



I. SciPy▲
SciPy fournit un environnement de logiciels libres pour Python afin de faire des mathématiques, des sciences ou de l’ingénierie. En pratique, le terme « SciPy » fait référence à plusieurs entités :
- un écosystème de logiciels ;
- une communauté de personnes ;
- des conférences dédiées à Python et les sciences ;
- et enfin la bibliothèque SciPy, un composant de la couche SciPy qui fournit des routines pour les données numériques.
I-A. L’écosystème SciPy▲
Faire de la science informatisée avec Python repose sur un nombre restreint de paquets :
- NumPy, le module pour le calcul numérique, qui définit le tableau numérique, le type matrix et les opérations basiques qui leur sont associées ;
- La bibliothèque SciPy, une collection d’algorithmes numériques et des boîtes à outils spécifiques à des domaines tels que le traitement du signal, l’optimisation et les statistiques ;
- Matplotlib, un module abouti pour réaliser des graphiques qui fournit des fonctions pour produire des graphiques 2D adaptés à la publication et quelques fonctions pour les graphiques 3D.
L’écosystème SciPy repose sur cette base pour ensuite proposer des outils plus spécialisés. Un aperçu de quelques‐uns de ces outils est donné dans la suite de l’article.
I-B. Calculs et gestion des données▲
- pandas, qui fournit des structures de données simples à utiliser et performantes ;
- SymPy, pour faire des mathématiques symboliques et de l’algèbre computationnelle ;
- scikit-image, un ensemble d’algorithmes pour le traitement de l’image ;
- scikit-learn, un ensemble d’algorithmes et d’outils pour l’apprentissage automatique ;
- h5py et PyTables, qui permettent tous deux d’accéder à des données enregistrées au format HDF5 ; HDF5 est un modèle de données, une bibliothèque et un format de fichier pour enregistrer et gérer des données massives et complexes.
I-C. Productivité et calculs haute performance▲
- IPython, qui est une interface interactive et complète qui vous permet de facilement travailler vos données et d’essayer vos idées ;
- le carnet Jupyter, une application en mode serveur qui permet de créer des documents de code en direct, avec des équations, des visualisations et des explications ; les carnets facilitent la reproduction, la réutilisation et le partage de code, que ce soit au niveau d’une équipe de recherche, pour la publication scientifique ou dans le cadre d’un cours ;
- Cython, qui étend la syntaxe Python pour faciliter le développement d’extensions en C/C++ ;
- Dask, Joblib et IPyParallel, qui sont des modules Python pour distribuer le traitement des tâches ; ces modules sont orientés vers le traitement de données numériques.
I-D. Gestion de la qualité▲
I-E. Jupyter▲
Jupyter-notebook est une application Web libre (BSD 3 Clause License) qui permet de partager des documents contenant code, équations, visualisations et texte. Python n’est pas le seul langage géré, plus de quarante langages sont pris en charge, dont R et Scala.
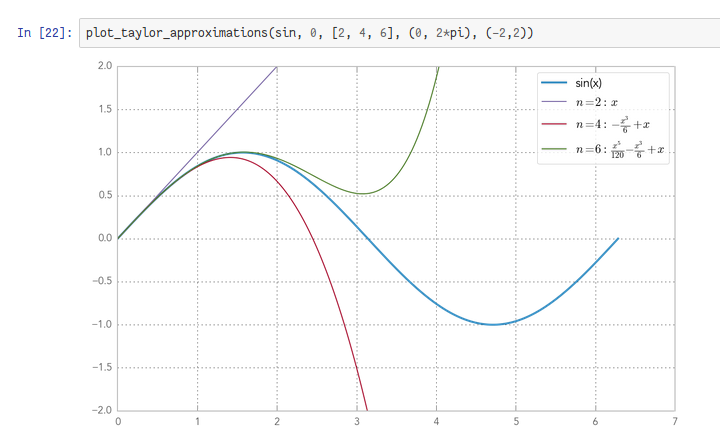
Du point de vue de l’interface, il s’agit d’une console sous stéroïdes : on retrouve donc l’alternance entre des commandes et leurs sorties dans un environnement d’exécution. Le notebook de Jupyter ajoute à cela trois fonctionnalités majeures :
- la persistance de la session, ce qui permet de sauver toute une série de commandes et de la recharger ;
- l’édition et l’exécution de commandes par blocs ; le notebook se comporte ainsi comme un long script découpé en morceaux que l’on peut exécuter à la demande, ce qui est extrêmement utile pour des projets scientifiques exploratoires où l’on teste des idées à la chaîne ;
- la prise en charge de sorties graphiques comme des graphes, des images ou du texte mis en forme comme sur cet exemple. La bibliothèque Pandas présentée ci‐dessus ajoute aussi sa méthode de rendu pour mettre en forme les tableaux de données et faciliter la lecture.
