| Python Library Reference |
The audioop module contains some useful operations on sound fragments. It operates on sound fragments consisting of signed integer samples 8, 16 or 32 bits wide, stored in Python strings. This is the same format as used by the al and sunaudiodev modules. All scalar items are integers, unless specified otherwise.
This module provides support for a-LAW, u-LAW and Intel/DVI ADPCM encodings.
A few of the more complicated operations only take 16-bit samples, otherwise the sample size (in bytes) is always a parameter of the operation.
The module defines the following variables and functions:
| fragment1, fragment2, width) |
1, 2 or 4. Both fragments should have the same
length.
| adpcmfragment, width, state) |
(sample, newstate) where the sample
has the width specified in width.
| fragment, width) |
| fragment, width) |
| fragment, width) |
| fragment, width, bias) |
| fragment, width) |
| fragment, reference) |
rms(add(fragment, mul(reference, -F))) is
minimal, i.e., return the factor with which you should multiply
reference to make it match as well as possible to
fragment. The fragments should both contain 2-byte samples.
The time taken by this routine is proportional to
len(fragment).
| fragment, reference) |
(offset, factor) where offset is the
(integer) offset into fragment where the optimal match started
and factor is the (floating-point) factor as per
findfactor().
| fragment, length) |
rms(fragment[i*2:(i+length)*2]) is maximal. The fragments
should both contain 2-byte samples.
The routine takes time proportional to len(fragment).
| fragment, width, index) |
| fragment, width, state) |
state is a tuple containing the state of the coder. The coder
returns a tuple (adpcmfrag, newstate), and the
newstate should be passed to the next call of
lin2adpcm(). In the initial call, None can be
passed as the state. adpcmfrag is the ADPCM coded fragment
packed 2 4-bit values per byte.
| fragment, width) |
| fragment, width, newwidth) |
| fragment, width) |
| fragment, width) |
| fragment, width) |
| fragment, width) |
| fragment, width, factor) |
| fragment, width, nchannels, inrate, outrate, state[, weightA[, weightB]]) |
state is a tuple containing the state of the converter. The
converter returns a tuple (newfragment, newstate),
and newstate should be passed to the next call of
ratecv(). The initial call should pass None
as the state.
The weightA and weightB arguments are parameters for a
simple digital filter and default to 1 and 0 respectively.
| fragment, width) |
| fragment, width) |
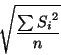
| fragment, width, lfactor, rfactor) |
| fragment, width, lfactor, rfactor) |
| fragment, width) |
Note that operations such as mul() or max() make no distinction between mono and stereo fragments, i.e. all samples are treated equal. If this is a problem the stereo fragment should be split into two mono fragments first and recombined later. Here is an example of how to do that:
def mul_stereo(sample, width, lfactor, rfactor):
lsample = audioop.tomono(sample, width, 1, 0)
rsample = audioop.tomono(sample, width, 0, 1)
lsample = audioop.mul(sample, width, lfactor)
rsample = audioop.mul(sample, width, rfactor)
lsample = audioop.tostereo(lsample, width, 1, 0)
rsample = audioop.tostereo(rsample, width, 0, 1)
return audioop.add(lsample, rsample, width)
If you use the ADPCM coder to build network packets and you want your protocol to be stateless (i.e. to be able to tolerate packet loss) you should not only transmit the data but also the state. Note that you should send the initial state (the one you passed to lin2adpcm()) along to the decoder, not the final state (as returned by the coder). If you want to use struct.struct() to store the state in binary you can code the first element (the predicted value) in 16 bits and the second (the delta index) in 8.
The ADPCM coders have never been tried against other ADPCM coders, only against themselves. It could well be that I misinterpreted the standards in which case they will not be interoperable with the respective standards.
The find*() routines might look a bit funny at first sight. They are primarily meant to do echo cancellation. A reasonably fast way to do this is to pick the most energetic piece of the output sample, locate that in the input sample and subtract the whole output sample from the input sample:
def echocancel(outputdata, inputdata):
pos = audioop.findmax(outputdata, 800) # one tenth second
out_test = outputdata[pos*2:]
in_test = inputdata[pos*2:]
ipos, factor = audioop.findfit(in_test, out_test)
# Optional (for better cancellation):
# factor = audioop.findfactor(in_test[ipos*2:ipos*2+len(out_test)],
# out_test)
prefill = '\0'*(pos+ipos)*2
postfill = '\0'*(len(inputdata)-len(prefill)-len(outputdata))
outputdata = prefill + audioop.mul(outputdata,2,-factor) + postfill
return audioop.add(inputdata, outputdata, 2)
| Python Library Reference |