| You are here: Sommaire > Plongez au coeur de Python > Des scripts et des flots de données (streams) > Mettre en cache la consultation de noeuds | << >> | ||||
Plongez au coeur de PythonDe débutant à expert |
|||||
kgp.py recourt à différentes astuces qui peuvent ou non se révéler également utiles dans votre traitement XML. La première tire avantage de la structure logique des documents en entrée pour construire un cache de noeuds.
Un fichier de grammaire définit une série d'éléments ref. Chaque élément ref contient un ou plusieurs éléments p, qui peuvent contenir à leur tour un bon nombre de choses, y compris des éléments xref. Chaque fois que vous rencontrez un élément xref, vous cherchez un élément ref correspondant avec le même attribut id et choisissez l'un des enfants de l'élément ref pour l'analyser. (Vous verrez comment est effectué ce choix aléatoire dans la prochaine section.)
Voici comment construire la grammaire : définissez des éléments ref pour les plus petites parties, puis définissez des éléments ref qui "incluent" les premiers éléments ref au moyen de xref et ainsi de suite. Ensuite vous analysez la référence "la plus large" et suivez chaque xref, et au besoin vous récupérez le texte brut associé. Le texte que vous produisez dépend des décisions (aléatoires) que vous faites chaque fois que vous renseignez un élément xref, ainsi le résultat est à chaque fois différent.
Tout cela fonctionne d'une manière très souple, mais il y a un revers : la performance. Lorsque vous trouvez un élément xref et avez besoin de retrouver l'élément ref correspondant, un problème se pose. L'élément xref a un attribut id et vous désirez trouver l'élément ref qui a le même attribut id, mais il n'y a pas de moyen simple de le faire. La façon lente de procéder serait de récupérer à chaque fois la liste complète des éléments ref, et de les parcourir en recherchant chaque attribut id. La manière rapide est de ne faire qu'une fois ce travail en construisant un cache sous la forme d'un dictionnaire.
def loadGrammar(self, grammar):
self.grammar = self._load(grammar)
self.refs = {} 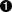 for ref in self.grammar.getElementsByTagName("ref"):
for ref in self.grammar.getElementsByTagName("ref"): 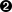 self.refs[ref.attributes["id"].value] = ref
self.refs[ref.attributes["id"].value] = ref 

| Commencez par créer un dictionnaire vide, self.refs. | |
| Comme vous l'avez vu dans la Section 9.5, «Rechercher des éléments», getElementsByTagName retourne une liste de tous les éléments portant le même nom. Vous pouvez obtenir facilement une liste de tous les éléments ref, puis simplement la parcourir. | |
| Comme vous l'avez vu dans la Section 9.6, «Accéder aux attributs d'un élément», vous pouvez accéder aux attributs individuels d'un élément par leur nom, en utilisant la syntaxe d'un dictionnaire standard. Ainsi les clés du dictionnaire self.refs seront les valeurs de l'attribut id de chaque élément ref. | |
| Les valeurs du dictionnaire self.refs seront les éléments ref eux-mêmes. Comme vous l'avez vu dans la Section 9.3, «Analyser un document XML», chaque élément, chaque noeud, chaque commentaire, chaque fragment de texte d'un document XML après analyse devient un objet. |
Une fois le cache construit, il vous suffit simplement de consulter self.refs lorsque vous tombez sur un élément xref et qu'il vous faut retrouver l'élément ref avec l'attribut id correspondant.
def do_xref(self, node):
id = node.attributes["id"].value
self.parse(self.randomChildElement(self.refs[id]))Vous explorerez la fonction randomChildElement dans la prochaine section.
<< Entrée, sortie et erreur standard |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
Trouver les descendants directs d'un noeud >> |