Sur le plan technique, ce logiciel est découpé en trois parties : le serveur qui gère les sessions, les consoles (~onglets d’un terminal) qui affichent les blocs de code et leurs sorties, et enfin, pour chaque console, un noyau qui exécute les instructions dans un environnement persistant.
La conception du projet est volontairement modulable et facilite l’ajout de fonctionnalités via des extensions tierces, comme les méthodes de rendu pour les graphiques et les données.
II. Pandas▲
Pandas est une bibliothèque sous licence BSD pour manipuler et analyser des données. Il permet de lire des tableaux provenant de différents types de fichiers (CSV, Excel, JSON), de filtrer des tableaux, de faire des extrapolations, des interpolations, de fusionner des tableaux de différentes manières. Pandas permet également de manipuler des données temporelles et des séries.
Il se combine idéalement avec iPython ou Jupyter afin de profiter d’un environnement dynamique pour développer des scripts. À noter qu’à partir de janvier 2019, les prochaines versions de Pandas ne fonctionneront qu’avec Python 3. Cette version est donc la dernière à fonctionner officiellement avec Python 2.7. Les versions 3.5, 3.6 et 3.7 sont aussi prises en compte. La liste des nouveautés et des corrections de cette nouvelle version est longue. Sans entrer dans les détails, voici les principales :
merge() permet maintenant de fusionner directement des objets du type DataFrame et Series sans passer par une conversion des objets Serie en DataFrame (GH21220) ;- ExcelWriter accepte dorénavant mode comme argument afin de permettre l’ajout à un workbook (? à vérifier) existant lors de l’utilisation d’openpyxl (GH3441) ;
- FrozenList s’est vu ajouter les méthodes .
union() et .difference(), cette fonctionnalité simplifie les groupby qui s’appuient explicitement sur l’exclusion de certaines colonnes — voir « Splitting an object into groups » pour davantage de précisions (GH15475, GH15506) ; - DataFrame.
to_parquet() permet d’avoir un index comme argument, afin que l’utilisateur puisse outrepasser le comportement par défaut du moteur pour inclure ou au contraire omettre les index du DataFrame dans le fichier Parquet produit (GH20768) ; - DataFrame.
corr() et Series.corr() acceptent maintenant les appels pour les méthodes de calculs génériques des corrélations, comme l’intersection d’histogrammes (GH22684) ; - DataFrame.
to_string() accepte maintenant les décimaux comme argument, l’utilisateur peut spécifier quel séparateur décimal devra être utilisé dans la sortie (GH23614).
Quelques exemples de manipulation de données avec Pandas à partir du fichier tournagesdefilmsparis2011.csv :
import pandas as pd
datafile = "tournagesdefilmsparis2011.csv"
data = pd.read_csv(datafile, sep=";")
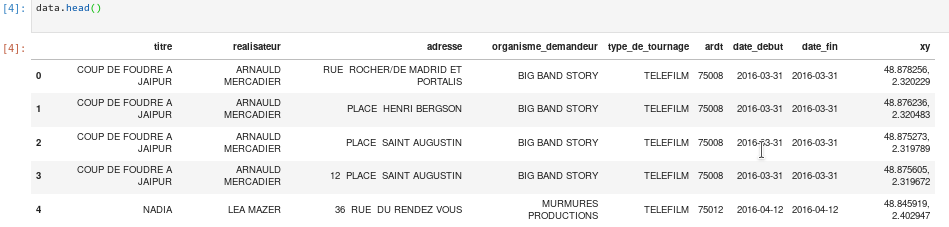
[5, 4]])data.head() affiche les premières lignes du DataFrame pandas.
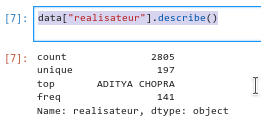
data["realisateur"].describe() permet de décrire à travers les opérations statistiques de base une catégorie. Ici, il s’agit d’une catégorie non numérique, describe ne peut faire réaliser les moyennes, quartiles et autres opérations de base.
Évidemment, une utilisation plus avancée de Pandas est possible. :) Il est possible de joindre plusieurs bases dans un dataframe avec la fonction merge() ou de procéder à manipuler les données avec des expressions rationnelles via replace().
Au niveau interopérabilité, des solutions existent pour enregistrer les dataframes de Pandas en fichier CSV, ODS ou Excel.
III. Scikit-learn▲
Scikit learn est une bibliothèque libre pour Python dédiée à l’apprentissage automatique. Elle est le plus souvent utilisée de pair avec Pandas, Matplotlib et les bibliothèques du projet SciPy. Scikit Learn fournit des fonctions pour analyser des données avec des algorithmes liés à l’apprentissage automatique (forêts aléatoires, régressions logistiques, algorithmes de classification et machines à vecteurs de support).
