



I. Introduction▲
L'informatique est une discipline universitaire extrêmement vaste. Les domaines des systèmes distribués à l'échelle mondiale, de l'intelligence artificielle, de la robotique, du graphisme, de la sécurité, du calcul scientifique, de l'architecture informatique et des dizaines de sous-domaines émergents se développent chaque année avec de nouvelles techniques et des découvertes. Il n'y a que très peu d'aspects de la vie humaine qui n'ont pas été affectés par les progrès rapides de l'informatique. Le commerce, les communications, les sciences, les arts, les loisirs et la politique ont tous été réinventés en tant que domaines informatiques.
La haute productivité de l'informatique n'est possible que parce que la discipline repose sur un ensemble élégant et puissant d'idées fondamentales. Toute l'informatique commence par représenter l'information, spécifier la logique pour la traiter et concevoir des abstractions qui gèrent la complexité de cette logique. La maîtrise de ces fondamentaux nous obligera à comprendre précisément comment les ordinateurs interprètent les programmes informatiques et effectuent des calculs informatiques.
Ces idées fondamentales ont longtemps été enseignées en utilisant le manuel classique du MIT Structure et interprétation des programmes informatiques (Structure and Interpretation of Computer Programs (SICP)) écrit par Harold Abelson et Gerald Jay Sussman avec Julie Sussman. Ce tutoriel emprunte énormément à ce manuel, dont les auteurs originaux ont aimablement autorisé l'adaptation et la réutilisation sous une licence Creative Commons (CC BY-NC-SA).
I-A. Programmation en Python▲
Afin de définir des processus de calcul, nous avons besoin d'un langage de programmation, de préférence, un langage qu'un grand nombre d'humains et une grande variété d'ordinateurs peuvent tous comprendre. Dans ce tutoriel, nous travaillerons principalement avec le langage Python.
Python est un langage de programmation largement utilisé qui a recruté des amateurs de nombreuses professions : des programmeurs Web, des concepteurs de jeux, des scientifiques, des universitaires et même les concepteurs de nouveaux langages de programmation. Lorsque vous apprenez Python, vous rejoignez une grande communauté de développeurs, forte de plus d'un million de personnes. Les communautés de développeurs sont des institutions extrêmement importantes : les membres s'entendent pour résoudre des problèmes, partager leurs projets et leurs expériences et développer collectivement des logiciels et des outils. Les membres dévoués atteignent souvent la célébrité et l'estime généralisée grâce à leurs contributions.
Le langage Python lui-même est le produit d'une grande communauté bénévole qui se targue de la diversité de ses contributeurs. Le langage a été conçu et initialement mis en œuvre par Guido van Rossum à la fin des années 1980. Le premier chapitre de son didacticiel Python 3 explique pourquoi Python est si populaire, parmi les nombreux langages disponibles aujourd'hui.
Python excelle comme langage d'enseignement, car tout au long de son histoire, les développeurs de Python ont mis l'accent sur l'interprétation humaine du code Python, renforcée par le principe de beauté, de simplicité et de lisibilité du Zen of Python. Python est particulièrement approprié pour ce tutoriel, car son large éventail de fonctionnalités prend en charge une variété de styles de programmation différents, que nous explorerons. Bien qu'il n'y ait pas une seule manière de programmer en Python, il existe un ensemble de conventions partagées dans la communauté des développeurs qui facilitent la lecture, la compréhension et l'extension des programmes existants. Python combine une grande flexibilité et une accessibilité ce qui permet aux étudiants d'explorer de nombreux paradigmes de programmation, puis d'appliquer leurs connaissances nouvellement acquises à des milliers de projets en cours.
Ces notes maintiennent l'esprit du manuel SICP en présentant les caractéristiques de Python en phase avec les techniques d'abstraction et un modèle rigoureux de calcul. En outre, ces notes fournissent une introduction pratique à la programmation Python, y compris des fonctionnalités avancées du langage et des exemples illustratifs. Votre maîtrise de Python devrait se renforcer naturellement à mesure que vous avancez dans le tutoriel.
La meilleure façon de commencer la programmation en Python est d'interagir directement avec l'interpréteur. Cette section décrit comment installer Python 3, lancer une session interactive avec l'interpréteur et commencer la programmation.
I-B. Installation de Python 3▲
Comme pour tous grands logiciels, Python possède plusieurs versions. Ce tutoriel utilisera la version stable la plus récente de Python 3. De nombreux ordinateurs possèdent d'anciennes versions de Python, comme Python 2.7, mais celles-ci ne correspondent pas à ce qui est décrit dans ce tutoriel. Vous devriez pouvoir utiliser n'importe quel ordinateur, mais attendez-vous à installer Python 3. (Ne vous inquiétez pas, Python est gratuit.)
Vous pouvez télécharger Python 3 à partir de la page de téléchargement de Python en cliquant sur la version qui commence par 3 (pas 2). Suivez les instructions de l'installateur pour terminer l'installation.
Pour plus d'informations, essayez ces tutoriels vidéo sur l'installation Windows et l'installation Mac de Python 3, de Julia Oh.
I-C. Sessions interactives▲
Dans une session Python interactive, vous tapez un code Python après l'invite, >>>. L'interpréteur Python lit et exécute ce que vous avez saisi, en effectuant vos différentes commandes.
Pour lancer une session interactive, exécutez l'application Python 3. Tapez python3 dans une invite de commande (Mac / Unix / Linux) ou ouvrez l'application Python 3 dans Windows.
Si vous voyez l'invite Python, >>>, vous avez démarré une session interactive avec succès. Voici des exemples d'interactions à l'aide de l'invite, suivies d'une certaine entrée.
>>> 2 + 2
4Contrôles interactifs
Chaque session conserve un historique de ce que vous avez saisi. Pour accéder à cet historique, appuyez sur <Contrôle> -P (précédent) et <Contrôle> -N (suivant). <Control> -D ferme une session et efface l'historique de cette session. Les flèches haut et bas permettent également de remonter l'historique sur certains systèmes.
I-D. Premiers exemples▲
Pour bien introduire Python, nous allons commencer par un exemple qui utilise plusieurs fonctionnalités du langage. Dans la section suivante, nous commencerons de zéro et allons construire la langage pièce par pièce. Pensez à cette section comme une prévisualisation des fonctionnalités à venir.
Python dispose d'un support intégré pour une large gamme de sujets de programmation communs, tels que la manipulation de texte, l'affichage graphique et la communication sur internet. Dans cette ligne de code Python :
>>> from urllib.request import urlopenimport est une déclaration qui charge des fonctionnalités pour accéder aux données sur internet. En particulier, il met à disposition une fonction appelée urlopen, qui peut accéder au contenu d'une URL, un emplacement de quelque chose sur internet.
Instructions et expressions
Le code Python se compose d'expressions et d'instructions. D'une manière générale, les programmes informatiques sont constitués d'instructions, par exemple :
- calculer une valeur ;
- effectuer une action.
Les instructions décrivent généralement les actions. Lorsque l'interpréteur Python exécute une instruction, il exécute l'action correspondante. D'autre part, les expressions décrivent généralement les calculs. Lorsqu'un programme Python évalue une expression, il calcule la valeur de cette expression. Ce chapitre présente plusieurs types d'instructions et d'expressions.
L'instruction d'affectation >>> shakespeare = urlopen('http://composingprograms.com/shakespeare.txt')
associe le nom shakespeare à la valeur de l'expression qui suit le signe =. Cette expression applique la fonction urlopen à une URL qui contient le texte complet des 37 pièces de William Shakespeare, toutes dans un document texte unique.
Les fonctions
Les fonctions encapsulent la logique qui manipule les données. urlopen est une fonction. Une adresse web est une donnée, et le texte des pièces de Shakespeare est une autre donnée. Le processus par lequel le premier conduit à ce dernier peut être complexe, mais nous pouvons appliquer ce processus en utilisant uniquement une expression simple, car cette complexité est cachée dans une fonction. Les fonctions sont le sujet principal de ce chapitre.
Une autre déclaration d'affectation
>>> words = set(shakespeare.read().decode().split())associe le nom de variable words à l'ensemble de tous les mots uniques qui apparaissent dans les pièces de Shakespeare, chacun des 33 721 mots employés par Shakespeare dans ses œuvres. Dans la chaîne de commandes pour lire, décoder et diviser, les instructions individuelles fonctionnent chacune sur une entité de calcul intermédiaire : nous lisons les données à partir de l'URL ouverte, puis décodons les données en texte et enfin divisons le texte en mots. Tous ces mots sont placés dans un ensemble ou set.
Objets. Un set est un type d'objet, qui prend en charge les opérations définies, comme le calcul d'intersections ensemblistes et l'appartenance. Un objet regroupe naturellement les données et la logique qui manipule ces données, de manière à gérer la complexité des deux. Les objets sont le sujet principal d'un autre chapitre. Enfin, l'expression
2.
>>> {w for w in words if len(w) == 6 and w[::-1] in words}
{'redder', 'drawer', 'reward', 'diaper', 'repaid'}
est une expression composée qui évalue l'ensemble de tous les mots de six lettres de Shakespeare qui sont aussi un mot lorsqu'on les lit à l'envers, de droite à gauche (on les appelle palindromes). La notation cryptique w [:: - 1] énumère chaque lettre en un mot, mais le -1 dicte de reculer. Lorsque vous entrez une expression dans une session interactive, Python imprime sa valeur sur la ligne suivante.
Interpréteur
Évaluer des expressions composées nécessite une procédure précise qui interprète le code d'une façon prévisible. Un programme qui met en place ce genre de procédure, l'évaluation d'expressions composées, s'appelle un interpréteur (on dit aussi parfois interprète). La conception et la mise en œuvre d'interpréteurs fait l'objet d'un prochain chapitre.
Par rapport à d'autres programmes informatiques, les interpréteurs pour les langages de programmation sont uniques dans leur généralité. Python n'a pas été conçu avec Shakespeare. Cependant, sa grande flexibilité nous a permis de traiter une grande quantité de texte avec seulement quelques phrases et expressions.
En fin de compte, nous constatons que tous ces concepts de base sont étroitement liés : les fonctions sont des objets, des objets sont des fonctions et les interpréteurs sont des instances des deux. Cependant, développer une compréhension claire de chacun de ces concepts, et leur rôle dans l'organisation du code est essentiel pour maîtriser l'art de la programmation.
I-E. Les erreurs▲
Python attend votre commande. Vous êtes encouragé à expérimenter le langage, même si vous ne connaissez peut-être pas encore son vocabulaire complet et sa structure. Cependant, préparez-vous à des erreurs. Les ordinateurs sont certes extrêmement rapides et flexibles, ils sont également extrêmement rigides. La nature des ordinateurs est décrite dans le cours d'introduction de Stanford comme :
« L'équation fondamentale des ordinateurs est :
Ordinateur = puissant + stupide
Les ordinateurs sont très puissants, en examinant très rapidement les volumes de données. Les ordinateurs peuvent effectuer des milliards d'opérations par seconde, chaque opération étant assez simple.
Les ordinateurs sont également stupides et fragiles. Les opérations qu'ils peuvent effectuer sont extrêmement rigides, simples et mécaniques. L'ordinateur est complètement dépourvu de compréhension ou d'intuition... Un ordinateur ne ressemble en rien au calculateur HAL 9000 du film 2001, l'Odyssée de l'espace. S'il y a une chose que vous ne devez pas faire, c'est d'être intimidé par l'ordinateur comme s'il s'agissait d'une sorte de cerveau. C'est très mécanique sous le capot.
La programmation concerne une personne qui utilise sa vision réelle pour construire quelque chose d'utile, construit à partir de toutes petites opérations simples que l'ordinateur peut faire. »
La rigidité des ordinateurs apparaîtra immédiatement lorsque vous expérimentez l'interpréteur Python : même les modifications les plus minuscules d'orthographe et de mise en forme entraîneront des sorties et des erreurs inattendues.
Apprendre à interpréter les erreurs et à diagnostiquer la cause des erreurs inattendues s'appelle le débogage. Certains principes directeurs de débogage sont les suivants :
- Testez progressivement : chaque programme bien écrit est composé de petits modules qui peuvent être testés individuellement. Essayez tout ce que vous écrivez dans les plus brefs délais pour identifier les problèmes tôt et gagner confiance dans vos composants ;
- Isoler les erreurs : une erreur dans l'affichage d'une instruction peut généralement être attribuée à un module particulier. Lorsque vous essayez de diagnostiquer un problème, tracez l'erreur dans le plus petit fragment de code que vous pouvez avant d'essayer de le corriger ;
- Vérifiez vos hypothèses : les interpréteurs effectuent vos instructions à la lettre - pas plus et pas moins. Leur sortie est inattendue lorsque le comportement d'un code ne correspond pas à ce que le programmeur croit (ou suppose) que ce comportement soit. Maîtrisez vos hypothèses, puis concentrez vos efforts de débogage pour vérifier que vos hypothèses sont effectivement prises en compte ;
- Consultez les autres : vous n'êtes pas seul ! Si vous ne comprenez pas un message d'erreur, demandez à un ami, un instructeur ou un moteur de recherche. Si vous avez isolé une erreur, mais ne pouvez pas comprendre comment la corriger, demandez à quelqu'un d'autre de regarder. Beaucoup de connaissances de programmation précieuses sont partagées dans le processus de résolution de problèmes de groupe.
Les tests incrémentaux, la conception modulaire, les hypothèses précises et le travail en équipe sont des thèmes qui persistent tout au long de ce tutoriel. Espérons qu'ils persisteront également tout au long de votre carrière en informatique.
II. Les éléments de programmation▲
Un langage de programmation est plus qu'un moyen d'ordonner à un ordinateur d'effectuer des tâches. Le langage sert également de cadre au sein duquel nous organisons nos idées sur les processus informatiques. Les programmes servent à communiquer ces idées entre les membres d'une communauté de programmation. Ainsi, les programmes doivent être écrits pour être lus par les gens, et seulement à titre secondaire être exécutés par les machines.
Lorsque nous décrivons un langage, nous devons accorder une attention particulière aux techniques par lesquelles le langage permet de combiner des idées simples pour former des idées plus complexes. Tout langage puissant comporte trois de ces mécanismes :
- les expressions et instructions primitives, qui représentent les blocs de construction les plus simples que fournit le langage :
- les techniques de combinaison, par lesquelles les éléments complexes sont construits à partir d'éléments simples ;
- les techniques d'abstraction, par lesquelles les éléments composés peuvent être nommés et manipulés comme des entités.
En programmation, nous traitons deux types d'éléments : les fonctions et les données. (Bientôt, nous découvrirons qu'ils ne sont pas vraiment si distincts que cela.) Informellement, les données sont des choses que nous voulons manipuler, et les fonctions décrivent les règles de manipulation des données. Ainsi, tout langage de programmation puissant devrait pouvoir décrire des données primitives et des fonctions primitives, ainsi que certaines méthodes pour combiner et abstraire les fonctions et les données.
II-A. Les expressions▲
Après avoir expérimenté l'interpréteur complet de Python dans le chapitre précédent, nous abordons méthodiquement le langage Python élément par élément. Soyez patient si les exemples semblent simplistes - un matériel plus excitant viendra.
Nous commençons avec des expressions primitives. Une sorte d'expression primitive est un nombre. Plus précisément, l'expression que vous saisissez consiste en des chiffres qui représentent le nombre dans la base 10.
>>> 42
42Les expressions représentant des nombres peuvent être combinées avec des opérateurs mathématiques pour former une expression composée, que l'interpréteur évaluera :
>>> -1 - -1
0
>>> 1/2 + 1/4 + 1/8 + 1/16 + 1/32 + 1/64 + 1/128
0.9921875Ces expressions mathématiques utilisent la notation infixée, où l'opérateur (par exemple, +, -, * ou /) apparaît entre les opérandes (nombres). En programmation Python, il y a plusieurs façons de former des expressions composées. Plutôt que d'essayer de les énumérer tout de suite, nous allons présenter de nouvelles formes d'expressions au fur et à mesure, ainsi que les fonctionnalités que supporte le langage.
II-B. Les expressions d'appel▲
Le type d'expression composée le plus important est une expression d'appel, qui applique une fonction à des arguments. Rappelons de l'algèbre que la notation mathématique d'une fonction est une correspondance entre certains arguments d'entrée et une valeur de sortie. Par exemple, la fonction max fait correspondre ses entrées à une sortie unique, qui est la plus grande des entrées. La façon dont Python exprime l'application de la fonction est la même que dans les mathématiques conventionnelles.
