


4. Conteneurs standard▲
Le chapitre 3.4Les types de données entiers a présenté les types de données simples, mais Python offre beaucoup plus : les conteneurs.
De façon générale, un conteneur est un objet composite destiné à contenir d'autres objets. Ce chapitre détaille les séquences, les tableaux associatifs, les ensembles et les fichiers textuels.
4-1. Séquences▲
Une séquence est un conteneur ordonné d'éléments indexés par des entiers indiquant leur position dans le conteneur.
Python dispose de trois types prédéfinis de séquences :
- les chaînes (vues précédemment) ;
- les listes ;
- les tuples(11).
4-2. Listes▲
4-2-1. Définition, syntaxe et exemples▲
Une liste est une collection ordonnée et modifiable d'éléments éventuellement hétérogènes.
Éléments séparés par des virgules, et entourés de crochets.
Exemples simples de listes :
couleurs = ['trèfle', 'carreau', 'coeur', 'pique']
print(couleurs) # ['trèfle', 'carreau', 'coeur', 'pique']
couleurs[1] = 14
print(couleurs) # ['trèfle', 14, 'coeur', 'pique']
list1 = ['a', 'b']
list2 = [4, 2.718]
list3 = [list1, list2] # liste de listes
print(list3) # [['a', 'b'], [4, 2.718]]4-2-2. Initialisations et tests d'appartenance▲
Utilisation de la répétition, de l'itérateur d'entiers range() et de l'opérateur d'appartenance (in) :
>>> truc = []
>>> machin = [0.0] * 3
>>> truc
[]
>>> machin
[0.0, 0.0, 0.0]
>>>
>>> liste_1 = list(range(4))
>>> liste_1
[0, 1, 2, 3]
>>> liste_2 = list(range(4, 8))
>>> liste_2
[4, 5, 6, 7]
>>> liste_3 = list(range(2, 9, 2))
>>> liste_3
[2, 4, 6, 8]
>>>
>>> 2 in liste_1, 8 in liste_2, 6 in liste_3
(True, False, True)4-2-3. Méthodes▲
Quelques méthodes de modification des listes :
>>> nombres = [17, 38, 10, 25, 72]
>>> nombres.sort()
>>> nombres
[10, 17, 25, 38, 72]
>>> nombres.append(12)
>>> nombres.reverse()
>>> nombres
[12, 72, 38, 25, 17, 10]
>>> nombres.remove(38)
>>> nombres
[12, 72, 25, 17, 10]
>>> nombres.index(17)
3
>>> nombres[0] = 11
>>> nombres[1:3] = [14, 17, 2]
>>> nombres
[11, 14, 17, 2, 17, 10]
>>> nombres.pop()
10
>>> nombres
[11, 14, 17, 2, 17]
>>> nombres.count(17)
2
>>> nombres.extend([1, 2, 3])
>>> nombres
[11, 14, 17, 2, 17, 1, 2, 3]4-2-4. Manipulation des tranches (ou sous-chaînes)▲
Si on veut supprimer, remplacer ou insérer plusieurs éléments d'une liste, il faut indiquer une tranche (cf. chapitre 2.7.7Extraction de sous-chaînes) dans le membre de gauche d'une affectation et fournir une liste dans le membre de droite.
>>> mots = ['jambon', 'sel', 'miel', 'confiture', 'beurre']
>>> mots[2:4] = [] # effacement par affectation d'une liste vide
>>> mots
['jambon', 'sel', 'beurre']
>>> mots[1:3] = ['salade']
>>> mots
['jambon', 'salade']
>>> mots[1:] = ['mayonnaise', 'poulet', 'tomate']
>>> mots
['jambon', 'mayonnaise', 'poulet', 'tomate']
>>> mots[2:2] = ['miel'] # insertion en 3e position
>>> mots
['jambon', 'mayonnaise', 'miel', 'poulet', 'tomate']4-2-5. Séquences de séquences▲
Les séquences, comme du reste les autres conteneurs, peuvent être imbriquées.
Par exemple :
>>> liste_1 = [1, 2, 3]
>>> listes = [liste_1, [4, 5], "abcd"]
>>>
>>> for liste in listes:
... for elem in liste:
... print(elem)
... print()
...
1
2
3
4
5
a
b
c
d4-3. Tuples▲
Un tuple est une collection ordonnée et non modifiable d'éléments éventuellement hétérogènes.