IV. Matplotlib▲
Matplotlib est une bibliothèque pour réaliser des graphiques en 2D de qualité publication, dans une variété de formats de papier et d’environnements interactifs sur différentes plates‐formes. Matplotlib peut être utilisé dans les scripts Python, les interpréteurs de commandes Python et IPython, les carnets Jupyter et les serveurs d’applications Web.
Matplotlib essaie de rendre les choses faciles et les choses difficiles possibles. Il vous aide à produire des graphiques, des histogrammes, des spectres de puissance, des diagrammes à barres, des diagrammes d’erreurs, des diagrammes de dispersion. Pour des exemples, voir ceux de la galerie.
Les graphiques qui sont présentés dans cet article ont été réalisés avec Matplotlib.
V. Statsmodels▲
statsmodels est un module Python qui fournit des classes et des fonctions pour réaliser les estimations issues de nombreux modèles statistiques (comme ANOVA ou MANOVA, par exemple), faire des tests statistiques et explorer des données statistiques. Une liste exhaustive de statistiques sur les résultats est disponible pour chaque estimateur. Les résultats sont testés par rapport aux progiciels statistiques existants pour s’assurer qu’ils sont corrects.
VI. Numpy▲
Numpy est la bibliothèque de référence pour le calcul numérique en Python. La plupart des projets scientifiques s’appuient dessus et de nombreuses bibliothèques sont compatibles avec ce projet.
La bibliothèque Numpy sert à résoudre deux problèmes principaux :
- stocker « en mémoire » et accéder à des données structurées en tableaux ;
- effectuer des opérations algébriques de base sur ces données.
Pour ce faire, Numpy propose un type np.ndarray pour représenter des tableaux de données multidimensionnelles. Ces données sont accessibles facilement par indexation ou par tranches :
>>> import numpy as np
>>>
>>> data = np.array([[1, 2, 3],
... [4, 5, 6]])
>>> print(data[0, :]) # première ligne
array([1, 2, 3])
>>> print(data[:, 1]) # deuxième colonne
array([2, 5])
>>> data[:, [1, 0]] # réindexation des colonnes
array([[2, 1],
[5, 4]])Une multitude d’opérations de base sont disponibles : addition, produit, transposition, etc. Leur implémentation est souvent extrêmement efficace afin de minimiser le temps de calcul et l’empreinte en mémoire. L’efficacité de ces opérations repose en grande partie sur le fait que les données à traiter sont d’un type prédéfini (ex. : entier int32 ou flottant float64) et stockées de manière contiguë, ce qui permet d’optimiser les boucles d’opérations et d’utiliser des instructions vectorisées. Le code critique est d’ailleurs rarement écrit en Python : des bibliothèques de liaison (bindings) vers des bibliothèques écrites en C, Fortran ou assembleur sont souvent utilisées (openblas, intel-mkl).
Tout en étant assez étoffée en termes de fonctionnalités, l’interface de programmation reste plutôt simple et idiomatique, ce qui permet d’avoir un code compact et facile à comprendre. On notera en particulier la surcharge des opérateurs sur les objets np.ndarray qui donne ainsi accès à l’addition, la soustraction, ou le produit terme à terme en respectant les conventions d’usage sur l’expansion des dimensions :
>>> data + np.array([[-1, -2, -3]]) + 1
array([[1, 1, 1],
[4, 4, 4]])Les autres opérations sont implémentées par une multitude de fonctions assez bien documentées dans l’ensemble, même si l’aspect didactique est légèrement moins soigné que pour MATLAB.
Le champ d’application de Numpy se limite néanmoins aux opérations mathématiques élémentaires : on n’y trouvera donc pas de traitement du signal comme les convolutions 2D ou le filtrage ou la gestion du stockage des données sur disque, qui reste minimale.
Ce sont d’autres modules qui apportent ces fonctions supplémentaires, avec notamment une série de modules scikit-* développés en étroite collaboration avec NumPy : scikit-image, scikit-video, scikit-learn…
VII. Des compilateurs pour accélérer les traitements▲
Python reste un langage interprété dont la conception ne favorise pas particulièrement la performance à l’exécution, en tout cas avec l’interpréteur standard CPython.
Ainsi, les traitements des données avec des boucles for et des embranchements if … then … else ne sont pas particulièrement rapides. Les possibilités de traitement parallèle sont par ailleurs assez faibles en raison de l’utilisation d’un verrou global pour se protéger des erreurs d’accès concurrent.