>>> max(7.5, 9.5)
9.5Cette expression d'appel comporte des sous-expressions : l'opérateur est une expression qui précède les parenthèses et qui renferme une liste, délimitée par des virgules, d'expressions d'opérande.
L'opérateur spécifie une fonction. Lorsque cette expression d'appel est évaluée, on dit que la fonction max est appelée avec les arguments 7.5 et 9.5 et renvoie la valeur 9.5.
L'ordre des arguments dans une expression d'appel est important. Par exemple, la fonction pow élève son premier argument à la puissance de son second argument.
La notation de fonction a trois avantages principaux par rapport à la convention mathématique de la notation infixée. Tout d'abord, les fonctions peuvent prendre un nombre arbitraire d'arguments :
>>> max(1, -2, 3, -4)
3Aucune ambiguïté ne peut se produire, car le nom de la fonction précède toujours ses arguments.
Deuxièmement, la notation de fonction s'étend de manière simple aux expressions imbriquées, où les éléments sont eux-mêmes des expressions composées. Dans les expressions d'appel imbriquées, contrairement aux expressions infixes composées, la structure de l'imbrication est entièrement explicite en raison des parenthèses.
Il n'y a pas de limite (en principe) à la profondeur d'une telle imbrication et à la complexité globale des expressions que l'interpréteur Python peut évaluer. Cependant, les humains sont vite perdus avec des imbrications multiniveaux. Un rôle important pour vous en tant que programmeur est de structurer les expressions afin qu'elles restent interprétables par vous, vos partenaires de programmation et d'autres personnes qui peuvent lire vos expressions à l'avenir.
Troisièmement, la notation mathématique a une grande variété de formes : la multiplication apparaît entre les termes, les exposants apparaissent décalés vers le haut, la division en tant que barre horizontale et une racine carrée comme toiture avec un revêtement oblique. Une partie de cette notation est très difficile à taper au clavier ! Cependant, toute cette complexité peut être unifiée via la notation des expressions d'appel. Alors que Python prend en charge les opérateurs mathématiques courants utilisant la notation infixée (comme + et -), tout opérateur peut être exprimé comme une fonction avec un nom.
II-C. Importation de fonctions de bibliothèque▲
Python définit un très grand nombre de fonctions, y compris les fonctions opérateurs mentionnées dans la section précédente, mais ne les rend pas toutes disponibles par défaut. Au lieu de cela, il organise les fonctions et les autres données qu'il connaît en modules, qui composent ensemble la bibliothèque Python. Pour utiliser ces éléments, on les importe. Par exemple, le module math offre une variété de fonctions mathématiques familières :
2.
3.
>>> from math import sqrt
>>> sqrt(256)
16.0
Et le module operator permet d'accéder aux fonctions correspondantes aux opérateurs infixés :
2.
3.
4.
5.
>>> from operator import add, sub, mul
>>> add(14, 28)
42
>>> sub(100, mul(7, add(8, 4)))
16
Une déclaration import désigne un nom de module (par exemple, operator ou math), puis liste les attributs nommés de ce module à importer (par exemple, sqrt). Une fois qu'une fonction est importée, elle peut être appelée plusieurs fois.
Il n'y a pas de différence entre l'utilisation de ces fonctions de l'opérateur (par exemple, add) et les symboles de l'opérateur eux-mêmes (par exemple, +). D'une manière conventionnelle, la plupart des programmeurs utilisent des symboles et la notation infixée pour exprimer une expression arithmétique simple.
La documentation Python 3 répertorie les fonctions définies par chaque module, tel que le module math. Cependant, cette documentation est écrite pour les développeurs qui connaissent bien le langage. Pour l'instant, vous constaterez peut-être que l'expérimentation d'une fonction vous informe davantage de son comportement que de la lecture de la documentation. À mesure que vous vous familiarisez avec le langage et le vocabulaire de Python, cette documentation deviendra une source de référence précieuse.
II-D. Noms et environnements▲
Un aspect critique d'un langage de programmation est le moyen qu'il fournit pour utiliser des noms permettant de se référer à des objets de calcul. Si une valeur a été attribuée à un nom, on dit que le nom est lié à la valeur.
En Python, nous pouvons établir de nouvelles liaisons en utilisant l'instruction d'affectation, qui contient un nom à gauche du signe = et une valeur à droite
>>> radius = 10
>>> radius
10
>>> 2 * radius
20Les noms sont également liés par des déclarations import
>>> from math import pi
>>> pi * 71 / 223
1.0002380197528042Le symbole = est appelé opérateur d'affectation en Python (et dans beaucoup d'autres langages). L'affectation est notre moyen d'abstraction le plus simple, car il nous permet d'utiliser des noms simples pour se référer aux résultats des opérations composées, comme la donnée area ci-dessus. De cette façon, les programmes complexes sont définis en construisant, étape par étape, des objets informatiques de plus en plus complexes.
La possibilité de lier des noms aux valeurs et ensuite de récupérer ces valeurs par leur nom signifie que l'interpréteur doit conserver une sorte de mémoire qui surveille les noms, les valeurs et les liaisons. Cette mémoire s'appelle un environnement.
Les noms peuvent également être liés aux fonctions. Par exemple, le nom max est lié à la fonction maximale que nous utilisons. Les fonctions, contrairement aux nombres, sont difficiles à rendre en tant que texte, de sorte que Python imprime une description d'identification à la place, lorsqu'on lui demande de décrire une fonction :
Nous pouvons utiliser les instructions d'affectation pour donner un nom additionnel à des fonctions existantes.
Et les instructions d'affectation successives peuvent lier un nom à une nouvelle valeur.
2.
3.
>>> f = 2
>>> f
2
En programmation Python, les noms sont souvent appelés noms de variables ou variables, car ils peuvent être liés à des valeurs différentes au cours de l'exécution d'un programme. Lorsqu'un nom est lié à une nouvelle valeur par une affectation, il n'est plus lié à aucune valeur précédente. On peut même lier des noms intégrés à de nouvelles valeurs.
Après cette affectation, le nom max n'est plus lié à une fonction, si bien qu'essayer d'appeler max(2, 3, 4) causerait une erreur.
Nous pouvons également affecter plusieurs valeurs à plusieurs noms en une seule instruction, où les noms à gauche de = et les expressions à droite du signe = sont séparés par des virgules.
2.
3.
4.
5.
>>> area, circumference = pi * radius * radius, 2 * pi * radius
>>> area
314.1592653589793
>>> circumference
62.83185307179586
La modification de la valeur d'un nom n'affecte pas d'autres noms. Ci-dessous, même si le nom area était originellement lié à une valeur définie à sa création comme radius, la valeur de area n'a pas changé. La mise à jour de la valeur de area nécessite une autre instruction d'affectation.
2.
3.
4.
5.
>>> radius = 11
>>> area
314.1592653589793
>>> area = pi * radius * radius
380.132711084365
En cas d'affectations multiples, toutes les expressions à droite de l'opérateur = sont évaluées avant que l'un quelconque des noms à gauche de l'affectation ne soit lié à ces valeurs. Il en résulte qu'il est possible d'intervertir les valeurs liées à deux noms en une seule instruction :
>>> x, y = 3, 4.5
>>> y, x = x, y
>>> x
4.5
>>> y
3II-E. Évaluation des expressions imbriquées▲
L'un de nos objectifs dans cette section est d'isoler les problèmes associés à la façon procédurale de penser. À titre d'exemple, considérons que, lors de l'évaluation des expressions d'appel imbriquées, l'interpréteur suit lui-même une procédure.
Pour évaluer une expression d'appel, Python effectuera les opérations suivantes :
- évaluer les sous-expressions de l'opérateur et de l'opérande ;
- appliquer la fonction qui est la valeur de la sous-expression de l'opérateur aux arguments qui sont les valeurs des sous-expressions de l'opérande.
Même cette procédure simple illustre certains points importants concernant les processus en général. La première étape dicte que, pour accomplir le processus d'évaluation pour une expression d'appel, nous devons d'abord évaluer d'autres expressions. Ainsi, la procédure d'évaluation est de nature récursive, c'est-à-dire qu'elle inclut, comme une de ses étapes, la nécessité d'invoquer la règle elle-même.
Par exemple, évaluer
exige que cette procédure d'évaluation soit appliquée quatre fois. Si nous dessinons chaque expression que nous évaluons, nous pouvons visualiser la structure hiérarchique de ce processus.
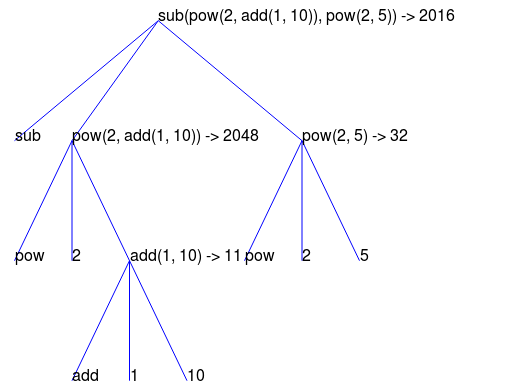
Cette illustration s'appelle un arbre d'expressions. En informatique, les arbres se développent traditionnellement de haut en bas. Les objets à chaque point d'un arbre s'appellent des nœuds. Dans ce cas, ce sont des expressions associées à leurs valeurs.
L'évaluation de sa racine, l'expression complètement en haut, nécessite d'abord d'évaluer les branches qui sont ses sous-expressions. Les expressions de feuilles (c'est-à-dire les nœuds sans branches qui en découlent) représentent soit des fonctions, soit des nombres. Les nœuds intérieurs ont deux parties : l'expression d'appel à laquelle notre règle d'évaluation est appliquée et le résultat de cette expression. En regardant l'évaluation en fonction de cet arbre, nous pouvons imaginer que les valeurs des opérandes remontent vers le haut, en partant des nœuds terminaux puis en combinant les niveaux supérieurs.
Ensuite, observez que l'application répétée de la première étape nous amène au point où nous devons évaluer, non pas des expressions d'appel, mais des expressions primitives telles que des chiffres (par exemple, 2) et des noms (par exemple, add). Nous prenons soin des cas primitifs en stipulant que :
- une donnée numérique s'évalue au nombre qu'elle désigne ;
- un nom s'évalue à la valeur associée à ce nom dans l'environnement actuel.
Notez le rôle important d'un environnement dans la détermination de la signification des symboles dans les expressions. En programmation Python, la valeur d'une expression telle que
>>> add(x, 1)n'a pas de sens sans préciser d'informations sur l'environnement qui fourniraient une signification pour le nom x (ou même pour add). Les environnements fournissent le contexte dans lequel se déroule l'évaluation, ce qui joue un rôle important dans notre compréhension de l'exécution du programme.
Cette procédure d'évaluation ne suffit pas pour évaluer tout le code Python, seulement les expressions d'appel, les chiffres et les noms. Par exemple, il ne gère pas les instructions d'affectation. L'exécution de >>> x = 3 ne renvoie pas une valeur ni n'évalue une fonction sur certains arguments, puisque le but de l'affectation est plutôt de lier un nom à une valeur. En général, les instructions ne sont pas évaluées mais exécutées. Ce code ne produit pas de valeur, mais plutôt un changement de valeur. Chaque type d'expression ou d'instructions a sa propre procédure d'évaluation ou d'exécution.
Quand on dit que "une donnée numérique s'évalue à un nombre", nous voulons dire que l'interpréteur Python évalue une donnée numérique à un nombre. C'est l'interpréteur qui donne du sens au langage de programmation. Étant donné que l'interpréteur est un programme fixe, on peut dire que les chiffres (et les expressions) eux-mêmes s'évaluent à leurs valeurs dans le contexte des programmes Python.
II-F. La fonction d'impression▲
Tout au long de ce tutoriel, nous distinguerons deux types de fonctions : les fonctions pures et les fonctions non pures
Les fonctions pures. Les fonctions ont une certaine entrée (leurs arguments) et renvoient certaines sorties (suite à leur application). La fonction intégrée
2.
abs(-2)
2
peut être représenté comme une petite machine qui prend des entrées et produit des résultats.

La fonction abs est pure. Avec les fonctions pures, l'application n'a aucun autre effet que de renvoyer une valeur. En outre, une fonction pure doit toujours retourner la même valeur lorsqu'elle est appelée deux fois avec les mêmes arguments.
Les fonctions non-pure. En plus de renvoyer une valeur, l'application d'une fonction non pure peut générer des effets secondaires, ce qui modifie l'état de l'interpréteur ou de l'ordinateur. Un effet secondaire commun est de générer une sortie supplémentaire en plus de la valeur de retour, en utilisant la fonction print.
Bien que print et abs semblent être similaires dans ces exemples, ils fonctionnent de manière fondamentalement différente. La valeur que print renvoie est toujours None, une valeur Python spéciale qui ne représente rien. L'interpréteur interactif Python n'imprime pas la valeur None. Dans le cas de print, la fonction elle-même consiste à imprimer la sortie comme un effet secondaire de l'appel.
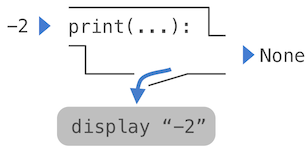
Une expression imbriquée d'appels de print met en évidence le caractère non pur de la fonction.
>>> print(print(1), print(2))
1
2
None NoneSi vous trouvez que cette sortie est inattendue, tracez un arbre d'expressions pour préciser pourquoi l'évaluation de cette expression produit cette sortie particulière.
Soyez prudent avec print ! Le fait qu'il renvoie None signifie qu'il ne doit pas être l'expression dans une instruction d'affectation.
>>> two = print(2)
2
>>> print(two)
NoneLes fonctions pures sont limitées dans la mesure où elles ne peuvent pas avoir des effets secondaires ou modifier le comportement au fil du temps. L'imposition de ces restrictions entraîne des avantages considérables. Tout d'abord, les fonctions pures peuvent être composées de manière plus fiable dans les expressions d'appel composites. On peut voir dans l'exemple de fonction non pure ci-dessus que print ne renvoie pas un résultat utile lorsqu'il est utilisé dans une opérande. Nous avons vu en revanche que des fonctions telles que max, pow et sqrt peuvent être utilisées efficacement dans des expressions imbriquées
Deuxièmement, les fonctions pures ont tendance à être plus simples à tester. Une liste d'arguments entraînera toujours la même valeur de retour, qui peut être comparée à la valeur de retour attendue. Les tests sont examinés plus en détail plus loin dans ce chapitre.
Troisièmement, un chapitre ultérieur vous montrera que les fonctions pures sont essentielles pour l'écriture de programmes concurrents, dans lesquels plusieurs expressions d'appel peuvent être évaluées simultanément
Pour ces raisons, nous nous concentrons fortement sur la création et l'utilisation de fonctions pures dans le reste de ce chapitre. La fonction print n'est utilisée que pour pouvoir afficher les résultats intermédiaires des calculs.
III. Définir de nouvelles fonctions▲
Nous avons identifié dans Python certains des éléments qui doivent apparaître dans n'importe quel langage de programmation puissant :
- Les nombres et les opérations arithmétiques sont des valeurs et des fonctions intégrées ;
- L'application de fonctions imbriquées fournit un moyen de combiner les opérations ;
- Le fait de lier des noms aux valeurs fournit un moyen d'abstraction limité.
Maintenant, nous allons aborder la définition des fonctions, une technique d'abstraction beaucoup plus puissante par laquelle un nom peut être lié à une opération composée, qui peut alors être appelée comme une unité.
Nous commençons par examiner comment exprimer l'idée d'élever une valeur au carré. Nous pourrions dire: « Pour obtenir le carré de quelque chose, multipliez-le par lui-même ». Cela s'exprime en Python comme suit :
>>> def square(x):
return mul(x, x)Ce programme définit une nouvelle fonction nommée square. Cette fonction définie par l'utilisateur n'est pas intégrée à l'interpréteur. Il représente l'opération qui consiste à multiplier quelque chose par lui-même. Le x dans cette définition est appelé un paramètre formel, qui fournit un nom pour que la chose soit multipliée. La définition crée cette fonction définie par l'utilisateur et l'associe au nom square.
Comment définir une fonction. Les définitions de fonction sont constituées d'une instruction def qui indique un <nom> et une liste de <paramètres formels> nommés, une instruction return, appelée corps de la fonction, qui spécifie l' <expression de retour> de la fonction, qui est une expression à évaluer chaque fois que la fonction est appliquée :
def <name>(<formal parameters>):
return <return expression>La deuxième ligne doit être indentée - la plupart des programmeurs utilisent quatre espaces pour indenter. L'expression de retour n'est pas évaluée immédiatement. Elle est stockée comme partie de la fonction nouvellement définie et évaluée uniquement lorsque la fonction est finalement appliquée.
