9.3. Analyser un document XML
Comme je le disais, analyser un document XML est chose très simple qui tient en une ligne de code. A vous de décider de la suite.
Exemple 9.8. Charger un document XML (version longue)
>>> from xml.dom import minidom 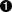 >>> xmldoc = minidom.parse('~/diveintopython/common/py/kgp/binary.xml')
>>> xmldoc = minidom.parse('~/diveintopython/common/py/kgp/binary.xml') 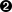 >>> xmldoc
>>> xmldoc  <xml.dom.minidom.Document instance at 010BE87C>
>>> print xmldoc.toxml()
<xml.dom.minidom.Document instance at 010BE87C>
>>> print xmldoc.toxml()  <?xml version="1.0" ?>
<grammar>
<ref id="bit">
<p>0</p>
<p>1</p>
</ref>
<ref id="byte">
<p><xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/>\
<xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/></p>
</ref>
</grammar>
<?xml version="1.0" ?>
<grammar>
<ref id="bit">
<p>0</p>
<p>1</p>
</ref>
<ref id="byte">
<p><xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/>\
<xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/></p>
</ref>
</grammar>
|
|
Comme vous l'avez vu dans la section précédente, cela importe le module minidom à partir du paquetage xml.dom.
|
|
|
Voici la ligne de code qui fait tout le travail : minidom.parse prend un argument et retourne une représentation analysée du document XML. Un argument peut recouvrir beaucoup de choses; dans ce cas, il s'agit du nom de fichier d'un document XML sur le disque local. (afin de poursuivre, il vous faudra modifier le chemin pour pointer vers votre répertoire d'exemples.)
Mais vous pouvez aussi lui passer un objet-fichier, ou même un pseudo objet-fichier. Vous tirerez avantage de cette souplesse plus loin dans ce chapitre.
|
|
|
L'objet retourné par minidom.parse est un objet Document, un descendant de la classe Node. Cet objet Document est la racine d'une structure pseudo-arborescente d'objets Python en relation qui représente complètement le document XML passé à minidom.parse.
|
|
|
toxml est une méthode de la classe Node (et donc disponible à partir de l'objet Document que vous obtenez de minidom.parse). toxml affiche les données XML représentées par ce Node. Pour le noeud Document, il affiche le document XML en entier.
|
Maintenant que vous avez un document XML en mémoire, vous pouvez commencer à le parcourir.
Exemple 9.9. Obtenir les noeuds enfants
>>> xmldoc.childNodes
[<DOM Element: grammar at 17538908>]
>>> xmldoc.childNodes[0]
<DOM Element: grammar at 17538908>
>>> xmldoc.firstChild
<DOM Element: grammar at 17538908>
|
|
Chaque Node possède un attribut childNodes, qui est une liste d'objets Node. Un Document n'a jamais qu'un noeud enfant : l'élément racine du document XML (dans ce cas, l'élément grammar).
|
|
|
Pour obtenir le premier (et, dans ce cas, le seul) noeud enfant, utilisez simplement la syntaxe normale des listes. Rappelez-vous
qu'il n'y a rien de particulier à ce sujet; il ne s'agit que d'une liste d'objets Python tout à fait normaux.
|
|
|
Puisqu'obtenir le premier noeud enfant d'un noeud parent est une action utile et courante, la classe Node possède un attribut firstChild, lequel est synonyme de childNodes[0]. (Il existe également un attribut lastChild, qui correspond à childNodes[-1].)
|
Exemple 9.10. toxml fonctionne pour tout noeud
>>> grammarNode = xmldoc.firstChild
>>> print grammarNode.toxml()
<grammar>
<ref id="bit">
<p>0</p>
<p>1</p>
</ref>
<ref id="byte">
<p><xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/>\
<xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/></p>
</ref>
</grammar>
|
|
Puisque la méthode toxml est définie dans la classe Node, elle vaut pour tout noeud XML et pas seulement pour l'élément Document.
|
Exemple 9.11. Les noeuds enfants peuvent être de type texte
>>> grammarNode.childNodes
[<DOM Text node "\n">, <DOM Element: ref at 17533332>, \
<DOM Text node "\n">, <DOM Element: ref at 17549660>, <DOM Text node "\n">]
>>> print grammarNode.firstChild.toxml()
>>> print grammarNode.childNodes[1].toxml()
<ref id="bit">
<p>0</p>
<p>1</p>
</ref>
>>> print grammarNode.childNodes[3].toxml()
<ref id="byte">
<p><xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/>\
<xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/></p>
</ref>
>>> print grammarNode.lastChild.toxml() 
|
|
A l'examen des éléments XML de binary.xml, vous pourriez penser que grammar a seulement deux noeuds enfants, les deux éléments ref. Mais vous oubliez quelque chose : les retours chariot ! Après '<grammar>' et avant le premier '<ref>' se trouve un retour chariot et ce texte compte comme un noeud enfant de l'élément grammar. De la même façon, il y a un retour charriot après chaque '</ref>'; il faut également les compter comme des noeuds enfants. Aussi grammar.childNodes correspond en réalité à une liste de 5 objets: 3 objets Text et 2 objets Element.
|
|
|
Le premier enfant est un objet Text qui représente le retour chariot après la balise '<grammar>' et avant la première balise '<ref>'.
|
|
|
Le deuxième enfant est un objet Element représentant le premier élément ref.
|
|
|
Le quatrième enfant est un objet Element représentant le second élément ref.
|
|
|
Le dernier enfant est un objet Text représentant le retour chariot après la dernière balise '</ref>' et avant la dernière balise '</grammar>'.
|
Exemple 9.12. Tracer une route jusqu'au texte
>>> grammarNode
<DOM Element: grammar at 19167148>
>>> refNode = grammarNode.childNodes[1]
>>> refNode
<DOM Element: ref at 17987740>
>>> refNode.childNodes
[<DOM Text node "\n">, <DOM Text node " ">, <DOM Element: p at 19315844>, \
<DOM Text node "\n">, <DOM Text node " ">, \
<DOM Element: p at 19462036>, <DOM Text node "\n">]
>>> pNode = refNode.childNodes[2]
>>> pNode
<DOM Element: p at 19315844>
>>> print pNode.toxml()
<p>0</p>
>>> pNode.firstChild
<DOM Text node "0">
>>> pNode.firstChild.data
u'0'
|
|
Comme vous l'aviez vu dans l'exemple précédent, le premier élément ref correspond à grammarNode.childNodes[1], puisque childNodes[0] est un noeud Text qui a pour valeur le retour chariot.
|
|
|
L'élément ref possède son propre ensemble de noeuds enfants : un pour le retour chariot, un autre pour les espaces, un troisième pour
l'élément p et ainsi de suite.
|
|
|
Vous pouvez même utiliser ici la méthode toxml, profondément imbriqué dans le document.
|
|
|
L'élément p possède un seul noeud enfant (vous ne pouvez pas dire cela de cet exemple, mais regardez le pNode.childNodes si vous en me croyez pas) et il s'agit du noeud Text représentant le caractère '0'.
|
|
|
L'attribut .data du noeud Text vous donne la chaîne de caractères représentée par le noeud texte. Mais que signifie le 'u' qui précède cette chaîne ? La réponse mérite d'être développée dans une section à part entière.
|