Éléments séparés par des virgules, et entourés de parenthèses.
>>> mon_tuple = ('a', 2, [1, 3])- L'indexage des tuples s'utilise comme celui des listes.
- Le parcours des tuples est plus rapide que celui des listes.
- Ils sont utiles pour définir des constantes.
Comme les chaînes de caractères, les tuples ne sont pas modifiables !
>>> mon_tuple.append(4) # attention ne pas modifier un tuple !
Traceback (most recent call last) :
File "<stdin>", line 1, in <module>
AttributeError : 'tuple' object has no attribute 'append'4-3-1. Les opérations des objets de type séquentiel▲
Les types prédéfinis de séquences Python (chaîne, liste et tuple) ont en commun les opérations résumées dans le tableau suivant où s et t désignent deux séquences du même type et i, j et k des entiers :
|
l'opération |
son effet |
|---|---|
|
x in s |
True si s contient x, False sinon |
|
x not in s |
True si s ne contient pas x, False sinon |
|
s + t |
concaténation de s et t |
|
s * n, n * s |
n copies (superficielles) concaténées de s |
|
s[i] |
i élément de s (à partir de 0) |
|
s[i:j] |
tranche de s de i (inclus) à j (exclu) |
|
s[i:j:k] |
tranche de s de i à j avec un pas de k |
|
len(s) |
longueur de s |
|
max(s), min(s) |
plus grand, plus petit élément de s |
|
s.index(i) |
indice de la 1re occurrence de i dans s |
|
s.count(i) |
nombre d'occurrences de i dans s |
4-4. Retour sur les références▲
Nous avons déjà vu que l'opération d'affectation, apparemment innocente, est une réelle difficulté de Python.
i = 1
msg = "Quoi de neuf ?"
e = 2.718Dans l'exemple ci-dessus, les affectations réalisent plusieurs opérations :
- création en mémoire d'un objet du type approprié (membre de droite) ;
- stockage de la donnée dans l'objet créé ;
- création d'un nom de variable (membre de gauche) ;
- association de ce nom de variable avec l'objet contenant la valeur.
Une conséquence de ce mécanisme est que, si un objet modifiable est affecté à plusieurs variables, tout changement de l'objet via une variable sera visible sur tous les autres :
fable = ["Je", "plie", "mais", "ne", "romps", "point"]
phrase = fable
phrase[4] = "casse"
print(fable) # ['Je', 'plie', 'mais', 'ne', 'casse', 'point']Si on veut pouvoir effectuer des modifications séparées, il faut affecter l'autre variable par une copie distincte de l'objet, soit en créant une tranche complète des séquences dans les cas simples, soit en utilisant le module copy dans les cas les plus généraux (autres conteneurs). Dans les rares occasions où l'on veut aussi que chaque élément et attribut de l'objet soit copié séparément et de façon récursive, on emploie la fonction copy.deepcopy() :
>>> import copy
>>> a = [1, 2, 3]
>>> b = a # une référence
>>> b.append(4)
>>> a
[1, 2, 3, 4]
>>> c = a[:] # une copie simple
>>> c.append(5)
>>> c
[1, 2, 3, 4, 5]
>>> d = copy.copy(a) # une copie de"surface"
>>> d.append(6)
>>> d
[1, 2, 3, 4, 6]
>>> a
[1, 2, 3, 4]
>>> d1 = {'a' : [1, 2], 'b' : [3, 4]}
>>> d2 = {'c' : (1, 2, 3), 'c' : (4, 5, 6)}
>>> liste_de_dicos = [d1, d2]
>>> nouvelle_liste_de_dicos = copy.deepcopy(liste_de_dicos) # copie "profonde" (ou "récursive")
>>> nouvelle_liste_de_dicos
[{'a': [1, 2], 'b': [3, 4]}, {'c': (4, 5, 6)}]4-4-1. Complément graphique sur l'assignation▲
-
Assignation augmentée d'un objet non modifiable (cas d'un entier : Fig. 4.1). On a représenté l'étape de l'addition intermédiaire.