Ayant défini la fonction square, on peut l'appliquer avec une expression d'appel :
>>> square(21)
441
>>> square(add(2, 5))
49
>>> square(square(3))
81Nous pouvons également utiliser square comme bloc de construction pour définir d'autres fonctions. Par exemple, nous pouvons facilement définir une fonction sum_squares, qui reçoit deux nombres comme arguments et renvoie la somme de leurs carrés :
>>> def sum_squares(x, y):
return add(square(x), square(y))
>>> sum_squares(3, 4)
25Les fonctions définies par l'utilisateur sont utilisées exactement de la même manière que les fonctions intégrées. En effet, on ne peut pas dire à partir de la définition de sum_squares si square est intégré à l'interpréteur, importé à partir d'un module ou défini par l'utilisateur.
Les instructions def et les instructions d'affectation lient les noms aux valeurs et les liaisons existantes sont perdues. Par exemple, g ci-dessous se réfère à une fonction sans arguments, puis à un nombre, puis à une fonction à deux arguments.
>>> def g():
return 1
>>> g()
1
>>> g = 2
>>> g
2
>>> def g(h, i):
return h + i
>>> g(1, 2)
3III-A. Environnements▲
Notre sous-ensemble de Python est maintenant suffisamment complexe pour que la signification des programmes ne soit pas évidente. Que faire si un paramètre formel a le même nom qu'une fonction intégrée ? Deux fonctions peuvent-elles partager des noms sans confusion ? Pour résoudre ces questions, nous devons décrire de façon plus détaillé les environnements.
Un environnement dans lequel une expression est évaluée est constitué d'une séquence de cadres, représentée sous forme de boîtes. Chaque cadre contient des liaisons, chacun associant un nom avec sa valeur correspondante. Il existe un seul cadre global. Les instructions d'affectation et d'importation ajoutent des entrées au premier cadre de l'environnement actuel. Jusqu'à présent, notre environnement est constitué uniquement du cadre global.
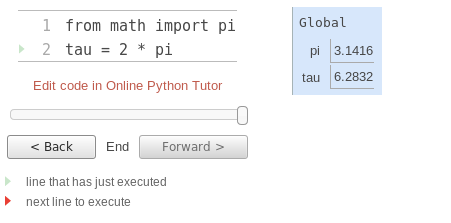
Ce diagramme d'environnement montre les liaisons de l'environnement actuel, ainsi que les valeurs auxquelles les noms sont liés. Vous pouvez cliquer sur le lien « Modifier le code avec Online Python Tutor » pour charger l'exemple dans le didacticiel avec Online Pyton Tutor, un outil créé par Philip Guo pour générer ces diagrammes d'environnement. Vous êtes encouragés à créer des exemples vous-même et à étudier les diagrammes environnementaux qui en résultent.
Les fonctions apparaissent aussi dans les diagrammes environnementaux. Une instruction import lie un nom à une fonction intégrée. Une instruction def lie un nom à une fonction définie par l'utilisateur. L'environnement résultant de l'importation de mul et de la définition de square est le suivant :
|
Sélectionnez 1. 2. 3. |
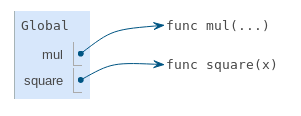 |
Chaque fonction est une ligne qui commence par func, suivie du nom de la fonction et des paramètres formels. Les fonctions intégrées telles que mul ne possèdent pas de noms de paramètres formels, et donc (...) est toujours utilisé à la place.
Le nom d'une fonction est répété deux fois, une fois dans le cadre et à nouveau comme partie de la fonction elle-même. Le nom apparaissant dans la fonction s'appelle : le nom intrinsèque. Le nom dans un cadre est un nom lié. Il existe une différence entre les deux : différents noms peuvent se référer à la même fonction, mais cette fonction elle-même n'a qu'un seul nom intrinsèque.
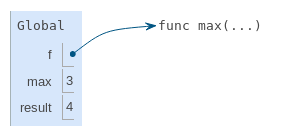
Le nom lié à une fonction dans un cadre est celui utilisé lors de l'évaluation. Le nom intrinsèque d'une fonction ne joue pas un rôle dans l'évaluation. Dans l'exemple ci-dessous, vous constaterez qu'une fois que le nom max est lié à la valeur 3, il ne peut plus être utilisé comme fonction.
 |
|
Un message d'erreur TypeError: 'int' object is not callable signale que le nom max (actuellement lié au nombre 3) est un nombre entier et non une fonction. Par conséquent, il ne peut pas être utilisé comme opérateur dans une expression d'appel.
Signatures de fonctions. Les fonctions diffèrent selon le nombre d'arguments qu'elles peuvent prendre. Pour suivre ces exigences, nous dessinons chaque fonction d'une manière qui montre le nom de la fonction et ses paramètres formels. La fonction square définie par l'utilisateur ne prend que x. Fournir plus ou moins d'arguments entraînera une erreur. Une description des paramètres formels d'une fonction est appelée signature de la fonction.
La fonction max peut prendre un nombre arbitraire d'arguments. Il est rendu comme max (...). Indépendamment du nombre d'arguments pris, toutes les fonctions intégrées seront rendues comme <nom> (...), car ces fonctions primitives n'ont jamais été explicitement définies.
III-B. Appel des fonctions définies par l'utilisateur▲
Pour évaluer une expression d'appel dont l'opérateur nomme une fonction définie par l'utilisateur, l'interpréteur Python suit un processus de calcul. Comme pour toute expression d'appel, l'interpréteur évalue les expressions opérateur et opérande, puis applique la fonction nommée aux arguments résultants.
L'application d'une fonction définie par l'utilisateur introduit une deuxième trame locale, qui n'est accessible qu'à cette fonction. Pour appliquer une fonction définie par l'utilisateur à certains arguments :
- Reliez les arguments aux noms des paramètres formels de la fonction dans un nouveau cadre local ;
- Exécutez le corps de la fonction dans l'environnement qui commence par ce cadre.
L'environnement dans lequel le corps est évalué se compose de deux cadres : d'abord, le cadre local qui contient des liaisons de paramètres formels, puis le cadre global qui contient tout le reste. Chaque instance d'une application de fonction a son propre cadre local et est indépendante.
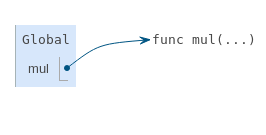
Pour illustrer un exemple en détail, plusieurs étapes du diagramme d'environnement pour le même exemple sont décrites ci-dessous. Après avoir exécuté la première déclaration import, seul le nom mul est lié dans le cadre global.
|
Sélectionnez 1. 2. 3. 4. |
 |
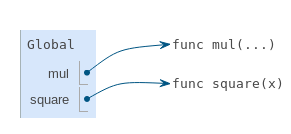
Tout d'abord, l'instruction de définition de la fonction square est exécutée. Notez que toute la déclaration def est traitée en une seule étape. Le corps d'une fonction n'est pas exécuté tant que la fonction n'est pas appelée (il n'est donc pas exécuté quand elle est définie).
|
Sélectionnez 1. 2. 3. 4. |
 |
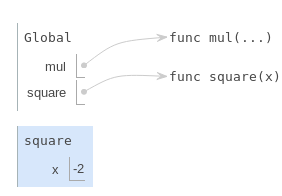
Ensuite, la fonction square est appelée avec l'argument -2, et donc un nouveau cadre est créé avec le paramètre formel x lié à la valeur -2.
|
Sélectionnez 1. 2. 3. 4. |
 |
Ensuite, le nom x est recherché dans l'environnement actuel, qui se compose des deux cadres. Dans les deux occurrences, x est évalué à -2 et la fonction square retourne 4.
|
Sélectionnez 1. 2. 3. 4. |
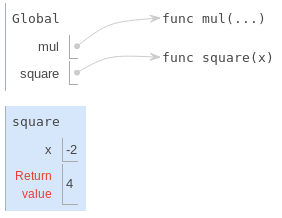 |
La "valeur de retour" dans le cadre square() n'est pas une liaison de nom. Ce cadre indique plutôt la valeur retournée par l'appel de fonction qui a créé le cadre.
Même dans ce simple exemple, deux environnements différents sont utilisés. L'expression supérieure square(-2) est évaluée dans l'environnement global, tandis que l'expression de retour mul (x, x) est évaluée dans l'environnement créé par l'appel de square. x et mul sont tous les deux liés dans cet environnement, mais dans des cadres différents.
L'ordre des cadres dans un environnement affecte la valeur renvoyée en recherchant un nom dans une expression. Nous avons indiqué précédemment qu'un nom est évalué à la valeur qui lui est associée dans l'environnement actuel. Nous pouvons maintenant être plus précis sur l'évaluation des noms. Un nom évalue la valeur qui lui est liée dans le premier cadre de l'environnement actuel dans lequel ce nom se trouve.
Notre cadre conceptuel d'environnements, de noms et de fonctions constitue un modèle d'évaluation. Tandis que certains détails mécaniques sont encore non spécifiés (par exemple, comment une liaison est implémentée), notre modèle décrit précisément et correctement comment l'interpréteur évalue les expressions d'appel. Dans un autre tutoriel de cette série, nous verrons comment ce modèle peut servir de plan pour la mise en œuvre d'un interpréteur fonctionnant pour un langage de programmation.
III-C. Exemple : appeler une fonction définie par l'utilisateur▲
Considérons nos deux définitions de fonctions simples et illustrons le processus qui évalue une expression d'appel pour une fonction définie par l'utilisateur.
|
Sélectionnez 1. 2. 3. 4. 5. 6. 7. 8. |
 |
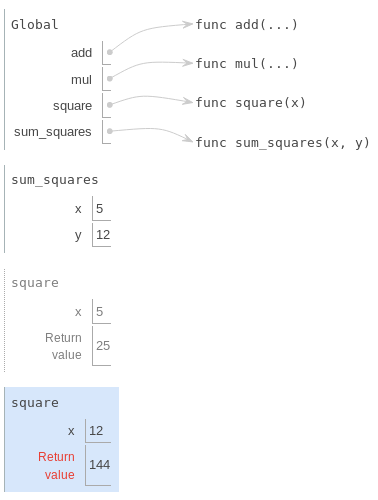
Python évalue d'abord le nom sum_squares, qui est lié à une fonction définie par l'utilisateur dans le cadre global. Les expressions numériques primitives 5 et 12 évaluent les nombres qu'ils représentent.
Ensuite, Python applique sum_squares, qui introduit un cadre local qui lie x à 5 et y à 12.
|
Sélectionnez 1. 2. 3. 4. 5. 6. 7. 8. |
 |
Le corps de la fonction sum_squares contient cette expression d'appel :
add ( square(x) , square(y) )
________ _________ _________
operator operand 0 operand 1
Les trois sous-expressions sont évaluées dans l'environnement actuel, qui commence par le cadre nommé sum_squares (). L'opérateur add est un nom trouvé dans le cadre global, lié à la fonction intégrée pour l'addition. Les deux sous-expressions d'opérande doivent être évaluées à leur tour, avant que l'addition ne soit appliquée. Les deux opérandes sont évaluées dans l'environnement actuel en commençant par le cadre intitulé sum_squares.
Dans l'opérande 0, la fonction square nomme une fonction définie par l'utilisateur dans le cadre global, tandis que x vaut 5 dans le cadre local. Python applique square à 5 en introduisant encore un autre cadre local qui lie x à 5.
|
Sélectionnez 1. 2. 3. 4. 5. 6. 7. |
 |
En utilisant cet environnement, l'expression mul (x, x) est évaluée à 25.
Notre procédure d'évaluation se tourne maintenant vers l'opérande 1, pour lequel y désigne le nombre 12. Python évalue de nouveau le corps de square, introduisant cette fois encore un autre cadre local qui lie x à 12. Par conséquent, l'opérande 1 vaut 144.
|
Sélectionnez 1. 2. 3. 4. 5. 6. |
 |
Enfin, l'application de l'addition aux arguments 25 et 144 donne une valeur de retour finale pour sum_squares : 169.
|
Sélectionnez 1. 2. 3. 4. 5. 6. 7. |
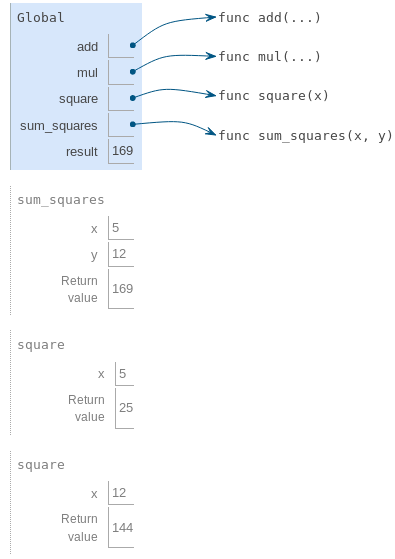 |
Cet exemple illustre bien des idées fondamentales que nous avons développées jusqu'à présent. Les noms sont liés à des valeurs, qui sont réparties sur plusieurs cadres locaux indépendants, avec un seul cadre global contenant des noms partagés. Un nouveau cadre local est introduit chaque fois qu'une fonction est appelée, même si la même fonction est appelée deux fois.
Tout ce mécanisme existe pour s'assurer que les noms contiennent les valeurs correctes au bon moment pendant l'exécution du programme. Cet exemple illustre pourquoi notre modèle nécessite la complexité que nous avons introduite. Les trois cadres locaux contiennent une liaison pour le nom x, mais ce nom est lié à des valeurs différentes dans des cadres différents. Les cadres locaux gardent ces noms séparés.
III-D. Les noms locaux▲
Un détail de la mise en œuvre d'une fonction qui ne doit pas affecter le comportement de la fonction est le choix des noms pour les paramètres formels de la fonction. Ainsi, les fonctions suivantes doivent fournir le même comportement:
2.
3.
4.
>>> def square(x):
return mul(x, x)
>>> def square(y):
return mul(y, y)
Ce principe selon lequel la signification d'une fonction doit être indépendante des noms de paramètres choisis par son auteur a des conséquences importantes pour les langages de programmation. La conséquence la plus simple est que les noms de paramètres d'une fonction doivent rester locaux au corps de la fonction.
Si les paramètres n'étaient pas locaux aux corps de leurs fonctions respectives, le paramètre x dans square pourrait être confondu avec le paramètre x dans sum_squares. Ce n'est pas le cas et c'est essentiel : les différentes liaisons pour x dans différents cadres locaux sont indépendantes. Le modèle de calcul est soigneusement conçu pour assurer cette indépendance.
Nous disons que la portée d'un nom local est limitée au corps de la fonction définie par l'utilisateur qui la définit. Lorsqu'un nom n'est plus accessible, il est hors de portée. Ce comportement de portée n'est pas un fait nouveau au sujet de notre modèle. C'est une conséquence de la façon dont les environnements fonctionnent.
III-E. Choix des noms▲
L'interchangeabilité des noms n'implique pas que les noms de paramètres formels n'importent pas du tout. Au contraire, les fonctions et les noms de paramètres bien choisis sont essentiels pour l'interprétation humaine des définitions de fonctions !
Les directives suivantes sont adaptées au guide de style pour la programmation Python, qui sert de guide pour tous les programmeurs Python (non-rebelles). Un ensemble de conventions partagé facilite la communication entre les membres d'une communauté de développeurs. Comme effet secondaire de suivre ces conventions, vous constaterez que votre code devient intrinsèquement plus cohérent.
- Les noms de fonctions sont en minuscules, avec des mots séparés par des caractères de soulignement. Les noms descriptifs sont encouragés.
- Les noms de fonctions évoquent généralement les opérations appliquées aux arguments par l'interpréteur (par exemple, print, add, square) ou le nom de la quantité qui résulte (par exemple, max, abs, sum).
- Les noms de paramètres sont en minuscules, avec des mots séparés par des caractères de soulignement. Les mots simples (un seul mot) sont préférés.
- Les noms de paramètres doivent évoquer le rôle du paramètre dans la fonction, pas seulement le type d'argument autorisé.
- Les noms de paramètres de lettre unique sont acceptables lorsque leur rôle est évident, mais évitez "l" (L minuscule), "O" (O majuscule) ou "I" (i majuscule) pour éviter toute confusion avec les chiffres.
