grande) que la seconde. Si les premiers éléments sont égaux, alors la comparaison continue avec les deuxièmes éléments…
L'exemple suivant montre plusieurs exemples de comparaisons entre deux listes :
2.
3.
4.
5.
6.
7.
8.
a = [1, 2, 3]
b = [1, 2]
c = b + [3]
print(a == b) # Affiche False
print(a != c) # Affiche False
print(a > b) # Affiche True, car [1, 2, 3] > [1, 2]
print(a > [1, 2, 4]) # Affiche False, car [1, 2, 3] < [1, 2, 4]
Comme vous pouvez le constater avec la troisième comparaison faite, si tous les éléments de deux listes sont égaux mais qu'une des deux listes possède moins d'éléments que l'autre, alors elle est d'office plus petite que l'autre liste.
V-B. Tuple▲
Un tuple est une séquence non modifiable d'éléments. Tout comme les listes, un tuple peut être homogène ou hétérogène. Pour en déclarer un, il suffit de séparer ses éléments avec des virgules. Si on veut créer un tuple avec un seul élément, il suffit de placer une virgule derrière l'élément. Enfin, si on souhaite, on peut entourer les éléments du tuple de parenthèses. Voici plusieurs déclarations de tuples :
2.
3.
4.
5.
6.
7.
8.
# tuple vide
a = ()
# tuple contenant un seul élément
b = 1,
c = (1,)
# tuple contenant trois éléments
d = 1, 2, 3
e = (1, 2, 3)
On peut choisir de délimiter ou non les valeurs d'un tuple par des parenthèses. Il y a néanmoins des situations où celles-ci sont obligatoires, à savoir lorsqu'on veut un tuple vide ou lorsqu'il y a une possible ambiguïté. Définissons par exemple une fonction sum qui fait la somme des éléments d'un tuple d'entiers :
Comme vous pouvez le constater, tout ce qu'on a vu à propos des listes s'applique également aux tuples, à l'exception des opérations de modification, évidemment. Supposons que l'on souhaite appeler la fonction sum avec le tuple (1, 2, 3), on pourrait écrire :
r = sum(1, 2, 3)
On se retrouve malheureusement avec l'erreur d'exécution suivante :
Traceback (most recent call last):
File "program.py", line 9, in <module>
r = sum(1, 2, 3)
TypeError: sum() takes 1 positional argument but 3 were givenCe qui s'est passé est que l'interpréteur Python pense qu'on tente d'appeler la fonction en lui fournissant trois paramètres, alors qu'elle n'en accepte qu'un seul. L'appel correct s'écrit donc :
r = sum((1, 2, 3))
Une autre solution, qui ne forcerait pas l'utilisation des parenthèses consiste à passer par une variable intermédiaire :
2.
t = 1, 2, 3
r = sum(t)
Construire un tuple à partir de plusieurs valeurs, comme on l'a fait dans la première instruction, est une opération appelée emballage. On combine des valeurs pour former un tuple, référencé par une seule variable grâce à laquelle on pourra accéder aux valeurs combinées à l'aide de leur indice dans le tuple.
V-B-1. Fonction qui renvoie plusieurs valeurs▲
L'un des intérêts du tuple est qu'il permet de définir des fonctions qui renvoient plusieurs valeurs. Il suffit en fait de renvoyer un tuple. Définissons une fonction qui cherche si un élément donné se trouve ou non dans une liste. Si c'est le cas, elle renvoie True ainsi que le plus petit indice où se trouve l'élément. Sinon, elle renvoie False et la valeur spéciale None comme indice, indiquant une absence de valeur :
2.
3.
4.
5.
6.
7.
def find(data, element):
i = 0
while i < len(data):
if data[i] == element:
return True, i
i += 1
return False, None
Les deux instructions return procèdent à un emballage d'une valeur booléenne et d'un nombre entier (ou None) pour former un tuple qui est renvoyé. Prenons par exemple les deux appels suivants :
2.
3.