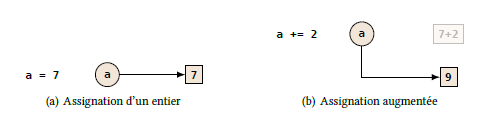
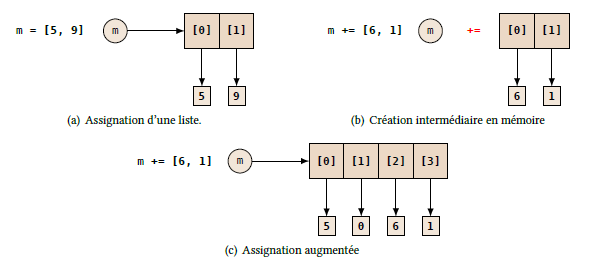
Figure 4.1 - Assignation augmentée d'un objet non modifiable - Assignation augmentée d'un objet modifiable (cas d'une liste : Fig. 4.2). On a représenté l'étape de la création de la liste intermédiaire.
4-5. Tableaux associatifs▲
Un tableau associatif est un type de données permettant de stocker des couples (cle : valeur), avec un accès très rapide à la valeur à partir de la clé, la clé ne pouvant être présente qu'une seule fois dans le tableau.
Il possède les caractéristiques suivantes :
- l'opérateur d'appartenance d'une clé (in) ;
- la fonction taille (len()) donnant le nombre de couples stockés ;
- il est itérable (on peut le parcourir), mais n'est pas ordonné.
Python propose le type standard dict.
4-5-1. Dictionnaires (dict)▲
Les dictionnaires constituent un type composite, mais ils n'appartiennent pas aux séquences.
Les dictionnaires sont modifiables, mais non ordonnés : les couples enregistrés n'occupent pas un ordre immuable, leur emplacement est géré par un algorithme spécifique (algorithme de hash). Le caractère non ordonné des dictionnaires est le prix à payer pour leur rapidité !
Une clé pourra être alphabétique, numérique… en fait tout type hachable (donc liste et dictionnaire exclus). Les valeurs pourront être de tout type sans exclusion.
4-5-1-a. Exemples de création▲
>>> d1 = {} # dictionnaire vide. Autre notation : d1 = dict()
>>> d1["nom"] = 3
>>> d1["taille"] = 176
>>> d1
{'nom': 3, 'taille': 176}
>>>
>>> d2 = {"nom": 3, "taille": 176} # définition en extension
>>> d2
{'nom': 3, 'taille': 176}
>>>
>>> d3 = {x: x**2 for x in (2, 4, 6)} # définition en compréhension
>>> d3
{2: 4, 4: 16, 6: 36}
>>>
>>> d4 = dict(nom=3, taille=176) # utilisation de paramètres nommés
>>> d4
{'taille': 176, 'nom': 3}
>>>
>>> d5 = dict([("nom", 3), ("taille", 176)]) # utilisation d'une liste de couples clés/valeurs
>>> d5
{'nom': 3, 'taille': 176}4-5-1-b. Méthodes▲
Quelques méthodes applicables aux dictionnaires :
>>> tel = {'jack': 4098, 'sape': 4139}
>>> tel['guido'] = 4127
>>> tel
{'sape': 4139, 'jack': 4098, 'guido': 4127}
>>> tel['jack']
4098
>>> del tel['sape']
>>> tel['irv'] = 4127
>>> tel
{'jack': 4098, 'irv': 4127, 'guido': 4127}
>>>
>>> tel.keys()
['jack', 'irv', 'guido']
>>> sorted(tel.keys())
['guido', 'irv', 'jack']
>>> sorted(tel.values())
[4098, 4127, 4127]
>>> 'guido' in tel, 'jack' not in tel
(True, False)4-6. Ensembles (set)▲
Un ensemble est une collection itérable non ordonnée d'éléments hachables uniques.
Donc un set est la transposition informatique de la notion d'ensemble mathématique.
En Python, il existe deux types d'ensembles, les ensembles modifiables : set et les ensembles non modifiables : frozenset. On retrouve ici les mêmes différences qu'entre les listes et les tuples.