Il existe de nombreuses exceptions à ces directives, même dans la bibliothèque standard de Python. Comme le vocabulaire de la langue anglaise, Python a hérité des mots d'une variété de contributeurs, et le résultat n'est pas toujours cohérent.
III-F. Fonctions comme abstractions▲
Bien qu'elle soit très simple, la fonction sum_squares illustre la propriété la plus puissante des fonctions définies par l'utilisateur. La fonction sum_squares est définie à partir de la fonction square, mais repose uniquement sur la relation que la fonction square définit entre ses arguments d'entrée et ses valeurs de sortie.
Nous pouvons écrire sum_squares sans nous préoccuper de la façon dont on obtient le carré d'un nombre. Les détails de la façon dont le carré est calculé peuvent être supprimés, être pris en considération ultérieurement. En effet, du point de vue de sum_squares, la fonction square n'est pas un corps de fonction particulier, mais plutôt une abstraction d'une fonction, une abstraction dite fonctionnelle. À ce niveau d'abstraction, toute fonction qui calcule le carré est tout aussi bonne.
Ainsi, si l'on s'intéresse uniquement aux valeurs qu'elles renvoient, les deux fonctions suivantes d'élévation au carré d'un nombre doivent être indiscernables. Chacune prend un argument numérique et produit le carré de ce nombre comme valeur.
2.
3.
4.
>>> def square(x):
return mul(x, x)
>>> def square(x):
return mul(x, x-1) + x
Autrement dit, une définition de fonction doit pouvoir supprimer les détails. Les utilisateurs de la fonction peuvent ne pas l'avoir écrite eux-mêmes, mais peuvent l'avoir obtenue auprès d'un autre programmeur comme une "boîte noire". Un programmeur ne doit pas avoir besoin de savoir comment la fonction est implémentée pour l'utiliser. La bibliothèque Python possède cette propriété. De nombreux développeurs utilisent les fonctions qui y sont définies, mais peu d'entre eux inspectent leur implémentation.
Abordons les aspects d'une abstraction fonctionnelle. Pour maîtriser l'utilisation d'une abstraction fonctionnelle, il est souvent utile de considérer ses trois attributs principaux. Le domaine d'une fonction est l'ensemble des arguments qu'il peut prendre. La gamme d'une fonction est l'ensemble de valeurs qu'elle peut retourner. L'intention ou l'objectif d'une fonction est la relation qu'elle établit entre les entrées et la sortie (ainsi que les effets secondaires qu'elle pourrait générer). La compréhension des abstractions fonctionnelles via leur domaine, leur gamme et leur intention est essentielle pour les utiliser correctement dans un programme complexe.
Par exemple, toute fonction square que nous utilisons pour implémenter sum_squares devrait avoir ces attributs :
- le domaine est un seul nombre réel quelconque ;
- la gamme est un nombre réel non négatif quelconque ;
- l'intention est que valeur de retour soit le carré de la valeur en entrée.
Ces attributs ne précisent pas comment l'intention est effectuée. Ce détail est abstrait.
III-G. Les Opérateurs▲
Les opérateurs mathématiques ( comme + et - ) ont fourni notre premier exemple d'une méthode de combinaison, mais nous n'avons pas encore défini une procédure d'évaluation pour les expressions qui contiennent ces opérateurs.
Les expressions Python avec les opérateurs infixés ont chacune leurs propres procédures d'évaluation, mais vous pouvez souvent penser qu'elles sont courtes pour les expressions d'appel. Quand vous voyez
2.
>>> 2 + 3
5
considérez simplement qu'il s'agit d'une notation abrégée de :
2.
>>> add(2, 3)
5
La notation infixée peut être imbriquée, tout comme les expressions d'appel. Python applique les règles mathématiques normales de la priorité de l'opérateur, qui dicte comment interpréter une expression composée avec plusieurs opérateurs.
2.
>>> 2 + 3 * 4 + 5
19
fournit le même résultat que
>>> add(add(2, mul(3, 4)), 5)
19La forme imbriquée dans l'expression d'appel est plus explicite que la version de l'opérateur, mais aussi plus difficile à lire. Python permet également de regrouper les sous-expressions avec parenthèses, de remplacer les règles de priorité normales ou de rendre plus explicite la structure imbriquée d'une expression.
2.
>>> (2 + 3) * (4 + 5)
45
fournit le même résultat que
2.
>>> mul(add(2, 3), add(4, 5))
45
En matière de division, Python fournit deux opérateurs infixés : / et //. Le premier est une division normale, de sorte qu'il en résulte un nombre à virgule flottante ou une valeur décimale, même si le diviseur divise le dividende sans reste :
2.
3.
4.
>>> 5 / 4
1.25
>>> 8 / 4
2.0
L'opérateur //, d'autre part, arrondit le résultat à un nombre entier :
2.
3.
4.
>>> 5 // 4
1
>>> -5 // 4
-2
Ces deux opérateurs sont un raccourci pour les fonctions truediv et floordiv.
2.
3.
4.
5.
>>> from operator import truediv, floordiv
>>> truediv(5, 4)
1.25
>>> floordiv(5, 4)
1
N'hésitez pas à utiliser les opérateurs infixés et les parenthèses dans vos programmes. Python préfère les opérateurs aux expressions d'appel pour des opérations mathématiques simples.
IV. Conception de fonctions▲
Les fonctions constituent un élément essentiel de tous les programmes, grands et petits, et constituent notre principal moyen pour exprimer les processus informatiques dans un langage de programmation. Jusqu'à présent, nous avons discuté des propriétés formelles des fonctions et de leur application. Nous allons à présent nous intéresser à ce qui fait une bonne fonction. Fondamentalement, les qualités des bonnes fonctions renforcent l'idée que les fonctions sont des abstractions.
- Chaque fonction doit avoir exactement un travail. Ce travail doit être identifiable avec un nom court et pouvoir être décrit en une seule ligne de texte. Les fonctions qui exécutent plusieurs tâches en séquence doivent être divisées en plusieurs fonctions.
- Ne vous répétez pas, c'est un principe central du génie logiciel. Le principe DRY (don't repeat yourself) dit que plusieurs fragments de code ne doivent pas décrire une logique redondante. Au lieu de cela, cette logique devrait être mise en œuvre une fois, être nommée et appliquée à plusieurs reprises. Si vous copiez/collez un bloc de code, vous avez probablement trouvé une occasion d'abstraction fonctionnelle.
- Les fonctions doivent être définies en général. L'élévation du carré d'un nombre n'est pas dans la bibliothèque Python parce que c'est un cas particulier de la fonction pow, qui élève les nombres à des puissances arbitraires.
Ces lignes directrices améliorent la lisibilité du code, réduisent le nombre d'erreurs et minimisent souvent la quantité totale de code écrit. Décomposer une tâche complexe en fonctions concises est une compétence qui nécessite de l'expérience. Heureusement, Python offre plusieurs fonctionnalités pour soutenir vos efforts.
IV-A. La documentation▲
La définition d'une fonction comprend souvent une documentation décrivant la fonction, appelée docstring, qui doit être indentée avec le corps de fonction. Les docstrings sont traditionnellement triples. La première ligne décrit le travail de la fonction en une seule ligne. Les lignes suivantes peuvent décrire les arguments et clarifier le comportement de la fonction :
2.
3.
4.
5.
6.
7.
8.
9.
10.
>>> def pressure(v, t, n):
"""Compute the pressure in pascals of an ideal gas.
Applies the ideal gas law (see
http://en.wikipedia.org/wiki/Ideal_gas_law
v -- volume of gas, in cubic meters
t -- absolute temperature in degrees kelvin
n -- particles of gas
"""
k = 1.38e-23 # Boltzmann's constant
return n * k * t / v
Lorsque vous appelez la fonction help avec le nom d'une fonction comme argument, vous voyez sa docstring (tapez q pour quitter l'aide Python).
>>> help(pressure)Lors de l'écriture de programmes Python, incluez les docstrings pour toutes les fonctions, sauf les plus simples. Rappelez-vous, le code n'est écrit qu'une fois, mais souvent lu plusieurs fois. Les documents Python incluent des directives docstring qui maintiennent la cohérence sur différents projets Python.
Les commentaires dans Python peuvent être mis à la fin d'une ligne avec le symbole #. Par exemple, le commentaire Boltzmann's constant ci-dessus décrit k. Ces commentaires n'apparaissent jamais dans l'aide de Python, et ils sont ignorés par l'interpréteur. Ils existent seulement pour les humains.
IV-B. Les arguments par défaut▲
Une conséquence de la définition de fonctions générales est l'introduction d'arguments supplémentaires. Les fonctions avec de nombreux arguments peuvent être difficiles à appeler et difficiles à lire.
En Python, nous pouvons fournir des valeurs par défaut pour les arguments d'une fonction. Lorsque vous appelez cette fonction, les arguments avec des valeurs par défaut sont facultatifs. Si elle n'est pas fournie, la valeur par défaut est liée au nom de paramètre formel. Par exemple, si une application calcule généralement la pression pour une mole de particules, cette valeur peut être fournie par défaut :
2.
3.
4.
5.
6.
7.
8.
9.
>>> def pressure(v, t, n=6.022e23):
"""Compute the pressure in pascals of an ideal gas.
v -- volume of gas, in cubic meters
t -- absolute temperature in degrees kelvin
n -- particles of gas (default: one mole)
"""
k = 1.38e-23 # Boltzmann's constant
return n * k * t / v
Le symbole = signifie deux choses différentes dans cet exemple, selon le contexte dans lequel il est utilisé. Dans l'en-tête de la déclaration def, = n'effectue pas d'affectation, mais indique en fait une valeur par défaut à utiliser lorsque la fonction pressure est appelée. En revanche, l'instruction d'affectation à k dans le corps de la fonction lie le nom k à une approximation de la constante de Boltzmann.
2.
3.
4.
>>> pressure(1, 273.15)
2269.974834
>>> pressure(1, 273.15, 3 * 6.022e23)
6809.924502
La fonction pressure est définie pour prendre trois arguments, mais seulement deux sont fournis dans la première expression d'appel ci-dessus. Dans ce cas, la valeur de n est prise à partir de la définition def par défaut. Si un troisième argument est fourni, la valeur par défaut est ignorée.
À titre indicatif, la plupart des valeurs de données utilisées dans le corps d'une fonction doivent être exprimées en valeurs par défaut aux arguments nommés, de sorte qu'elles soient faciles à inspecter et puissent être modifiées par l'appel de la fonction. Certaines valeurs qui ne changent jamais, comme la constante fondamentale k, peuvent être liées dans le corps de la fonction ou dans le cadre global.
V. Contrôler le flux d'exécution▲
Le pouvoir expressif des fonctions que nous pouvons définir à ce stade est très limité, car nous n'avons pas introduit un moyen de faire des comparaisons et d'effectuer différentes opérations en fonction du résultat d'une comparaison. Les instructions de contrôle nous donneront cette capacité. Ce sont des déclarations qui contrôlent le flux de l'exécution d'un programme en fonction des résultats des comparaisons logiques.
Ces instructions diffèrent fondamentalement des expressions que nous avons étudiées jusqu'ici. Elles ne renvoient aucune valeur. Au lieu de calculer quelque chose, l'exécution d'une instruction de contrôle détermine ce que l'interpréteur devra faire ensuite.
V-A. Les instructions▲
Jusqu'à présent, nous avons principalement considéré comment évaluer les expressions. Cependant, nous avons déjà vu trois sortes d'instructions : affectation, def et return. Ces lignes de code Python ne sont pas elles-mêmes des expressions, bien qu'elles contiennent toutes des expressions.
Plutôt que d'être évaluées, les instructions sont exécutées. Chaque instruction décrit un changement dans l'état de l'interpréteur, et l'exécution d'une instruction s'applique à cette modification. Comme nous l'avons vu pour les retours et les instructions d'affectation, les instructions d'exécution peuvent impliquer l'évaluation de sous-expressions qu'elles contiennent.
Les expressions peuvent également être exécutées sous forme d'instructions, auquel cas elles sont évaluées, mais leur valeur est ignorée. L'exécution d'une fonction pure n'a pas d'effet, mais l'exécution d'une fonction non pure peut provoquer des effets en conséquence de l'application de la fonction.
Considérons par exemple,
>>> def square(x):
mul(x, x) # Watch out! This call doesn't return a value.Cet exemple est du code Python valide, mais ne fait probablement pas ce qui était prévu. Le corps de la fonction est constitué d'une expression. Une expression en elle-même est une instruction valide, mais l'effet de cette déclaration est que la fonction mul est appelée et que le résultat est ignoré. Si vous souhaitez faire quelque chose avec le résultat d'une expression, vous devez le dire : vous pouvez l'enregistrer avec une instruction d'affectation ou la renvoyer avec une instruction de retour :
>>> def square(x):
return mul(x, x)Parfois, il est logique d'avoir une fonction dont le corps est une expression, lorsqu'une fonction non pure comme print est appelée.
>>> def print_square(x):
print(square(x))À son plus haut niveau, le travail de l'interpréteur Python consiste à exécuter des programmes, composés d'instructions. Cependant, une grande partie du travail intéressant de calcul provient de l'évaluation des expressions. Les instructions régissent la relation entre différentes expressions dans un programme et ce qui arrive à leurs résultats.
V-B. Les instructions composées▲
En général, un programme Python est une séquence d'instructions. Une simple instruction est une seule ligne qui ne se termine pas par le caractère deux points. Une instruction composée est ainsi appelée parce qu'elle est composée d'autres instructions (simples et composées). Les instructions composées couvrent généralement plusieurs lignes et commencent par un en-tête d'une ligne se terminant par deux points, qui identifie le type d'instruction. Ensemble, un en-tête et une suite d'instructions sont appelés une clause. Une instruction composée comprend une ou plusieurs clauses :
2.
3.
4.
5.
6.
7.
8.
9.
<header>:
<statement>
<statement>
...
<separating header>:
<statement>
<statement>
...
...
Nous pouvons comprendre les instructions que nous avons déjà introduites dans ces termes.
- Les expressions, les instructions de retour et les instructions d'affectation sont des instructions simples.
- Une instruction def est une instruction composée. La suite qui suit l'en-tête def définit le corps de la fonction.
Les règles d'évaluation spécialisées pour chaque type d'en-tête dictent quand et si les instructions dans leur suite sont exécutées. Nous disons que l'en-tête contrôle sa suite. Par exemple, dans le cas des instructions def, nous avons vu que l'expression de retour n'est pas évaluée immédiatement, mais est plutôt stockée pour une utilisation ultérieure lorsque la fonction définie est finalement appelée.
Nous pouvons également comprendre les programmes multilignes maintenant.
Pour exécuter une séquence d'instructions, exécutez la première instruction. Si celle-ci ne redirige pas le contrôle, procédez à l'exécution du reste de la séquence d'instructions, le cas échéant.
Cette définition expose la structure essentielle d'une séquence récursivement définie : une séquence peut être décomposée entre son premier élément et le reste de ses éléments. Le « reste » d'une séquence d'instructions est lui-même une séquence d'instructions ! Ainsi, nous pouvons appliquer récursivement cette règle d'exécution. Cette perception des séquences comme structures de données récursives apparaîtra à nouveau dans les chapitres ultérieurs.
La conséquence importante de cette règle est que les instructions sont exécutées dans l'ordre, mais les déclarations ultérieures peuvent ne jamais être atteintes, en raison du contrôle redirigé.
Guide pratique. Lors de l'indentation d'une suite d'instructions, toutes les lignes doivent être indentées de la même manière (utilisez des espaces, pas des tabulations). Toute variation de l'indentation entraînera une erreur.
V-C. Définitions des fonctions II : affectation locale▲
Nous avons expliqué au début que le corps d'une fonction définie par l'utilisateur ne comportait qu'une déclaration de retour avec une seule expression de retour. En fait, les fonctions peuvent définir une séquence d'opérations qui s'étend au-delà d'une seule expression.
Chaque fois qu'une fonction définie par l'utilisateur est appelée, la séquence de clauses dans la suite de sa définition est exécutée dans un environnement local - un environnement commençant par un cadre local créé en appelant cette fonction. Une instruction de retour redirige le contrôle : la procédure de l'application de fonction se termine quand la première instruction de retour est exécutée et que la valeur de l'expression de retour est la valeur renvoyée de la fonction appliquée.