4.
values = [1, 2, 3, 4]
print(find(values, 2))
print(find(values, 6))
L'exécution de ces instructions produit le résultat suivant indiquant que l'élément kitxmlcodeinlinelatexdvp2finkitxmlcodeinlinelatexdvp a été trouvé dans la liste à l'indice kitxmlcodeinlinelatexdvp1finkitxmlcodeinlinelatexdvp, et que l'élément kitxmlcodeinlinelatexdvp6finkitxmlcodeinlinelatexdvp n'a pas été trouvé dans la liste :
(True, 1)
(False, None)Vous pourriez vous demander, légitimement, pourquoi on ne s'est pas contenté de renvoyer False dans le cas où l'élément recherché n'est pas dans la liste. On aurait pu, mais ce n'est pas une bonne pratique de renvoyer différents types de valeurs ; c'est même parfois impossible.
Dans l'exemple précédent, tout ce qu'on fait avec la valeur de retour, c'est l'afficher avec la fonction print. Cela ne pose donc aucun problème d'avoir deux types de données différents en valeur de retour. De même, on pourrait stocker la valeur de retour de la fonction dans une variable sans que cela ne pose de soucis :
result = find(values, 2)
On a précédemment vu qu'on pouvait construire un tuple à partir d'éléments simples en faisant un emballage. Il est également possible de faire l'opération inverse, appelée déballage, c'est-à-dire affecter chaque élément d'un tuple à une variable différente :
found, index = find(values, 2)
Dans ce cas, il n'est plus possible pour la fonction find de renvoyer tantôt un tuple à deux éléments, tantôt un seul booléen, sans quoi une erreur d'exécution se produira dans certains cas.
V-B-1-a. Opérateur de déballage▲
On vient de voir qu'on pouvait déballer un tuple lors d'une affectation, en ayant à gauche de l'opérateur d'affectation un tuple de variables avec autant d'éléments qu'il y en a dans le tuple à sa droite :
2.
t = 1, 2, 3 # emballage
a, b, c = t # déballage
On peut également déballer un tuple dans les paramètres d'une fonction lors d'un appel, avec l'opérateur de déballage (*). Voici une fonction qui renvoie la plus grande valeur entre trois entiers donnés :
2.
3.
4.
5.
6.
def max(a, b, c):
if a > b and a > c:
return a
elif b > c:
return b
return c
Si on a un tuple contenant trois nombres entiers et qu'on souhaite appeler cette fonction avec les trois nombres du tuple, il faut utiliser l'opérateur de déballage et donc écrire :
2.
t = 1, 2, 3
result = max(*t)
V-B-1-a-i. Affectation multiple▲
Les propriétés d'emballage et de déballage des tuples permettent de modifier la valeur de plusieurs variables en même temps, avec des valeurs différentes. C'est ce qu'on appelle une affectation multiple. On peut par exemple écrire :
barcode, name, price = 5449000000996, "Coca-Cola 33cl", 0.70
L'affectation des trois variables se déroule en même temps. Cette caractéristique permet d'échange les valeurs de deux variables très facilement, grâce à l'instruction suivante :
x, y = y, x
V-B-1-b. Tuple nommé▲
Pour accéder à un élément d'un tuple, il faut utiliser son indice. Dans le cas de tuples hétérogènes, ce n'est pas toujours très intuitif. Reprenons l'exemple précédent d'un tuple qui représente un article d'un magasin :
item = 5449000000996, "Coca-Cola 33cl", 0.70
Pour accéder au code-barres, il faut écrire item[0], pour accéder à la description de l'article, on utilise item[1] et enfin item[2] permet d'avoir le prix de l'article.
Pour rendre plus explicite qu'on a un tuple hétérogène dont chaque élément représente un attribut différent, on peut utiliser un tuple nommé. Pour cela, il faut avant tout déclarer un nouveau type de tuple nommé, avec namedtuple, en déclarant un nom et une liste d'attributs. Voici comment déclarer un tuple nommé Item composé d'un code-barres, d'une description et d'un prix :
2.
3.
from collections import namedtuple
Item = namedtuple('Item', ['barcode', 'description', 'price'])
Une fois le nouveau type de tuple nommé créé, on peut créer des tuples nommés comme suit :
coca = Item(5449000000996, "Coca-Cola 33cl", 0.70)
La variable coca contient un tuple nommé qui est illustré à la figure 6. Toutes les opérations précédemment vues sur les tuples sont également applicables sur les tuples nommés. On peut, par exemple, écrire les instructions suivantes :
2.