>>> X = set('spam')
>>> Y = set('pass')
>>> X
{'s', 'p', 'm', 'a'}
>>> Y # pas de duplication : qu'un seul 's'
{'s', 'p', 'a'}
>>> 'p' in X
True
>>> 'm' in Y
False
>>> X - Y # ensemble des éléments de X qui ne sont pas dans Y
{'m'}
>>> Y - X # ensemble des éléments de Y qui ne sont pas dans X
set()
>>> X ^ Y # ensemble des éléments qui sont soit dans X soit dans Y
{'m'}
>>> X | Y # union
{'s', 'p', 'm', 'a'}
>>> X & Y # intersection
{'s', 'p', 'a'}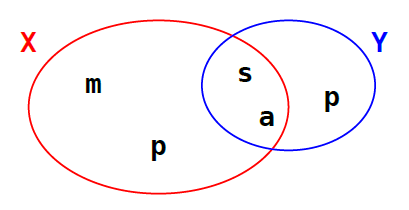
4-7. Fichiers textuels▲
4-7-1. Introduction▲
On rappelle que l'ordinateur n'exécute que les programmes présents dans sa mémoire volatile (la RAM). Pour conserver durablement des informations, il faut utiliser une mémoire permanente par exemple le disque dur, la clé USB, le DVD… sur lesquels le système d'exploitation organise les données sous la forme de fichiers.
Comme la plupart des langages, Python utilise classiquement la notion de fichier.
Nous limiterons nos exemples aux fichiers textuels (lisibles par un éditeur), mais signalons que les fichiers stockés en codage binaire sont plus compacts et plus rapides à gérer (utiles pour les grands volumes de données).
4-7-2. Gestion des fichiers▲
4-7-2-a. Ouverture et fermeture des fichiers▲
Principaux modes d'ouverture des fichiers textuels(12) :
f1 = open("monFichier_1", "r", encoding='utf8') #"r" mode lecture
f2 = open("monFichier_2", "w", encoding='utf8') #"w" mode écriture
f3 = open("monFichier_3", "a", encoding='utf8') #"a" mode ajoutPython utilise les fichiers en mode texte par défaut (mode t). Pour les fichiers binaires, il faut préciser le mode b.
Le paramètre optionnel encoding assure les conversions entre les types byte (c'est-à-dire des tableaux d'octets), format de stockage des fichiers sur le disque, et le type str (qui, en Python 3, signifie toujours Unicode), manipulé lors des lectures et écritures. Il est prudent de toujours l'utiliser.
Les encodages les plus fréquents sont utf8 (c'est l'encodage à privilégier en Python 3), latin1, ASCII…
Tant que le fichier n'est pas fermé(13), son contenu n'est pas garanti sur le disque.
Une seule méthode de fermeture :
f1.close()4-7-2-b. Écriture séquentielle▲
Le fichier sur disque est considéré comme une séquence de caractères qui sont ajoutés à la suite, au fur et à mesure que l'on écrit dans le fichier.
Méthodes d'écriture :
f = open("truc.txt", "w", encoding='utf8')
s = 'toto\n'
f.write(s) # écrit la chaîne s dans f
l = ['a', 'b', 'c']
f.writelines(l) # écrit les chaînes de la liste l dans f
f.close()
f2 = open("truc2.txt", "w", encoding='utf8')
print("abcd", file=f2) # utilisation de l'option file
f2.close()4-7-2-c. Lecture séquentielle▲
En lecture, la séquence de caractères qui constitue le fichier est parcourue en commençant au début du fichier et en avançant au fur et à mesure des lectures.
Méthodes de lecture d'un fichier en entier :
>>> f = open("truc.txt", "r", encoding='utf8')
>>> s = f.read() # lit tout le fichier --> chaîne
>>> f.close()
>>> f = open("truc.txt", "r", encoding='utf8')
>>> s = f.readlines() # lit tout le fichier --> liste de chaînes
>>> f.close()Méthodes de lecture d'un fichier partiel :
>>> f = open("truc.txt", "r", encoding='utf8')
>>> s = f.read(3) # lit au plus n octets --> chaîne
>>> s = f.readline() # lit la ligne suivante --> chaîne
>>> f.close()
>>>
>>> # Affichage des lignes d'un fichier une à une
>>> f = open("truc.txt", encoding='utf8') # mode"r" par défaut
>>> for ligne in f:
... print(ligne)
...
>>> f.close()4-8. Itérer sur les conteneurs▲
Les techniques suivantes sont classiques et très utiles.
Obtenir clés et valeurs en bouclant sur un dictionnaire :
knights = {"Gallahad" : "the pure", "Robin" : "the brave"}
for k, v in knights.items() :
print(k, v)
# Gallahad the pure
# Robin the braveObtenir indice et élément en bouclant sur une liste :
>>> for i, v in enumerate(["tic", "tac", "toe"]):
... print(i, '->', v)
...