Des instructions d'affectation peuvent apparaître dans le corps d'une fonction. Par exemple, la fonction suivante renvoie la différence absolue entre deux quantités en pourcentage de la première, en utilisant un calcul en deux étapes :
|
Sélectionnez 1. 2. 3. 4. 5. |
 |
L'effet d'une instruction d'affectation est de lier un nom à une valeur dans le premier cadre de l'environnement actuel. En conséquence, les instructions d'affectation dans un corps de fonction ne peuvent pas affecter le cadre global. Le fait que les fonctions ne peuvent que manipuler leur environnement local est essentiel pour créer des programmes modulaires, dans lesquels les fonctions pures n'interagissent que par les valeurs qu'ils prennent et retournent.
Bien sûr, la fonction percent_difference pourrait être écrite comme une seule expression, comme indiqué ci-dessous, mais l'expression de retour est plus complexe.
2.
3.
4.
>>> def percent_difference(x, y):
return 100 * abs(x-y) / x
>>> percent_difference(40, 50)
25.0
Pour l'instant, l'affectation locale n'a pas élargi la puissance expressive de nos définitions de fonctions. Ce sera le cas lorsqu'elles seront combinées à d'autres instructions de contrôle. En outre, une affectation locale présente l'avantage critique de clarifier la signification d'expressions complexes en donnant un nom aux quantités intermédiaires.
V-D. Les déclarations conditionnelles▲
Python a une fonction intégrée pour calculer des valeurs absolues.
2.
>>> abs(-2)
2
Nous aimerions être en mesure d'écrire une telle fonction nous-mêmes, mais nous n'avons aucun moyen évident de définir une fonction qui a une comparaison et un choix. Nous aimerions exprimer que si x est positif, abs (x) renvoie x. En outre, si x est 0, abs (x) renvoie 0. Sinon, abs (x) renvoie -x. En Python, nous pouvons exprimer ce choix avec une déclaration conditionnelle.
|
Sélectionnez 1. 2. 3. 4. 5. 6. 7. 8. 9. |
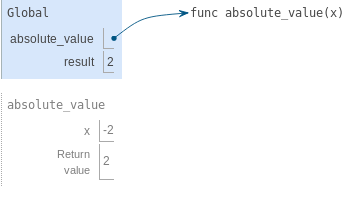 |
Cette implémentation de absolute_value aborde plusieurs questions importantes.
Instructions conditionnelles. Une instruction conditionnelle dans Python se compose d'une série d'en-têtes et de suites : une clause if requise, une séquence facultative de clauses elif et une clause optionnelle else supplémentaire :
2.
3.
4.
5.
6.
if <expression>:
<suite>
elif <expression>:
<suite>
else:
<suite>
Lors de l'exécution d'une instruction conditionnelle, chaque clause est considérée dans l'ordre. Le processus de calcul de l'exécution d'une clause conditionnelle suit.
- Évaluer l'expression de l'en-tête.
- Si c'est une valeur vraie, exécutez la suite. Ensuite, ignorez toutes les clauses ultérieures de l'instruction conditionnelle
Si la clause else est atteinte (ce qui ne se produit que si toutes les expressions if et elif évaluent les fausses valeurs), sa suite est exécutée.
Contexte booléen. Les procédures d'exécution mentionnent "une valeur fausse" et "une valeur vraie". On dit que les expressions dans les instructions d'en-tête des blocs conditionnels sont dans des contextes booléens : leurs valeurs (vraies ou fausses) sont importantes pour contrôler le flux, mais elles ne sont pas affectées ni renvoyées. Python intègre plusieurs valeurs fausses comme 0, None et la valeur booléenne False. Tous les autres nombres sont des valeurs vraies. Dans un chapitre ultérieur, nous verrons que toutes les données intégrées dans Python ont des valeurs vraies ou fausses.
Les valeurs booléennes. Python a deux valeurs booléennes, appelées True and False. Les valeurs booléennes représentent des valeurs de vérité (c'est-à-dire vraies ou fausses) dans des expressions logiques. Les opérations de comparaison intégrées,>, <,> =, <=, ==,! =, renvoient ces valeurs.
>>> 4 < 2
False
>>> 5 >= 5
TrueCe deuxième exemple indique "5 est supérieur ou égal à 5", et correspond à la fonction ge dans le module operator.
>>> 0 == -0
TrueCet exemple final indique "0 égal à -0" et correspond à eq dans le module operator. Notez que Python distingue l'affectation (=) de la comparaison d'égalité (==), une convention partagée dans de nombreux langages de programmation.
Opérateurs booléens. Trois opérateurs logiques de base sont également intégrés dans Python :
2.
3.
4.
5.
6.
>>> True and False
False
>>> True or False
True
>>> not False
True
Les expressions logiques ont des procédures d'évaluation correspondantes. Ces procédures exploitent le fait que la valeur vraie d'une expression logique peut parfois être déterminée sans évaluer toutes ses sous-expressions, une caractéristique appelée court-circuit.
Pour évaluer l'expression <gauche> and <droite> :
- Évaluer la sous-expression <gauche> ;
- Si le résultat est une valeur fausse v, l'expression s'évalue à v ;
- Sinon, l'expression évalue la valeur de la sous-expression <droite>.
Pour évaluer l'expression <gauche> or <droite> :
- Évaluer la sous-expression <gauche> ;
- Si l'expression est une valeur vraie v, l'expression s'évalue à v ;
- Sinon, l'expression s'évalue à la valeur de la sous-expression <droite>.
Pour évaluer l'expression not <exp> :
- Évaluer <exp> ; la valeur est True si le résultat est une valeur fausse et False sinon.
Ces valeurs, règles et opérateurs nous permettent de combiner les résultats des comparaisons. Les fonctions qui effectuent des comparaisons et renvoient des valeurs booléennes commencent généralement par is, ne sont pas suivies par un trait de soulignement (par exemple, isfinite, isdigit, isinstance, etc.).
V-E. Les itérations▲
En plus de sélectionner les instructions à exécuter, les instructions de contrôle sont utilisées pour exprimer la répétition. Si chaque ligne de code que nous avons écrit n'était exécutée qu'une seule fois, la programmation serait un exercice très improductif. Ce n'est que par l'exécution répétée d'instructions que nous débloquons tout le potentiel des ordinateurs. Nous avons déjà vu une forme de répétition : une fonction peut être appliquée plusieurs fois, bien qu'elle ne soit définie qu'une seule fois. Les structures de contrôle itératives sont un autre mécanisme pour exécuter les mêmes instructions à plusieurs reprises.
Considérons la suite des nombres de Fibonacci, dans laquelle chaque nombre est la somme des deux précédents :
0, 1, 1, 2, 3, 5, 8, 13, 21…
Chaque valeur est construite en appliquant à plusieurs reprises la règle de la somme précédente. Les premier et deuxième sont fixés à 0 et 1. Par exemple, le huitième nombre de Fibonacci est 13.
Nous pouvons utiliser une instruction while pour énumérer n nombres de Fibonacci. Nous devons nous souvenir du nombre de valeurs que nous avons créées (k), ainsi que la kème valeur (curr) et son prédécesseur (pred). À travers cette fonction, observez comment les nombres de Fibonacci évoluent un par un, liés à curr.
2.
3.
4.
5.
6.
7.
8.
9.
def fib(n):
"""Compute the nth Fibonacci number, for n >= 2."""
pred, curr = 0, 1 # Fibonacci numbers 1 and 2
k = 2 # Which Fib number is curr?
while k < n:
pred, curr = curr, pred + curr
k = k + 1
return curr
result = fib(8)
N'oubliez pas que les virgules séparent plusieurs noms et valeurs dans une instruction d'affectation. La ligne :
Pred, curr = curr, pred + curr
a pour effet de lier le nom pred à la valeur de curr, et de lier simultanément curr à la valeur de pred + curr. Toutes les expressions à droite du signe = sont évaluées avant d'effectuer les nouvelles liaisons résultant des affectations.
Cet ordre des événements - évaluer tout à droite du signe = avant de mettre à jour les liaisons à gauche - est essentiel pour l'exactitude de cette fonction.
Une clause while contient une expression d'en-tête suivie d'une suite :
while <expression>:
<suite>Pour exécuter la clause while :
- Évaluer l'expression de l'en-tête ;
- Si c'est une valeur vraie, exécutez la suite, puis revenez à l'étape 1.
À l'étape 2, la suite complète de la clause while est exécutée avant que l'expression d'en-tête ne soit évaluée à nouveau.
Afin d'éviter que la suite d'une clause while ne soit exécutée indéfiniment, la suite doit toujours changer au moins une liaison à chaque fois que la boucle est parcourue.
Une instruction while qui ne se termine pas s'appelle une boucle infinie. Appuyez sur <Contrôle> -C pour forcer Python à arrêter la boucle.
V-F. Les tests▲
Le test d'une fonction est l'acte de vérifier que le comportement de la fonction correspond aux attentes. Notre langage de fonctions est maintenant suffisamment complexe pour qu'il soit nécessaire de commencer à tester les fonctions que nous écrivons.
Un test est un mécanisme permettant d'effectuer systématiquement cette vérification. Les tests prennent généralement la forme d'une autre fonction qui contient un ou plusieurs appels à la fonction testée. La valeur retournée est ensuite vérifiée par rapport à un résultat attendu. Contrairement à la plupart des fonctions, qui doivent être générales, les tests impliquent la sélection et la validation d'appels avec des valeurs d'argument spécifiques. Les tests servent également de documentation : ils démontrent comment appeler une fonction et les valeurs d'arguments appropriées.
Assertions. Les programmeurs utilisent des instructions assert pour vérifier les attentes, telles que la valeur de retour d'une fonction testée. Une instruction assert se compose d'une expression dans un contexte booléen, suivie d'une ligne de texte citée (les guillemets simples (ou apostrophes) ou doubles sont tous les deux bien, mais soyez cohérent) qui seront affichées si l'expression est évaluée à une valeur fausse.
>>> assert fib(8) == 13, 'The 8th Fibonacci number should be 13'
Lorsque l'expression testée s'évalue à une valeur vraie, l'exécution d'une instruction assert n'a aucun effet. Quand il s'agit d'une valeur fausse, assert provoque une erreur qui arrête l'exécution.
Une fonction de test pour fib doit tester plusieurs arguments, y compris des valeurs extrêmes de n.
2.
3.
4.
>>> def fib_test():
assert fib(2) == 1, 'The 2nd Fibonacci number should be 1'
assert fib(3) == 1, 'The 3rd Fibonacci number should be 1'
assert fib(50) == 7778742049, 'Error at the 50th Fibonacci number'
Lors de l'écriture de programmes Python dans les fichiers, plutôt que directement dans l'interpréteur, les tests sont généralement écrits dans le même fichier ou dans un fichier voisin avec le suffixe _test.py. Python fournit une méthode pratique pour placer des tests simples directement dans le docstring d'une fonction. La première ligne d'un docstring doit contenir une description en une ligne de la fonction, suivie d'une ligne vierge. Une description détaillée des arguments et du comportement peut suivre. En outre, le docstring peut inclure un exemple de session interactive qui appelle la fonction :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
>>> def sum_naturals(n):
"""Return the sum of the first n natural numbers.
>>> sum_naturals(10)
55
>>> sum_naturals(100)
5050
"""
total, k = 0, 1
while k <= n:
total, k = total + k, k + 1
return total
Ensuite, l'interaction peut être vérifiée via le module doctest. Ci-dessous, la fonction globals renvoie une représentation de l'environnement global, dont l'interpréteur a besoin pour évaluer les expressions.
2.
3.
>>> from doctest import testmod
>>> testmod()
TestResults(failed=0, attempted=2)
Pour vérifier les interactions de doctest pour une seule fonction, nous utilisons une fonction doctest appelée run_docstring_examples. Cette fonction est (malheureusement) un peu compliquée à appeler. Son premier argument est la fonction à tester. Le deuxième doit toujours être le résultat de l'expression globals (), une fonction intégrée qui renvoie l'environnement global. Le troisième argument est True pour indiquer que nous souhaiterions une sortie « détaillée » : un catalogue de tous les tests exécutés.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
>>> from doctest import run_docstring_examples
>>> run_docstring_examples(sum_naturals, globals(), True)
Finding tests in NoName
Trying:
sum_naturals(10)
Expecting:
55
ok
Trying:
sum_naturals(100)
Expecting:
5050
ok
Lorsque la valeur de retour d'une fonction ne correspond pas au résultat attendu, la fonction run_docstring_examples signalera ce problème comme une erreur de test.
Quand on écrit un programme Python dans un fichier, tous les doctests dans un fichier peuvent être exécutés en démarrant Python avec l'option de ligne de commande doctest :
python3 -m doctest <python_source_file>
La clé pour un test efficace consiste à émettre des tests (et les exécuter) immédiatement après la mise en œuvre de nouvelles fonctions. Il est même souvent souhaitable d'écrire des tests avant d'écrire la fonction à tester, afin d'avoir des exemples d'entrées et de sorties dans votre esprit. Un test qui s'applique à une fonction unique est appelé test unitaire. Les tests unitaires exhaustifs sont une caractéristique de la conception d'un bon programme.
VI. Les fonctions d'ordre supérieur▲
Nous avons vu que les fonctions sont une méthode d'abstraction qui décrivent les opérations composées indépendamment des valeurs particulières de leurs arguments. Ceci veut dire que, dans la fonction square,
2.
>>> def square(x):
return x * x
nous ne parlons pas du carré d'un nombre particulier, mais plutôt d'une méthode pour obtenir le carré d'un nombre quelconque. Bien sûr, nous pourrions nous débrouiller sans jamais définir cette fonction, en écrivant toujours des expressions telles que
2.
3.
4.
>>> 3 * 3
9
>>> 5 * 5
25
et ne jamais mentionner square explicitement. Cette pratique suffirait à des calculs simples tels que square, mais deviendrait difficile pour des exemples plus complexes tels que abs ou fib. En général, ne pas définir une fonction présente l'inconvénient de nous forcer à travailler toujours au niveau des opérations primitives du langage (multiplication, dans ce cas) plutôt que par des opérations de niveau supérieur. Nos programmes seraient en mesure de calculer les carrés, mais notre langage ne serait pas capable d'exprimer le concept du calcul du carré.
L'une des choses que nous devons exiger d'un langage de programmation puissant est la capacité à construire des abstractions en attribuant des noms à des modèles communs, puis à travailler avec ces noms directement. Les fonctions fournissent cette capacité. Comme on le verra dans les exemples suivants, il existe des modèles de programmation communs qui reviennent dans le code, mais qui sont utilisés avec un certain nombre de fonctions différentes. Ces modèles peuvent également être rendus abstraits, en leur donnant des noms.
Pour exprimer certains modèles généraux en tant que concepts nommés, nous devrons construire des fonctions pouvant accepter d'autres fonctions comme arguments ou renvoyant des fonctions comme valeurs de retour. Les fonctions qui manipulent les fonctions sont appelées fonctions d'ordre supérieur. Cette section montre comment les fonctions d'ordre supérieur peuvent servir de puissants mécanismes d'abstraction, augmentant considérablement le pouvoir expressif de notre langage.
VI-A. Les fonctions comme arguments▲
Considérons les trois fonctions suivantes, qui effectuent toutes des sommes. La première, sum_naturals, calcule la somme des entiers naturels jusqu'à n :
2.
3.
4.
5.
6.
7.
>>> def sum_naturals(n):
total, k = 0, 1
while k <= n:
total, k = total + k, k + 1
return total
>>> sum_naturals(100)
5050
La deuxième, sum_cubes calcule la somme des cubes des entiers naturels jusqu'à n :
2.
3.
4.
5.
6.
7.
>>> def sum_cubes(n):
total, k = 0, 1
while k <= n:
total, k = total + k*k*k, k + 1
return total
>>> sum_cubes(100)
25502500
La troisième, pi_sum, calcule la somme des termes de la série :
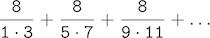
Qui converge vers pi très lentement.
2.
3.
4.
5.
6.
7.
>>> def pi_sum(n):
total, k = 0, 1
while k <= n:
total, k = total + 8 / ((4*k-3) * (4*k-1)), k + 1
return total
>>> pi_sum(100)
3.1365926848388144
Ces trois fonctions partagent clairement un motif sous-jacent commun. Elles sont en grosse partie identiques, différant uniquement du nom et de la fonction k utilisée pour calculer le terme à ajouter. Nous pourrions générer chacune des fonctions en remplissant des mots placés entre des chevrons dans le même modèle :
2.
3.
4.