3.
4.
print(coca)
print(len(coca))
print(coca[1])
print(coca[1:3])
L'exécution de ces instructions affiche tout simplement :
Item(barcode=5449000000996, description='Coca-Cola 33cl', price=0.7)
3
Coca-Cola 33cl
('Coca-Cola 33cl', 0.7)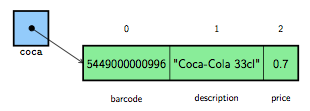
L'avantage apporté par les tuples nommés est qu'on peut accéder à leurs attributs directement avec leur nom avec l'opérateur d'accès (.). On fait donc suivre le nom de la variable du tuple nommé avec le nom de l'attribut, séparé par un point. On peut, par exemple, écrire :
2.
print(coca.description)
sixpackPrice = 6 * coca.price
V-C. Autres types de séquences▲
Deux autres principaux types de séquences existent en Python. On a déjà rencontré les chaines de caractères, qui sont en fait des séquences non modifiables de caractères, et il y a aussi les intervalles de nombres entiers, également non modifiables.
V-C-1. Chaine de caractères▲
Les chaines de caractères sont des séquences non modifiables de caractères. On peut appliquer sur ces dernières tout ce qu'on a vu sur les listes, sauf les opérations de modification, évidemment. Voici un exemple qui utilise des chaines de caractères :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
s = "pa" * 2
print(s)
print(len(s))
print("m" in s)
print(s[1:3])
p = s + " est là."
print(p)
p[0] = "P"
print(p)
L'avant-dernière instruction provoque une erreur d'exécution puisque les chaines de caractères ne sont pas modifiables :
papa
4
False
ap
papa est là.
Traceback (most recent call last):
File "program.py", line 10, in <module>
p[0] = "P"
TypeError: 'str' object does not support item assignmentL'opérateur d'appartenance (in) possède un comportement supplémentaire pour les chaines de caractères. Il permet de tester si une chaine donnée est une sous-chaine d'une autre ou non. Par exemple, on peut vérifier si une chaine de caractères s contient la sous-chaine "pa" grâce à l'instruction suivante :
print("pa" in s)
V-C-1-a. Intervalle▲
Un intervalle est une séquence d'entiers consécutifs, délimitée par deux bornes (une valeur minimale et une valeur maximale). On crée un nouvel intervalle à l'aide de la fonction prédéfinie range. Voici comment déclarer une séquence d'entiers correspondant à l'intervalle des nombres entiers compris entre kitxmlcodeinlinelatexdvp1finkitxmlcodeinlinelatexdvp (inclus) et kitxmlcodeinlinelatexdvp5finkitxmlcodeinlinelatexdvp (exclu) :
i = range(1, 5)Comme on le verra plus loin dans ce chapitre, les intervalles sont, par exemple, utilisés pour parcourir d'autres séquences. Un intervalle est une séquence non modifiable, et on peut utiliser tout ce qu'on a vu sur les listes, à l'exception des opérations de modification, de concaténation et de répétition. Voici quelques instructions que l'on peut écrire :
2.
3.
4.
print(i)
print(len(i))
print(i[2])
print(i[2:5])
Le résultat de leur exécution est conforme à celui attendu :
Par défaut, les éléments d'un intervalle sont distants de une unité. On peut spécifier un pas d'intervalle différent avec le troisième paramètre de la fonction range. Par exemple, on peut construire un intervalle avec les cinq premiers nombres pairs comme suit :
evens = range(2, 12, 2)
L'avantage des intervalles est leur occupation mémoire qui est nettement inférieure à celle d'une liste ou d'un tuple. Ces derniers doivent stocker toutes les valeurs de la séquence, alors que l'intervalle ne stocke essentiellement que les premier et dernier éléments, ainsi que le pas.
V-D. File et pile▲
À partir de séquences, il est possible de construire des types abstraits de données (TAD), c'est-à-dire une structure de données et un ensemble d'opérations qu'il est possible de faire avec. La librairie standard Python propose une série de fonctions permettant d'utiliser une liste comme une file ou une pile, deux types abstraits de données très répandus qui sont des cas particuliers de séquences.