0 -> tic
1 -> tac
2 -> toeBoucler sur deux séquences (ou plus) appariées :
>>> questions = ['name', 'quest', 'favorite color']
>>> answers = ['Lancelot', 'the Holy Grail', 'blue']
>>> for question, answer in zip(questions, answers):
... print('What is your', question, '? It is', answer)
...
What is your name ? It is Lancelot
What is your quest ? It is the Holy Grail
What is your favorite color ? It is blueObtenir une séquence inversée (la séquence initiale est inchangée) :
for i in reversed(range(1, 10, 2)) :
print(i, end="") # 9 7 5 3 1Obtenir une séquence triée à éléments uniques (la séquence initiale est inchangée) :
basket = ["apple", "orange", "apple", "pear", "orange", "banana"]
for f in sorted(set(basket)) :
print(f, end="") # apple banana orange pear4-9. Affichage formaté▲
La méthode format() permet de contrôler finement la création de chaînes formatées. On l'utilisera pour un affichage via print(), pour un enregistrement via f.write(), ou dans d'autres cas.
Remplacements simples :
print("{} {} {}".format("zéro", "un", "deux")) # zéro un deux
# formatage d'une chaîne pour usages ultérieurs
chain = "{2} {0} {1}".format("zéro", "un", "deux")
print(chain) # affichage : deux zéro un
with open("test.txt", "w", encoding="utf8") as f :
f.write(chain) # enregistrement dans un fichier
print("Je m'appelle {}".format("Bob")) # Je m'appelle Bob
print("Je m'appelle {{{}}}".format("Bob")) # Je m'appelle {Bob}
print("{}".format("-"*10)) # ----------Remplacements avec champs nommés :
a, b = 5, 3
print("The story of {c} and {d}".format(c=a+b, d=a-b)) # The story of 8 and 2Formatages à l'aide de liste :
stock = ['papier', 'enveloppe', 'chemise', 'encre', 'buvard']
print("Nous avons de l'{0[3]} et du {0[0]} en stock\n".format(stock)) # Nous avons de l'encre et du papier en stockFormatages à l'aide de dictionnaire :
print("My name is {0[name]}".format(dict(name='Fred'))) # My name is Fred
d = dict(poids = 12000, animal = 'éléphant')
print("L'{0[animal]} pèse {0[poids]} kg\n".format(d)) # L'éléphant pèse 12000 kgRemplacement avec attributs nommés :
import math
import sys
print("math.pi = {.pi}, epsilon = {.float_info.epsilon}".format(math, sys))
# math.pi = 3.14159265359, epsilon = 2.22044604925e-16Conversions textuelles, str() et repr()(14) :
>>> print("{0!s} {0!r}".format("texte\n"))
texte
'texte\n'Formatages numériques :
s = "int :{0:d} ; hex : {0:x} ; oct : {0:o} ; bin : {0:b}".format(42)
print(s) # int :42; hex : 2a ; oct : 52; bin : 101010
s = "int :{0:d} ; hex : {0:#x} ; oct : {0:#o} ; bin : {0:#b}".format(42)
print(s) # int :42; hex : 0x2a ; oct : 0o52 ; bin : 0b101010
n = 100
pi = 3.1415926535897931
k = -54
print("{ :.4e}".format(pi)) # 3.1416e+00
print("{ :g}".format(pi)) # 3.14159
print("{ :.2%}".format(n/(47*pi))) # 67.73%
msg = "Résultat sur { :d} échantillons : { :.2f}".format(n, pi)
print(msg) # Résultat sur 100 échantillons : 3.14
msg = "{0.real} et {0.imag} sont les composantes du complexe {0}".format(3-5j)
print(msg) # 3.0 et -5.0 sont les composantes du complexe (3-5j)
print("{ :+d} { :+d}".format(n, k)) # +100 -54 (on force l'affichage du signe)
print("{ :,}".format(1234567890.123)) # 1,234,567,890.12Formatages divers :
>>> s = "The sword of truth"
>>> print("[{}]".format(s))
[The sword of truth]
>>> print("[{:25}]".format(s))
[The sword of truth ]
>>> print("[{:>25}]".format(s))
[ The sword of truth]
>>> print("[{:^25}]".format(s))
[ The sword of truth ]
>>> print("[{:-^25}]".format(s))
[---The sword of truth----]
>>> print("[{:.<25}]".format(s))
[The sword of truth.......]
>>> lng = 12
>>> print("[{}]".format(s[:lng]))
[The sword of]
>>> m = 123456789
>>> print("{:0=12}".format(m))
000123456789