5.
def <name>(n):
total, k = 0, 1
while k <= n:
total, k = total + <term>(k), k + 1
return total
La présence d'un tel schéma commun est une pièce à conviction forte de l'existence d'une abstraction utile en attente d'être amenée à la surface. Chacune de ces fonctions est une sommation de termes. En tant que concepteurs de programme, nous aimerions que notre langage soit suffisamment puissant pour que nous puissions écrire une fonction qui exprime la notion de sommation elle-même, plutôt que des fonctions qui calculent des sommes particulières. Nous pouvons le faire facilement en Python en prenant le modèle commun montré ci-dessus et en transformant les mots entre chevrons en paramètres formels.
Dans l'exemple ci-dessous, summation prend deux arguments notamment la limite supérieure n et la fonction term qui calcule le kème terme. Nous pouvons utiliser summation comme n'importe quelle fonction, et elle exprime explicitement une sommation. Prenez le temps de parcourir cet exemple et notez comment la liaison entre la fonction cube et le nom local term garantit que le résultat 1 * 1 * 1 + 2 * 2 * 2 + 3 * 3 * 3 = 36 soit calculé correctement. Dans cet exemple, les cadres qui ne sont plus nécessaires sont supprimés pour économiser de l'espace.
|
Sélectionnez 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. |
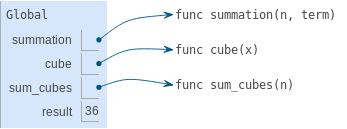 |
En utilisant une fonction identity qui renvoie son argument, nous pouvons également sommer des nombres naturels en utilisant exactement la même fonction summation.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
>>> def summation(n, term):
total, k = 0, 1
while k <= n:
total, k = total + term(k), k + 1
return total
>>> def identity(x):
return x
>>> def sum_naturals(n):
return summation(n, identity)
>>> sum_naturals(10)
55
La fonction summation peut également être appelée directement, sans définir une autre fonction pour une séquence spécifique.
2.
>>> summation(10, square)
385
Nous pouvons définir pi_sum en utilisant notre fonction abstraite summation en définissant une fonction pi_term pour calculer chaque terme. Nous passons l'argument 1e6, un raccourci pour 1 * 10 ^ 6 = 1 000 000, pour générer une approximation proche de pi.
2.
3.
4.
5.
6.
7.
8.
>>> def pi_term(x):
return 8 / ((4*x-3) * (4*x-1))
>>> def pi_sum(n):
return summation(n, pi_term)
>>> pi_sum(1e6)
3.141592153589902
VI-B. Les fonctions comme méthodes générales▲
Nous avons introduit des fonctions définies par l'utilisateur comme un mécanisme pour abstraire les modèles d'opérations numériques, afin de les rendre indépendants des nombres particuliers impliqués. Avec les fonctions d'ordre supérieur, nous commençons à voir une sorte d'abstraction plus puissante : certaines fonctions expriment des méthodes générales de calcul indépendantes des fonctions particulières qu'elles appellent.
Malgré cette extension conceptuelle de ce que signifie une fonction, notre modèle d'environnement à propos de la façon d'évaluer une expression d'appel s'étend naturellement au cas des fonctions d'ordre supérieur, sans changement. Lorsqu'une fonction définie par l'utilisateur est appliquée à certains arguments, les paramètres formels sont liés aux valeurs de ces arguments (qui peuvent être des fonctions) dans un nouvel environnement local.
Considérons l'exemple suivant, qui implémente une méthode générale d'amélioration itérative et l'utilise pour calculer le nombre d'or. Le nombre d'or, souvent dénoté "phi", est un nombre proche de 1.6 qui apparaît fréquemment dans la nature, l'art et l'architecture.
Un algorithme d'amélioration itératif commence par une estimation guess d'une solution à une équation. Il applique à plusieurs reprises une fonction update pour améliorer cette estimation et applique à close une comparaison étroite pour vérifier si l'estimation actuelle est "assez proche" pour être considérée comme correcte.
2.
3.
4.
>>> def improve(update, close, guess=1):
while not close(guess):
guess = update(guess)
return guess
Cette fonction improve est une expression générale du raffinement répétitif. Il ne précise pas quel problème est résolu : ces détails sont laissés aux fonctions update et close passées comme arguments.
Parmi les propriétés bien connues du nombre d'or, on peut le calculer en additionnant à plusieurs reprises l'inverse de n'importe quel nombre positif avec 1, et qu'il est égal à son propre carré moins 1. Nous pouvons exprimer ces propriétés sous le forme de fonctions à utiliser avec improve.
2.
3.
4.
5.
>>> def golden_update(guess):
return 1/guess + 1
>>> def square_close_to_successor(guess):
return approx_eq(guess * guess, guess + 1)
Ci-dessus, nous introduisons un appel à approx_eq qui est destiné à renvoyer True si ses arguments sont approximativement égaux les uns aux autres. Pour implémenter, approx_eq, on peut comparer la valeur absolue de la différence entre deux nombres à une petite valeur de tolérance.
2.
>>> def approx_eq(x, y, tolerance=1e-15):
return abs(x - y) < tolerance
L'appel de la fonction improve avec les arguments golden_update et square_close_to_successor calculera une approximation du nombre d'or.
2.
>>> improve(golden_update, square_close_to_successor)
1.6180339887498951
En parcourant les étapes de l'évaluation, nous pouvons voir comment ce résultat est calculé. Tout d'abord, un cadre local pour improve est construit avec des liaisons pour update, close et guess. Dans le corps de la fonction improve, le nom close est lié à square_close_to_successor, qui est appelé sur la valeur initiale de guess. Tracez le reste des étapes pour voir le processus de calcul qui évolue pour calculer le nombre d'or.
|
Sélectionnez 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. |
 |
Cet exemple illustre deux grandes idées connexes en informatique. Tout d'abord, les noms et les fonctions nous permettent d'abstraire une grande complexité. Bien que chaque définition de fonction ait été banale, le processus de calcul mis en mouvement par notre procédure d'évaluation est assez complexe. Deuxièmement, c'est seulement en vertu du fait que nous avons une procédure d'évaluation extrêmement générale pour le langage Python que les petits composants peuvent être regroupés en processus complexes. La compréhension de la procédure d'interprétation des programmes nous permet de valider et d'inspecter le processus que nous avons créé.
Comme toujours, notre nouvelle méthode générale improve nécessite un test pour vérifier son exactitude. Le nombre d'or peut fournir un tel test, car il a également une solution exacte de forme fermée, que nous pouvons comparer à ce résultat itératif.
2.
3.
4.
5.
6.
>>> from math import sqrt
>>> phi = 1/2 + sqrt(5)/2
>>> def improve_test():
approx_phi = improve(golden_update, square_close_to_successor)
assert approx_eq(phi, approx_phi), 'phi differs from its approximation'
>>> improve_test()
Pour ce test, pas de nouvelle est une bonne nouvelle : Impro_test renvoie None après que son instruction assert a été exécutée avec succès.
VI-C. Définition des fonctions - définitions imbriquées▲
Les exemples ci-dessus démontrent comment la capacité de passer des fonction en arguments améliore considérablement la puissance expressive de notre langage de programmation. Chaque concept ou équation générale se caractérise par sa propre fonction. Une conséquence négative de cette approche est que le cadre global est encombré de noms de petites fonctions, qui doivent tous être uniques. Un autre problème est que nous sommes contraints par des signatures de fonctions particulières : l'argument update de improve doit prendre exactement un argument. Les définitions de fonctions imbriquées répondent à ces deux problèmes, mais nous obligent à enrichir notre modèle d'environnement.
Considérons un nouveau problème : calculer la racine carrée d'un nombre. Dans les langages de programmation, la "racine carrée" est souvent abrégée en sqrt. L'application répétée de la mise à jour suivante converge vers la racine carrée de a :
2.
3.
4.
>>> def average(x, y):
return (x + y)/2
>>> def sqrt_update(x, a):
return average(x, a/x)
Cette fonction de mise à jour à deux arguments est incompatible avec improve (il faut deux arguments, pas un), et elle fournit une seule mise à jour, alors que nous nous voudrions vraiment obtenir la racine carrée par des mises à jour répétées. La solution à ces deux problèmes consiste à placer des définitions de fonctions dans le corps d'autres définitions.
2.
3.
4.
5.
6.
>>> def sqrt(a):
def sqrt_update(x):
return average(x, a/x)
def sqrt_close(x):
return approx_eq(x * x, a)
return improve(sqrt_update, sqrt_close)
Comme des instructions locales, les instructions locales def ne concernent que le cadre local actuel. Ces fonctions ne sont valables que lorsque sqrt est en cours d'évaluation. Conformément à notre procédure d'évaluation, ces déclarations def locales ne sont même pas évaluées jusqu'à ce que la fonction sqrt soit appelée.
Portée Lexicale. Les fonctions définies localement ont également accès aux liaisons de noms dans la portée dans laquelle elles sont définies. Dans cet exemple, sqrt_update se réfère au nom a, qui est un paramètre formel de sa fonction d'inclusion sqrt. Cette discipline de partage des noms entre les définitions imbriquées s'appelle la portée lexicale. De manière critique, les fonctions internes ont accès aux noms dans l'environnement où elles sont définies (pas où elles sont appelées).
Nous avons besoin de deux extensions dans notre modèle d'environnement pour permettre la portée lexicale.
- Chaque fonction définie par l'utilisateur possède un environnement parent, celui dans lequel elle a été définie.
- Lorsqu'une fonction définie par l'utilisateur est appelée, son cadre local étend son environnement parent.
Avant la définition de sqrt ci-dessus, toutes les fonctions étaient définies dans l'environnement global et donc elles avaient toutes le même parent : l'environnement global. En revanche, lorsque Python évalue les deux premières clauses de sqrt, elle crée des fonctions associées à un environnement local. Dans l'appel
>>> sqrt(256)
16.0l'environnement ajoute d'abord un cadre local pour sqrt et évalue les instructions def pour sqrt_update et sqrt_close.
|
Sélectionnez 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. |
 |
Les valeurs de fonction ont chacune une nouvelle annotation que nous allons inclure dans les diagrammes d'environnement à présent, un parent. Le parent d'une valeur de fonction est le premier cadre de l'environnement dans lequel cette fonction a été définie. Les fonctions sans annotations parentales ont été définies dans l'environnement global. Lorsqu'une fonction définie par l'utilisateur est appelée, le cadre créé a le même parent que cette fonction.
Ensuite, le nom sqrt_update renvoie à cette fonction nouvellement définie, qui est transmise comme un argument à improve. Dans le corps de la fonction improve , nous devons appliquer notre fonction update (liée à sqrt_update) à l'estimation initiale x à 1. Cette dernière application crée un environnement pour sqrt_update qui commence par une trame locale contenant uniquement x, mais avec la structure parentale sqrt ayant encore une liaison pour a.
|
Sélectionnez 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. |
 |
La partie la plus critique de cette procédure d'évaluation est le transfert du parent pour sqrt_update vers le cadre créé en appelant sqrt_update. Ce cadre est également annoté avec [parent = f1].
Environnements étendus. Un environnement peut être constitué d'une chaîne arbitrairement longue de trames, qui se termine toujours avec le cadre global. Avant cet exemple de sqrt, les environnements comportaient au plus deux cadres : un cadre local et le cadre global. En appelant des fonctions qui ont été définies dans d'autres fonctions, par le biais de déclarations imbriquées de def, nous pouvons créer des chaînes plus longues. L'environnement pour cet appel à sqrt_update se compose de trois cadres : le cadre local sqrt_update, le cadre sqrt dans lequel sqrt_update a été défini (étiqueté f1) et le cadre global.
L'expression de retour dans le corps de sqrt_update peut trouver une valeur pour a en suivant cette chaîne de cadres. En regardant vers le haut, un nom trouve la première valeur liée à ce nom dans l'environnement actuel. Python vérifie d'abord le cadre sqrt_update : a n'existe pas. Python vérifie ensuite dans le cadre parental, f1, et trouve une liaison pour a à 256.
Par conséquent, nous réalisons deux avantages clés de la portée lexicale dans Python.
- Les noms d'une fonction locale n'interfèrent pas avec les noms externes à la fonction dans laquelle il est défini, car le nom de la fonction locale sera lié dans l'environnement local actuel dans lequel il a été défini, plutôt que dans l'environnement global.
- Une fonction locale peut accéder à l'environnement de la fonction englobante, car le corps de la fonction locale est évalué dans un environnement qui étend l'environnement d'évaluation dans lequel il a été défini.
La fonction sqrt_update contient des données : la valeur pour a référée dans l'environnement dans lequel elle a été définie. Les fonctions localement définies sont souvent appelées fermetures.
VI-D. Fonctions comme valeurs renvoyées▲
Nous pouvons obtenir un pouvoir encore plus expressif dans nos programmes en créant des fonctions dont les valeurs renvoyées sont elles-mêmes des fonctions. Une caractéristique importante des langages de programmation à portée lexicale est que les fonctions localement définies maintiennent leur environnement parent lorsqu'elles sont renvoyées. L'exemple suivant illustre l'utilité de cette fonctionnalité.
Une fois que de nombreuses fonctions simples sont définies, la composition de la fonction est une méthode naturelle de combinaison à inclure dans notre langage de programmation. C'est-à-dire, compte tenu de deux fonctions f (x) et g (x), on peut vouloir définir h (x) = f (g (x)). Nous pouvons définir la composition de la fonction en utilisant nos outils existants :
2.
3.
4.
>>> def compose1(f, g):
def h(x):
return f(g(x))
return h
Le diagramme d'environnement pour cet exemple montre comment les noms f et g sont résolus correctement, même en présence de noms conflictuels.
|
Sélectionnez 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. |
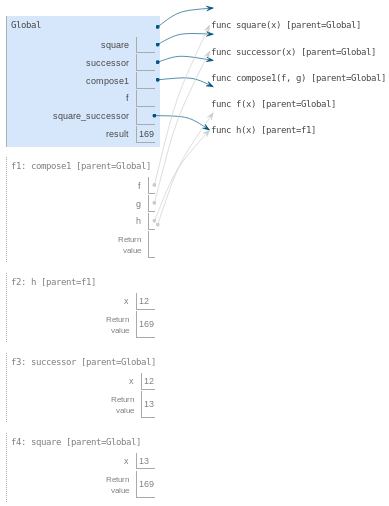 |
Le 1 dans le nom compose1 signifie que les fonctions composées prennent toutes un seul argument. Cette convention de nommage n'est pas appliquée par l'interpréteur. Le 1 est juste une partie du nom de la fonction.
À ce stade, nous commençons à observer les avantages de notre effort pour définir précisément le modèle environnemental de calcul. Aucune modification de notre modèle environnemental n'est nécessaire pour expliquer notre capacité à renvoyer les fonctions de cette façon.
VI-E. La méthode Newton▲
Cet exemple étendu montre comment les valeurs de retour de fonctions et les définitions locales peuvent fonctionner ensemble pour exprimer des idées générales de manière concise. Nous mettrons en œuvre un algorithme qui est largement utilisé dans l'apprentissage des machines, le calcul scientifique, la conception de matériel et l'optimisation.
La méthode de Newton est une approche itérative classique pour trouver les arguments d'une fonction mathématique qui donne comme valeur de retour 0. Ces valeurs sont appelées les zéros de la fonction. Trouver un zéro d'une fonction est souvent équivalent à résoudre un autre problème d'intérêt, tel que le calcul d'une racine carrée.
Un commentaire motivant avant de procéder : il est facile de prendre pour acquis le fait que nous savons comment calculer les racines carrées. Non seulement Python, mais votre téléphone, votre navigateur ou votre calculateur de poche peut le faire pour vous. Cependant, une partie de l'apprentissage de l'informatique permet de comprendre comment des quantités comme celles-ci peuvent être calculées, et l'approche générale présentée ici est applicable à la résolution d'une grande classe d'équations au-delà de celles intégrées à Python.
La méthode de Newton est un algorithme d'amélioration itératif : il améliore une estimation du zéro pour toute fonction différentiable, ce qui signifie qu'elle peut être approchée par une ligne droite en tout point. La méthode de Newton suit ces approximations linéaires pour trouver des zéros fonctionnels.
Imaginez une droite passant par le point (x, f (x)) et ayant la même pente que la courbe de la fonction f (x) à ce point. Une telle droite s'appelle la tangente, et sa pente est appelée dérivée de f en x.
La pente de cette droite est le rapport de la variation de la valeur de la fonction à la modification de l'argument de la fonction. Par conséquent, la traduction de x en f (x) divisé par la pente donnera la valeur d'argument à laquelle cette ligne tangente touche 0.