V-D-1. File▲
Une file est une séquence ordonnée d'éléments, c'est-à-dire une liste, tel que l'ajout d'un nouvel élément (enqueue) se fait à sa fin et le retrait d'un élément (dequeue) à sa tête. Une file est une liste de type FIFO (First-in First-out), c'est-à-dire que le premier élément qui y a été ajouté sera aussi le premier qui en sortira, comme l'illustre la figure 7.
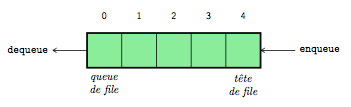
En Python, on utilise la fonction append appliquée sur la liste pour ajouter un élément à sa fin et on utilise la fonction pop pour retirer un élément à son début. Voici un exemple qui crée une file vide, lui ajoute deux éléments, puis en retire un :
2.
3.
4.
5.
6.
7.
8.
9.
10.
queue = [] # la file est vide
queue.append(1) # la file contient [1]
queue.append(2) # la file contient [1, 2]
queue.append(3) # la file contient [1, 2, 3]
result = queue.pop(0) # la file contient [2, 3]
print(result)
print(queue)
Remarquez qu'on a utilisé l'opérateur d'accès (.) sur la variable contenant la file pour appeler les fonctions append et pop. On reviendra plus loin dans ce cours sur la raison pour laquelle on doit procéder ainsi. L'exécution de ces instructions affiche le premier élément retiré de la file, ainsi que les éléments restants dans celle-ci :
1
[2, 3]Pour retirer le premier élément, on a dû faire l'appel pop(0). La raison pour laquelle on doit spécifier un indice est que la fonction pop est plus générale et permet en fait de retirer n'importe quel élément dans une liste, en précisant son indice.
Notez qu'on peut obtenir le même résultat avec des opérations de slicing. En effet, l'ajout d'un élément en fin de liste peut se faire en affectant une valeur à queue[len(queue):], et la suppression du premier élément peut se faire en ne gardant que la fin de liste, à savoir queue[1:]. L'exemple précédent peut donc également s'écrire comme suit :
V-D-1-a. Pile▲
Une pile est également une séquence ordonnée d'éléments, mais tel que l'ajout d'un nouvel élément (push) et le retrait d'un élément (pop) se fait toujours du même côté, en haut de la pile. Une pile est une liste de type LIFO (Last-in First-out), c'est-à-dire que l'élément qui en sortira sera toujours celui qui y est entré en dernier comme l'illustre la figure 8.
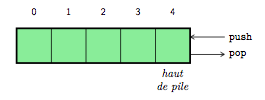
En Python, il va falloir utiliser la fonction append, à appliquer sur la liste, pour lui ajouter un élément à sa fin et la fonction pop pour en retirer un élément à la fin.
Voici un exemple qui crée une pile vide, lui ajoute deux éléments, puis en retire un :
2.
3.
4.
5.
6.
7.
8.
stack = [] # la pile est vide
stack.append(1) # la pile contient [1]
stack.append(2) # la pile contient [1, 2]
stack.append(3) # la pile contient [1, 2, 3]
result = stack.pop() # la pile contient [1, 2]
print(result)
print(stack)
La fonction pop est, cette fois-ci, appelée sans paramètre. En effet, par défaut elle va retirer l'élément en fin de liste. L'exécution de ces instructions affiche le premier élément retiré de la pile, ainsi que les éléments restants dans celle-ci :
3
[1, 2]De nouveau, on peut obtenir le même résultat avec des opérations de slicing. L'exemple précédent peut se réécrire comme suit :
V-E. Itérateur▲
Terminons ce chapitre avec le concept d'itérateur, mécanisme permettant de parcourir les éléments de n'importe quelle collection d'éléments. Le parcours se fait de manière transparente, sans que l'on doive se soucier de la manière avec laquelle les éléments de la collection sont organisés.
Dans le cas des séquences, étant donné que leurs éléments sont ordonnés, leurs parcours suivront toujours cet ordre. Mais comme on le verra dans la seconde partie du livre, ce n'est pas le cas pour toutes les collections. L'itérateur n'est pas nécessaire, on peut toujours utiliser une boucle while classique. Il rend néanmoins parfois le code bien plus lisible et il est également parfois la seule solution utilisable, lorsqu'il n'est, par exemple, pas possible d'accéder directement aux éléments d'une collection.
