


12. Jeux de caractères et encodage▲
12-1. Position du problème▲
Nous avons vu que l'ordinateur code toutes les informations qu'il manipule en binaire. Pour coder les nombres entiers, un changement de base suffit, pour les flottants, on utilise une norme (IEEE 754), mais la situation est plus complexe pour représenter les caractères.
Tous les caractères que l'on peut écrire à l'aide d'un ordinateur sont représentés en mémoire par des nombres. On parle d'encodage. Le « a » minuscule par exemple est représenté, ou encodé, par le nombre 97. Pour pouvoir afficher ou imprimer un caractère lisible, leurs dessins, appelés glyphes, sont stockés dans des catalogues appelés polices de caractères. Les logiciels informatiques parcourent ces catalogues pour rechercher le glyphe qui correspond à un nombre. Suivant la police de caractères, on peut ainsi afficher différents aspects du même « a » (97).
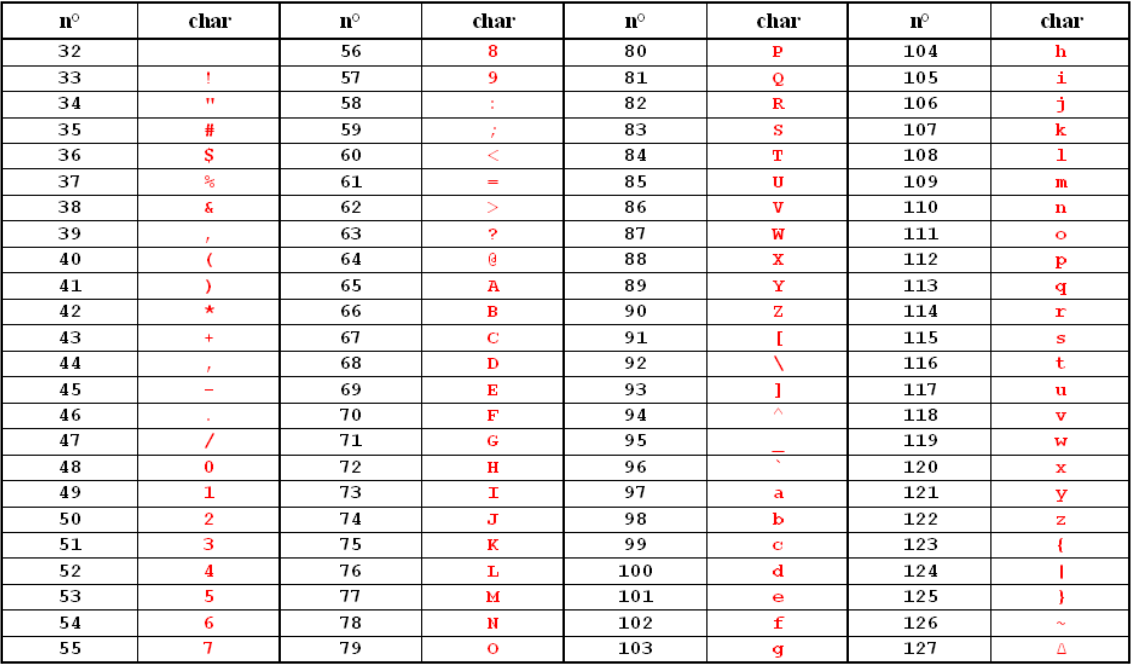
Les 128 premiers caractères comprennent les caractères de l'alphabet latin (non altérés(46)), les majuscules et les minuscules, les chiffres arabes, et quelques signes de ponctuation, c'est la fameuse table ASCII(47) (Fig. 10.1). Chaque pays a ensuite complété ce jeu initial suivant les besoins de sa propre langue, créant ainsi son propre système d'encodage.
Cette méthode a un fâcheux inconvénient : le caractère « à » français peut alors être représenté par le même nombre que le caractère scandinave « å » dans les deux encodages, ce qui rend impossible l'écriture d'un texte bilingue avec ces deux caractères !
Pour écrire un document en plusieurs langues, le standard nommé Unicode a été développé et maintenu par un consortium(48). Il permet d'unifier une grande table de correspondance internationale, sans chevauchement entre les caractères. Les catalogues de police se chargent ensuite de fournir des glyphes correspondants.
12-1-1. L'encodage UTF-8▲
Comme il s'agit de différencier plusieurs centaines de milliers de caractères (on compte plus de 6000 langues dans le monde), il n'est évidemment pas possible de les encoder sur un seul octet.
En fait, la norme Unicode ne fixe aucune règle concernant le nombre d'octets ou de bits à réserver pour l'encodage, mais spécifie seulement la valeur numérique de l'identifiant associé à chaque caractère (Fig. 10.2).

Comme la plupart des textes produits en Occident utilisent essentiellement la table ASCII qui correspond justement à la partie basse de la table Unicode, l'encodage le plus économique est l'UTF-8(49) :
- pour les codes 0 à 127 (cas les plus fréquents), l'UTF-8 utilise l'octet de la table ASCII ;
- pour les caractères spéciaux (codes 128 à 2047), quasiment tous nos signes diacritiques, l'UTF-8 utilise 2 octets ;
- pour les caractères spéciaux encore moins courants (codes 2048 à 65535), l'UTF-8 utilise 3 octets ;
- enfin pour les autres (cas rares), l'UTF-8 en utilise 4.
Exemple de l'encodage UTF-8 du caractère Unicode « é » :
|
Symbole |
Code décimal |
Code hexadécimal |
Encodage UTF-8 |
|---|---|---|---|
|
é |
233 |
e9 |
C3 A9 |
Voici trois exemples de caractères spéciaux codés en notation hexadécimale et séparés par le caractère d'échappement de la tabulation :
>>> print("\u00e9 \t \u0110 \t \u0152")
é ? OE12-1-2. Applications aux scripts Python▲
En Python 3, les chaînes de caractères (le type str()) sont des chaînes Unicode. Par ailleurs, puisque les scripts Python que l'on produit avec un éditeur sont eux-mêmes des textes, ils sont susceptibles d'être encodés suivant différents formats. Afin que Python utilise le bon, il est important d'indiquer l'encodage de caractères utilisé. On le précise obligatoirement en 1re ou 2e ligne des sources.
Les encodages les plus fréquents sont(50) :
# -*- coding : utf8 -*-ou :
# -*- coding : latin1 -*-