La fonction newton_update exprime le processus de calcul consistant à trouver la valeur pour laquelle cette tangente vaut 0, pour une fonction f et sa dérivée df.
2.
3.
4.
>>> def newton_update(f, df):
def update(x):
return x - f(x) / df(x)
return update
Enfin, nous pouvons définir la fonction find_root en termes de newton_update, notre algorithme improve et une comparaison pour voir si f (x) est proche de 0.
2.
3.
4.
>>> def find_zero(f, df):
def near_zero(x):
return approx_eq(f(x), 0)
return improve(newton_update(f, df), near_zero)
Calculs de racines. En utilisant la méthode de Newton, on peut calculer les racines de degré n arbitraire. La racine de degré n de a est x tel que x*x*x ... x = a avec x n fois répété. Par exemple :
- la racine carrée (seconde) de 64 est 8, car 8⋅8 = 64 ;
- la racine cubique (troisième) de 64 est 4, car 4⋅4⋅4 = 64 ;
- la racine sixième de 64 est 2, car 2⋅2⋅2⋅2⋅2⋅2 = 64.
Nous pouvons calculer les racines en utilisant la méthode de Newton avec les observations suivantes :
la racine carrée de 64 (écrit kitxmlcodeinlinelatexdvp\sqrt{64}finkitxmlcodeinlinelatexdvp) est la valeur x telle que kitxmlcodeinlinelatexdvpx^2 - 64 = 0finkitxmlcodeinlinelatexdvp
Plus généralement, la racine nème de a (écrit kitxmlcodeinlinelatexdvp\sqrt[n]{a}finkitxmlcodeinlinelatexdvp ) est la valeur x telle que kitxmlcodeinlinelatexdvpx^n - a = 0finkitxmlcodeinlinelatexdvp
Si nous pouvons trouver un zéro de cette dernière équation, on peut calculer la racine de degré n. En traçant les courbes pour n égal à 2, 3 et 6 et a égal à 64, on peut visualiser cette relation.
Nous implémentons d'abord la racine carrée en définissant f et sa dérivée df. Nous utilisons du calcul le fait que la dérivée de kitxmlcodeinlinelatexdvpf(x) = x^2 - afinkitxmlcodeinlinelatexdvpest la fonction linéaire df (x) = 2x.
2.
3.
4.
5.
6.
7.
8.
>>> def square_root_newton(a):
def f(x):
return x * x - a
def df(x):
return 2 * x
return find_zero(f, df)
>>> square_root_newton(64)
8.0
En généralisant à des racines de degré arbitraire n, on calcule kitxmlcodeinlinelatexdvpf(x) = x^n - afinkitxmlcodeinlinelatexdvp et sa dérivée kitxmlcodeinlinelatexdvpdf(x) = n \cdot x^{n-1}finkitxmlcodeinlinelatexdvp
2.
3.
4.
5.
6.
>>> def power(x, n):
"""Return x * x * x * ... * x for x repeated n times."""
product, k = 1, 0
while k < n:
product, k = product * x, k + 1
return product
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
>>> def nth_root_of_a(n, a):
def f(x):
return power(x, n) - a
def df(x):
return n * power(x, n-1)
return find_zero(f, df)
>>> nth_root_of_a(2, 64)
8.0
>>> nth_root_of_a(3, 64)
4.0
>>> nth_root_of_a(6, 64)
2.0
L'erreur d'approximation dans tous ces calculs peut être réduite en modifiant la tolérance en approx_eq à un nombre plus petit.
Lorsque vous expérimentez la méthode de Newton, sachez qu'elle ne converge pas toujours. La prévision initiale de improve doit être suffisamment proche du zéro, et diverses conditions concernant la fonction doivent être respectées. Malgré cette lacune, la méthode de Newton est une puissante méthode générale de calcul pour résoudre des équations différentiables. Les algorithmes très rapides pour les logarithmes et la division entière de grands nombres utilisent des variantes de cette technique dans les ordinateurs modernes.
VI-F. La curryfication▲
Nous pouvons utiliser des fonctions d'ordre supérieur pour convertir une fonction qui prend plusieurs arguments en une chaîne de fonctions qui prennent chacun un seul argument. Plus précisément, étant donné une fonction f (x, y), on peut définir une fonction g telle que g (x) (y) équivaut à f (x, y). Ici, g est une fonction d'ordre supérieur qui prend un seul argument x et renvoie une autre fonction qui prend un seul argument y. Cette transformation s'appelle la curryfication.
Par exemple, nous pouvons définir une version curryfiée de la fonction pow :
2.
3.
4.
5.
6.
>>> def curried_pow(x):
def h(y):
return pow(x, y)
return h
>>> curried_pow(2)(3)
8
Certains langages de programmation, comme Haskell, admettent uniquement des fonctions qui prennent un seul argument, si bien que le programmeur doit curryfier toutes les procédures multi-arguments. Dans des langages plus généraux tels que Python, la curryfication est utile lorsque nous exigeons une fonction qui ne comporte qu'un seul argument. Par exemple, le modèle map applique une fonction d'argument unique à une séquence de valeurs. Dans les chapitres suivants, nous verrons des exemples plus généraux du modèle map, mais pour l'instant, nous pouvons implémenter le modèle dans une fonction :
2.
3.
4.
>>> def map_to_range(start, end, f):
while start < end:
print(f(start))
start = start + 1
Nous pouvons utiliser map_to_range et curried_pow pour calculer les dix premières puissances de deux, plutôt que d'écrire spécifiquement une fonction pour le faire
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
>>> map_to_range(0, 10, curried_pow(2))
1
2
4
8
16
32
64
128
256
512
Nous pouvons également utiliser les mêmes deux fonctions pour calculer les puissances d'autres nombres. La curryfication nous permet de le faire sans écrire une fonction spécifique pour chaque nombre dont nous souhaitons calculer les puissances.
Dans les exemples ci-dessus, nous effectuons manuellement la transformation de la curryfication sur la fonction Pow pour obtenir curried_pow. Au lieu de cela, nous pouvons définir des fonctions pour automatiser la curryfication, ainsi que la transformation inverse :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
>>> def curry2(f):
"""Return a curried version of the given two-argument function."""
def g(x):
def h(y):
return f(x, y)
return h
return g
>>> def uncurry2(g):
"""Return a two-argument version of the given curried function."""
def f(x, y):
return g(x)(y)
return f
>>> pow_curried = curry2(pow)
>>> pow_curried(2)(5)
32
>>> map_to_range(0, 10, pow_curried(2))
1
2
4
8
16
32
64
128
256
512
La fonction curry2 prend une fonction de deux arguments f et renvoie une fonction d'argument unique g. Lorsque g est appliqué à un argument x, il renvoie une fonction d'argument unique h. Lorsque h est appliqué à y, il appelle f (x, y). Ainsi, curry2 (f) (x) (y) équivaut à f (x, y). La fonction uncurry2 renverse la transformation de la curryfication, en sorte que uncurry2 (curry2 (f)) équivaut à f.
2.
>>> uncurry2(pow_curried)(2, 5)
32
VI-G. Les expressions lambda▲
Jusqu'à présent, chaque fois que nous voulions définir une nouvelle fonction, nous devions lui donner un nom. Mais pour d'autres types d'expressions, nous n'avons pas besoin d'associer des valeurs intermédiaires à un nom. C'est-à-dire que nous pouvons calculer a * b + c * d sans avoir à nommer les sous-expressions a * b ou c * d ou l'expression complète. En Python, nous pouvons créer des valeurs de fonction à l'aide d'expressions lambda, qui évaluent les fonctions non nommées. Une expression lambda évalue une fonction dont le corps est une seule expression de retour. Les instructions d'affectation et de contrôle ne sont pas autorisées.
Nous pouvons comprendre la structure d'une expression lambda en construisant une phrase anglaise correspondante :
lambda x : f(g(x))
« Une fonction qui prend x en argument et renvoie f(g(x)) »
Le résultat d'une expression lambda s'appelle une fonction lambda. Une telle fonction n'a pas de nom intrinsèque (et donc Python imprime <lambda> pour le nom), mais sinon elle se comporte comme toute autre fonction.
2.
3.
4.
5.
>>> s = lambda x: x * x
>>> s
<function <lambda> at 0xf3f490>
>>> s(12)
144
Dans un diagramme d'environnement, le résultat d'une expression lambda est également une fonction, nommée avec la lettre grecque λ (lambda). Notre exemple de composition peut être exprimé de manière assez compacte avec les expressions lambda.
|
Sélectionnez 1. 2. 3. 4. |
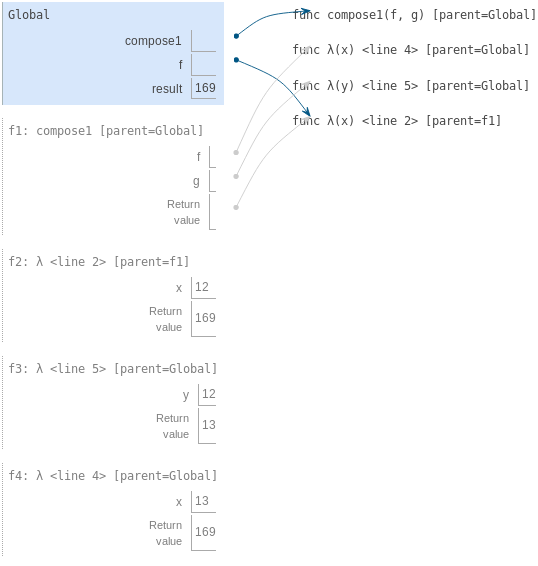 |
Certains programmeurs trouvent que l'utilisation de fonctions non nommées à partir d'expressions lambda est plus courte et plus directe. Cependant, les expressions composées de lambda sont notoirement illisibles, malgré leur brièveté. La définition suivante est correcte, mais de nombreux programmeurs ont du mal à la comprendre rapidement.
>>> compose1 = lambda f,g: lambda x: f(g(x))
En général, le style Python préfère les instructions def explicites aux expressions lambda, mais les autorise dans les cas où une fonction simple est nécessaire comme argument ou valeur de retour.
Ces règles de style ne sont que des lignes directrices. Vous pouvez programmer tout ce que vous souhaitez. Toutefois, quand vous écrivez des programmes, pensez aux personnes qui pourraient lire votre programme un jour. Lorsque vous pouvez rendre votre programme plus facile à comprendre, vous rendez service à ces personnes.
Le terme «lambda» est un accident historique résultant de l'incompatibilité de la notation mathématique écrite et des contraintes des premiers systèmes de détermination du type.
Il peut sembler pervers d'utiliser lambda pour introduire une procédure/fonction. La notation remonte au mathématicien Alonzo Church, qui, dans les années 1930, a commencé par un symbole «chapeau». Il a écrit la fonction carrée comme "ŷ. y × y". Mais les typographes frustrés ont déplacé le chapeau à gauche du paramètre et l'ont changé en lambda majuscule : "Λy. Y × y" ; de là, le symbole lambda majuscule a été changé en minuscule, et maintenant on voit "λy. Y × y" dans les livres de mathématiques et (lambda (y) (* y y)) en Lisp. --Peter Norvig (norvig.com/lispy2.html).
Malgré leur étymologie inhabituelle, les expressions lambda et le langage formel correspondant à l'application de la fonction, le lambda calcul, sont des concepts fondamentaux de calcul l'informatique partagés bien au-delà de la communauté de programmation Python. Nous examinerons ce sujet lorsque nous étudierons la conception des interpréteurs ultérieurement.
VI-H. Abstractions et fonctions de première classe▲
Nous avons commencé cette section en disant que les fonctions définies par l'utilisateur sont un mécanisme d'abstraction crucial, car elles nous permettent d'exprimer des méthodes générales d'informatique comme éléments explicites dans notre langage de programmation. Maintenant, nous avons vu comment les fonctions d'ordre supérieur nous permettent de manipuler ces méthodes générales pour créer d'autres abstractions.
En tant que programmeurs, nous devons être attentifs aux occasions d'identifier les abstractions sous-jacentes dans nos programmes, de les construire et de les généraliser pour créer des abstractions plus puissantes. Cela ne veut pas dire qu'il faille toujours écrire des programmes de la façon la plus abstraite possible. Les programmeurs experts savent comment choisir le niveau d'abstraction approprié à leur tâche. Mais il est important de pouvoir penser à ces abstractions, afin que nous puissions être prêts à les appliquer dans de nouveaux contextes. La signification des fonctions d'ordre supérieur, est qu'elles nous permettent de représenter explicitement ces abstractions comme éléments de notre langage de programmation, afin qu'elles puissent être traitées comme d'autres éléments de calcul.
En général, les langages de programmation imposent des restrictions sur les manières dont les éléments de calcul peuvent être manipulés. Les éléments avec le moins de restrictions sont censés avoir un statut de première classe. Certains des «droits et privilèges» des éléments de première classe sont les suivants :
- ils peuvent être liés à des noms ;
- ils peuvent être transmis comme arguments aux fonctions ;
- ils peuvent être retournés comme résultats de fonctions ;
- ils peuvent être inclus dans les structures de données.
Python confère aux fonctions toutes ces caractéristiques des éléments de première classe, et le gain résultant en puissance expressive est énorme.
VI-I. Décorateurs de fonctions▲
Python fournit une syntaxe spéciale pour appliquer des fonctions d'ordre supérieur dans le cadre de l'exécution d'une déclaration def, appelée décorateur. L'exemple le plus courant est peut-être une fonction de trace :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
>>> def trace(fn):
def wrapped(x):
print('-> ', fn, '(', x, ')')
return fn(x)
return wrapped
>>> @trace
def triple(x):
return 3 * x
>>> triple(12)
-> <function triple at 0x102a39848> ( 12 )
36
Dans cet exemple, une fonction d'ordre supérieur trace est définie et renvoie une fonction qui précède un appel à son argument avec une instruction print qui affiche l'argument. La déclaration def pour triple a une annotation, @trace, qui affecte la règle d'exécution pour def. Comme d'habitude, la fonction triple est créée. Cependant, le nom triple n'est pas lié à cette fonction. Au lieu de cela, le nom triple est lié à la valeur de la fonction retournée avec l'appel de trace sur la fonction triple nouvellement définie. Dans le code, ce décorateur équivaut à :
2.
3.
>>> def triple(x):
return 3 * x
>>> triple = trace(triple)
Dans les projets associés à ce tutoriel, les décorateurs sont utilisés pour le traçage, ainsi que la sélection des fonctions à appeler lorsqu'un programme est exécuté à partir de la ligne de commande.
Extra pour les experts. Le symbole du décorateur @ peut également être suivi d'une expression d'appel. L'expression suivante @ est évaluée en premier (comme le nom trace a été évaluée ci-dessus), la deuxième instruction def et, enfin, le résultat de l'évaluation de l'expression du décorateur est appliqué à la fonction nouvellement définie et le résultat est lié au nom dans l'instruction def. Un court tutoriel sur les décorateurshttp://programmingbits.pythonblogs.com/27_programmingbits/archive/50_function_decorators.htmld'Alexandre GALODE donne d'autres exemples pour les étudiants intéressés.
VII. Les fonctions récursives▲
Une fonction est dite récursive si le corps de la fonction appelle la fonction elle-même, directement ou indirectement. C'est-à-dire que le processus d'exécution du corps d'une fonction récursive peut à son tour exiger l'application de cette fonction à nouveau. Les fonctions récursives n'utilisent aucune syntaxe spéciale dans Python, mais elles nécessitent un effort pour les comprendre et les créer.
Nous allons commencer par un exemple de problème : écrivez une fonction qui somme les chiffres d'un entier naturel. Lors de la conception de fonctions récursives, nous recherchons des façons dont un problème peut être décomposé en des problèmes plus simples. Dans ce cas, les opérateurs % (modulo) et // (division entière) peuvent être utilisés pour séparer un nombre en deux parties : son dernier chiffre et tout sauf son dernier chiffre.
2.
3.
4.
>>> 18117 % 10
7
>>> 18117 // 10
1811
La somme des chiffres de 18117 est 1 + 8 + 1 + 1 + 7 = 18. Tout comme nous pouvons séparer le nombre, nous pouvons séparer cette somme en chiffres, 7 et la somme de tous, sauf le dernier chiffre, 1 + 8 + 1 + 1 = 11. Cette séparation nous donne un algorithme : pour additionner les chiffres d'un nombre n, ajouter son dernier chiffre n % 10 à la somme des chiffres de n // 10. Il existe un cas particulier : si un nombre n'a qu'un seul chiffre, la somme de ses chiffres est elle-même. Cet algorithme peut être implémenté comme une fonction récursive.