V-E-1. Instruction for▲
Pour parcourir une collection d'éléments, on peut utiliser l'instruction for. Voyons tout de suite un premier exemple :
2.
3.
numbers = [1, 2, 3, 4, 5]
for n in numbers:
print(n)
Lors de l'exécution de ces instructions, la variable n prend successivement comme valeur celle des éléments de la liste numbers. Étant donné que c'est une liste, et donc une séquence ordonnée, ses éléments sont parcourus dans l'ordre défini par la liste.
Avec cette méthode de parcours, on ne doit plus utiliser d'indice pour accéder aux éléments de la liste. Si on désire quand même utiliser les indices, il suffit de créer une séquence avec ces derniers, un intervalle par exemple, et de la parcourir avec l'itérateur :
On remarque qu'on n'a spécifié qu'un seul paramètre à la fonction range et dans ce cas, la borne inférieure vaut par défaut kitxmlcodeinlinelatexdvp0finkitxmlcodeinlinelatexdvp, ce qui correspond bien au premier indice d'une liste.
V-E-1-a. Définition de séquence par compréhension▲
L'instruction for peut également être utilisée dans un autre contexte. Jusqu'à présent, pour créer une nouvelle séquence, soit on en spécifiait tous les éléments lors de son initialisation, soit on la construisait en faisant du slicing, de la concaténation ou une répétition.
Grâce à l'instruction for, on va pouvoir créer une nouvelle séquence par compréhension, c'est-à-dire en sélectionnant un sous-ensemble d'une séquence dont les éléments satisfont une propriété.
Prenons un exemple pour comprendre ce concept. Si on veut construire une séquence qui contient les carrés des nombres entiers compris entre kitxmlcodeinlinelatexdvp0finkitxmlcodeinlinelatexdvp et kitxmlcodeinlinelatexdvp100finkitxmlcodeinlinelatexdvp (inclus), on ne peut pas le faire en listant toutes les valeurs. Une première solution consiste à utiliser une boucle et la fonction append qui permet d'ajouter un élément à une liste. La boucle suivante parcourt les entiers de kitxmlcodeinlinelatexdvp0finkitxmlcodeinlinelatexdvp à kitxmlcodeinlinelatexdvp100finkitxmlcodeinlinelatexdvp et ajoute à la liste squares les carrés de ces entiers :
2.
3.
4.
5.
squares = []
i = 0
while i <= 100:
squares.append(i ** 2)
i += 1
Cette boucle peut évidemment se réécrire avec l'instruction for et à l'aide de la fonction range à qui on donne kitxmlcodeinlinelatexdvp101finkitxmlcodeinlinelatexdvp en paramètre, ce dernier représentant la borne supérieure de l'intervalle, non incluse :
2.
3.
squares = []
for i in range(101):
squares.append(i ** 2)
Lorsqu'on a cette structure particulière de boucle, dont le but est d'initialiser une liste, on peut l'écrire de manière plus compacte pour directement définir les éléments de la liste lors de son initialisation :
squares = [i ** 2 for i in range(101)]
Cette notation, plus intuitive, se lit comme : « la liste est composée d'éléments de la forme kitxmlcodeinlinelatexdvpi^2finkitxmlcodeinlinelatexdvp pour tout kitxmlcodeinlinelatexdvpifinkitxmlcodeinlinelatexdvp compris entre kitxmlcodeinlinelatexdvp0finkitxmlcodeinlinelatexdvp et kitxmlcodeinlinelatexdvp101finkitxmlcodeinlinelatexdvp (exclu) ». C'est ce qu'on appelle une définition de liste par compréhension.
De plus, il est possible d'ajouter une condition que doivent satisfaire les éléments générés, à l'aide d'une instruction if. Supposons, par exemple, qu'on ne veuille que les carrés des entiers qui sont divisibles par kitxmlcodeinlinelatexdvp3finkitxmlcodeinlinelatexdvp. Pour cela, on écrira simplement :
squares = [i ** 2 for i in range(101) if i % 3 == 0]
Cela revient en fait à écrire le code suivant :
2.
3.
4.
squares = []
for i in range(101):
if i % 3 == 0:
squares.append(i ** 2)