2.
3.
4.
5.
6.
7.
>>> def sum_digits(n):
"""Return the sum of the digits of positive integer n."""
if n < 10:
return n
else:
all_but_last, last = n // 10, n % 10
return sum_digits(all_but_last) + last
Cette définition de sum_digits est à la fois complète et correcte, même si la fonction sum_digits est appelée dans son propre corps. Le problème de la sommation des chiffres d'un nombre est divisé en deux étapes : additionner tout sauf le dernier chiffre, puis ajouter le dernier chiffre. Ces deux étapes sont plus simples que le problème initial. La fonction est récursive, car la première étape est le même type de problème que le problème initial. C'est-à-dire que sum_digits est exactement la fonction dont nous avons besoin pour implémenter sum_digits.
2.
3.
4.
5.
6.
7.
8.
>>> sum_digits(9)
9
>>> sum_digits(18117)
18
>>> sum_digits(9437184)
36
>>> sum_digits(11408855402054064613470328848384)
126
Nous pouvons comprendre précisément comment cette fonction récursive s'applique avec succès à l'aide de notre modèle de calcul de l'environnement. Aucune nouvelle règle n'est requise.
|
Sélectionnez 1. 2. 3. 4. 5. 6. 7. 8. |
 |
Lorsque l'instruction def est exécutée, le nom sum_digits est lié à une nouvelle fonction, mais le corps de cette fonction n'est pas encore exécuté. Par conséquent, la nature circulaire de sum_digits n'est pas encore un problème. Puis, sum_digits est appelée sur 738 :
- Un cadre local pour sum_digits avec n borné à 738 est créé et le corps de sum_digits est exécuté dans l'environnement qui commence par ce cadre ;
- Puisque 738 n'est pas inférieur à 10, l'instruction d'affectation à la ligne 4 est exécutée, en scindant 738 en 73 et 8 ;
- Dans l'instruction de retour suivante, sum_digits est appelé sur 73, la valeur de all_but_last dans l'environnement actuel ;
- Un autre environnement local pour sum_digits est créé, cette fois avec n lié à 73. Le corps de sum_digits est de nouveau exécuté dans le nouvel environnement qui commence par ce cadre ;
- Étant donné que 73 n'est pas inférieur à 10, 73 est scindé en 7 et 3 et sum_digits est appelée sur 7, la valeur de all_but_last évaluée dans ce cadre ;
- Un troisième cadre local pour sum_digits est créé, avec n lié à 7 ;
- Dans l'environnement commençant par ce cadre, il est vrai que n <10, et donc 7 est renvoyé ;
- Dans le deuxième cadre local, cette valeur de retour 7 est additionnée de 3, la valeur de last, pour renvoyer 10 ;
- Dans le premier cadre local, cette valeur de retour 10 est additionnée de 8, la valeur de last, pour renvoyer 18.
Cette fonction récursive s'applique correctement, malgré son caractère circulaire, car elle est appliquée deux fois, mais avec un argument différent à chaque fois. En outre, la deuxième application était une instance plus simple du problème de sommation des chiffres que la première. Générer le diagramme d'environnement pour l'appel sum_digits (18117) pour voir que chaque appel successif à sum_digits prend un argument plus petit que le dernier, jusqu'à ce que finalement un argument à un seul chiffre soit atteint.
Cet exemple illustre également comment les fonctions avec des corps simples peuvent faire appel à des processus de calcul complexes en utilisant la récursivité.
VII-A. L'anatomie des fonctions récursives▲
Un modèle commun peut être trouvé dans le corps de nombreuses fonctions récursives. Le corps commence par un cas de base, une déclaration conditionnelle qui définit le comportement de la fonction pour les entrées les plus simples à traiter. Dans le cas de sum_digits, le cas de base est un argument à un seul chiffre, et nous renvoyons simplement cet argument. Certaines fonctions récursives auront plusieurs cas de base.
Les cas de base sont ensuite suivis d'un ou plusieurs appels récursifs. Les appels récursifs ont toujours la caractéristique suivante : ils simplifient le problème original. Les fonctions récursives expriment le calcul en simplifiant progressivement les problèmes. Par exemple, la somme des chiffres de 7 est plus simple que de sommer les chiffres de 73, ce qui est plus simple que de sommer les chiffres de 738. Pour chaque appel subséquent, il reste moins de travail à faire.
Les fonctions récursives résolvent souvent des problèmes de manière différente des approches itératives que nous avons utilisées précédemment. Considérons une fonction fact pour calculer la factorielle de n, où par exemple, fact (4) s'exprime ainsi : 4! = 4*3*2*1 = 24.
Une implémentation naturelle utilisant une instruction while accumule le total en multipliant chaque entier positif par n.
2.
3.
4.
5.
6.
7.
>>> def fact_iter(n):
total, k = 1, 1
while k <= n:
total, k = total * k, k + 1
return total
>>> fact_iter(4)
24
D'un autre côté, une mise en œuvre récursive de la fonction factorielle peut exprimer fact (n) en termes de fact(n-1), un problème plus simple. Le cas de base de la récursion est la forme la plus simple du problème : fact (1) est 1.
|
Sélectionnez 1. 2. 3. 4. 5. 6. |
 |
Ces deux fonctions factorielles diffèrent conceptuellement. La fonction itérative construit le résultat du cas de base de 1 au total final en multipliant successivement chaque terme. La fonction récursive, d'autre part, construit le résultat directement du terme final, n, et le résultat du problème plus simple, fact (n-1).
Comme la récursion "se déroule" par des applications successives de la fonction fact à des instances de plus en plus simples, le résultat est finalement construit à partir du cas de base. La récursion se termine par passer l'argument 1 à la fonction fact. Le résultat de chaque appel dépend du prochain jusqu'à ce que le cas de base soit atteint.
L'exactitude de cette fonction récursive est facile à vérifier à partir de la définition standard de la fonction mathématique factorielle :
Bien que nous puissions dérouler la récursivité en utilisant notre modèle de calcul, il est souvent plus clair de penser aux appels récursifs comme abstractions fonctionnelles. Autrement dit, nous ne devrions pas nous préoccuper du fait que fact (n-1) est implémenté dans le corps de fact. Nous devrions simplement croire qu'il calcule le factorielle de n-1. Traiter un appel récursif comme une abstraction fonctionnelle a été appelé acte de foi récursif. Nous définissons une fonction en soi, mais croyons simplement que les cas plus simples fonctionneront correctement lors de la vérification de l'exactitude de la fonction. Dans cet exemple, nous croyons que ce fact (n-1) calculera correctement (n-1) !. Il suffit de vérifier que n! est calculé correctement si cette hypothèse est valable. De cette façon, vérifier l'exactitude d'une fonction récursive est une forme de preuve par induction.
Les fonctions fact_iter et fact diffèrent également parce que la première doit introduire deux noms supplémentaires, total et k, qui ne sont pas nécessaires dans la mise en œuvre récursive. En général, les fonctions itératives doivent maintenir un état local qui change au cours du calcul. En tout point de l'itération, cet état caractérise le résultat du travail terminé et la quantité de travail restant. Par exemple, lorsque k est 3 et le total est 2, il reste encore deux termes à traiter, 3 et 4. D'autre part, fact est caractérisé par son seul argument n. L'état du calcul est entièrement contenu dans la structure de l'environnement, qui a des valeurs de retour qui prennent le rôle de total et lie n à des valeurs différentes dans différents cadres plutôt que de suivre explicitement k.
Les fonctions récursives utilisent les règles d'évaluation des expressions d'appel pour lier les noms aux valeurs, évitant souvent l'inconvénient d'attribuer correctement les noms locaux pendant l'itération. Pour cette raison, les fonctions récursives peuvent être plus faciles à définir correctement. Cependant, apprendre à reconnaître les processus de calcul évolués par des fonctions récursives nécessite certainement une pratique.
VII-B. Recursivité mutuelle▲
Lorsqu'une procédure récursive est divisée entre deux fonctions qui s'appellent, les fonctions sont mutuellement récursives. Par exemple, considérez la définition suivante des entiers non négatifs pairs et impairs :
- un nombre est pair s'il dépasse de un (1) un nombre impair ;
- un nombre est impair s'il dépasse de un (1) un nombre pair ;
- 0 est pair.
En utilisant cette définition, nous pouvons implémenter des fonctions mutuellement récursives pour déterminer si un nombre est pair ou impair :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
def is_even(n):
if n == 0:
return True
else:
return is_odd(n-1)
def is_odd(n):
if n == 0:
return False
else:
return is_even(n-1)
result = is_even(4)
Les fonctions mutuellement récursives peuvent être transformées en une seule fonction récursive en rompant la limite d'abstraction entre les deux fonctions. Dans cet exemple, le corps de is_odd peut être incorporé à celui de is_even, en vous assurant de remplacer n par n-1 dans le corps de is_odd pour refléter l'argument passé dans celui-ci :
2.
3.
4.
5.
6.
7.
8.
>>> def is_even(n):
if n == 0:
return True
else:
if (n-1) == 0:
return False
else:
return is_even((n-1)-1)
En tant que telle, la récursivité mutuelle n'est pas plus mystérieuse ou puissante que la récursivité simple, et elle fournit un mécanisme pour maintenir l'abstraction dans un programme récursif compliqué.
VII-C. Impression dans des fonctions récursives▲
Le processus de calcul d'une fonction récursive peut souvent être visualisé à l'aide d'appels à la fonction print. Par exemple, nous mettrons en œuvre une fonction cascade qui imprime tous les préfixes d'un nombre du plus grand au plus petit.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
>>> def cascade(n):
"""Print a cascade of prefixes of n."""
if n < 10:
print(n)
else:
print(n)
cascade(n//10)
print(n)
>>> cascade(2013)
2013
201
20
2
20
201
2013
Dans cette fonction récursive, le cas de base est un nombre à un seul chiffre, qui est imprimé. Sinon, un appel récursif est placé entre deux appels de print.
Ce n'est pas une exigence rigide que les cas de base soient exprimés avant les appels récursifs. En fait, cette fonction peut être exprimée de manière plus compacte en observant que print (n) est répétée dans les deux clauses de l'instruction conditionnelle et peut donc la précéder.
2.
3.
4.
5.
6.
>>> def cascade(n):
"""Print a cascade of prefixes of n."""
print(n)
if n >= 10:
cascade(n//10)
print(n)
Comme autre exemple de récursivité mutuelle, considérez un jeu à deux joueurs dans lequel il y a au départ n jetons sur une table. Les joueurs se relayent, enlevant soit un ou deux cailloux de la table, et le joueur qui élimine le caillou final gagne. Supposons qu'Alice et Bob jouent à ce jeu, chacun en utilisant une stratégie simple :
- Alice enlève toujours un seul caillou ;
- Bob élimine deux cailloux si le nombre de cailloux sur la table est pair, et un seul caillou dans le cas contraire.
Étant donné n cailloux initiaux, si Alice commence, qui gagne le jeu ?
Une décomposition naturelle de ce problème est d'encapsuler chaque stratégie dans sa propre fonction. Cela nous permet de modifier une stratégie sans affecter l'autre, en maintenant la barrière d'abstraction entre les deux. Afin d'intégrer la nature du jeu, ces deux fonctions s'appellent à la fin de chaque tour.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
>>> def play_alice(n):
if n == 0:
print("Bob wins!")
else:
play_bob(n-1)
>>> def play_bob(n):
if n == 0:
print("Alice wins!")
elif is_even(n):
play_alice(n-2)
else:
play_alice(n-1)
>>> play_alice(20)
Bob wins!
Dans play_bob, nous voyons que plusieurs appels récursifs peuvent apparaître dans le corps d'une fonction. Cependant, dans cet exemple, chaque appel à play_bob appelle play_alice au plus une fois. Dans la section suivante, nous considérons ce qui se produit lorsqu'un appel de fonction unique effectue plusieurs appels récursifs directs.
VII-D. Recursivité arborescente▲
Un autre modèle de calcul commun est appelé récursivité arborescente, dans lequel une fonction se déclenche plus d'une fois. Par exemple, considérez le calcul de la séquence des nombres de Fibonacci, dans laquelle chaque nombre est la somme des deux précédents.
2.
3.
4.
5.
6.
7.
8.
9.
def fib(n):
if n == 1:
return 0
if n == 2:
return 1
else:
return fib(n-2) + fib(n-1)
result = fib(6)
Cette définition récursive est extrêmement attrayante par rapport à nos tentatives précédentes : elle reflète exactement la définition familière des nombres de Fibonacci. Une fonction avec plusieurs appels récursifs est dite arborescente, car chaque appel se ramifie en plusieurs appels plus petits, dont chacun se ramifie dans des appels encore plus petits, de même que les branches d'un arbre deviennent plus petites, mais plus nombreuses à mesure qu'elles s'éloignent du tronc.
Nous avons déjà pu définir une fonction pour calculer les nombres de Fibonacci sans récursivité arborescente. En fait, nos précédentes tentatives étaient plus efficaces, un sujet abordé plus loin dans le tutoriel. Ensuite, nous considérons un problème pour lequel la solution récursive de l'arborescence est sensiblement plus simple que n'importe quelle alternative itérative.
VII-E. Exemple : partitions▲
Le nombre de partitions d'un entier positif n, en utilisant des parties de taille m, est le nombre de façons dont n peut être exprimé comme la somme des parties entières positives de taille m dans un ordre croissant. Par exemple, le nombre de partitions de 6 utilisant des parties jusqu'à 4 est de 9.
- 6 = 2 + 4
- 6 = 1 + 1 + 4
- 6 = 3 + 3
- 6 = 1 + 2 + 3
- 6 = 1 + 1 + 1 + 3
- 6 = 2 + 2 + 2
- 6 = 1 + 1 + 2 + 2
- 6 = 1 + 1 + 1 + 1 + 2
- 6 = 1 + 1 + 1 + 1 + 1 + 1
Nous définirons une fonction count_partitions (n, m) qui renvoie le nombre de partitions différentes de n en utilisant des parties jusqu'à m. Cette fonction a une solution simple en tant que fonction récursive sur la base de l'observation suivante :
le nombre de façons de partitionner n en utilisant des nombres entiers jusqu'à m est égal à :
- le nombre de façons de partitionner n-m en utilisant des nombres entiers jusqu'à m ; et le nombre de façons de partitionner n en utilisant des nombres entiers jusqu'à m-1.
Pour voir pourquoi cela est vrai, observez que toutes les façons de partitionner n peuvent être divisées en deux groupes : ceux qui incluent au moins un m et ceux qui ne le font pas. De plus, chaque partition dans le premier groupe est une partition de n-m, suivie de m ajoutée à la fin. Dans l'exemple ci-dessus, les deux premières partitions contiennent 4, et les autres non.
Par conséquent, nous pouvons réduire de manière récurrente le problème du partitionnement n en utilisant des nombres entiers jusqu'à m dans deux problèmes plus simples : (1) partitionner un nombre plus petit n-m, et (2) partitionner avec des composants plus petits jusqu'à m-1.
Pour compléter la mise en œuvre, nous devons spécifier les cas de base suivants :
- Il existe une façon de partitionner 0 : ne comprend pas de parties ;
- Il existe 0 façon de partitionner un n négatif ;Il existe 0 façon de partitionner tout n supérieur à 0 en utilisant des parties de taille 0 ou moins.
>>> def count_partitions(n, m):
"""Count the ways to partition n using parts up to m."""
if n == 0:
return 1
elif n < 0:
return 0
elif m == 0:
return 0
else:
return count_partitions(n-m, m) + count_partitions(n, m-1)
>>> count_partitions(6, 4)
9
>>> count_partitions(5, 5)
7
>>> count_partitions(10, 10)
42
>>> count_partitions(15, 15)
176
>>> count_partitions(20, 20)
627On peut penser qu'une fonction récursive arborescente est l'exploration de différentes possibilités. Dans ce cas, nous explorons la possibilité que nous utilisions une partie de taille m et la possibilité que nous ne le fassions pas. Les premier et deuxième appels récursifs correspondent à ces possibilités.
La mise en œuvre de cette fonction sans récurrence serait beaucoup plus complexe. Les lecteurs intéressés sont encouragés à essayer.
VIII. Remerciements▲
Nous remercions Laethypour la traduction, Lolo78 pour la relecture technique et Jacques_jean pour la relecture orthographique.