Il est donc parfois nécessaire d’aller plus loin dans la recherche de la performance que ce que NumPy propose par défaut. Considérons par exemple le code suivant :
def np_cos_norm(a, b):
val = np.sum(1. - np.cos(a-b))
return np.sqrt(val / 2. / a.shape[0])Il peut encore être accéléré en utilisant un des compilateurs pour Python (scientifique) qui existe. Chacun de ces compilateurs permet un gain plus ou moins grand en performance, et demande une modification plus ou moins intrusive du code, tout en imposant des contraintes de déploiement plus ou moins fortes.
VII-A. Cython▲
Le code précédent s’écrirait en Cython :
# cython: boundscheck = False
# cython: wraparound = False
# cython: cdivision = True
cimport numpy as np
from libc.math cimport cos, sqrt
def np_cos_norm(np.ndarray[double, ndim=1] a, np.ndarray[double, ndim=1] b):
cdef unsigned i, n
cdef double val = 0., res
n = a.shape[0]
for i in range(n):
val += 1. - cos(a[i]-b[i])
res = sqrt(val / 2. / n)
return resCython se charge de traduire ce code en C, avec la possibilité (vérifiable avec le mode cython -a) de donner assez d’information au compilateur pour que les parties gourmandes en calcul ne fassent aucun appel à l’environnement d’exécution C. Ce code C est ensuite compilable en un module dynamique classique.
D’un point de vue langage, on notera les commentaires en début de fichier qui permettent au compilateur de faire des hypothèses supplémentaires lors de la génération de code. Plusieurs mots clefs (cdef, cimport…) viennent étendre le langage et indiquer au compilateur les identifiants appartenant au monde natif et celles (les autres) appartenant au monde interprété.
VII-B. Numba▲
Le code précédent s’écrirait en Numba :
from numba import jit
@jit
def np_cos_norm(a, b):
n = a.shape[0]
for i in range(n):
val += 1. - cos(a[i]-b[i])
return sqrt(val / 2. / n)Numba va dériver à l’exécution une version statique de cette fonction, la compiler à la volée et utiliser le noyau généré en lieu et place de la fonction d’origine.
La compilation en code natif repose sur LLVM, et des options peuvent être passées au compilateur à travers des arguments du décorateur, p. ex. @jit(nopython=True) pour déclencher une erreur si la traduction en code natif ne faisant pas référence à l’API Python a échoué. Un cache évite de relancer cette compilation à chaque appel.
VII-C. Pythran▲
Le code précédent s’écrirait en Pythran :
# pythran export np_cos_norm(float64[], float64[])
def np_cos_norm(a, b):
val = np.sum(1. - np.cos(a-b))
return np.sqrt(val / 2. / a.shape[0])Le compilateur Pythran va traduire ce code en un module natif avec la garantie qu’aucun appel interprété ne sera fait pour exécuter le corps de la fonction np_cos_norm.
La compilation se fait en avance de phase à travers pythran mon_module.py. Il est possible de contrôler finement le processus de compilation en passant des drapeaux de compilation spécifiques : -Ofast, -march=native, voire de générer du code SIMD avec -DUSE_XSIMD.
VII-D. Les logiciels à base de graphes de calculs▲
Conçus à l’origine pour faciliter le travail sur les réseaux de neurones, il serait dommage de sous‐estimer les autres usages possibles des bibliothèques Tensorflow ou PyTorch et anciennement Theano.
Ces bibliothèques permettent de définir des algorithmes sous la forme d’un graphe d’opérations symboliques défini très naturellement. L’exemple ci‐dessous démontre qu’il s’agit quasiment du même code qu’avec Numpy. Ce graphe est ensuite optimisé puis compilé pour une exécution rapide sur processeur central ou graphique.
Les moyens importants alloués au développement de ces projets assurent un excellent support, un haut niveau d’optimisation et une documentation d’assez bonne qualité complétée par d’innombrables tutoriels.
def tf_cos_norm(a, b):
val = tf.reduce_sum(1. - tf.cos(a-b))
return tf.sqrt(val / 2. / tf.cast(a.shape[0], 'float32'))
a = tf.placeholder(dtype='float32', shape=[4])
b = tf.placeholder(dtype='float32', shape=[4])
y = tf_cos_norm(a, b) # résultat symbolique
with tf.Session() as sess:
y_eval = sess.run(
y,
feed_dict={
a: [1, 2, 3, 4],
b: [4, 3, 2, 1]
})Accessoirement, si l’on peut dire, ces logiciels offrent la différentiation automatique, c’est‐à‐dire que pour un graphe de calculs donné, on peut réclamer la dérivée d’une grandeur à l’un des nœuds en fonction d’une autre.
Remerciements Developpez.com▲
Developpez.com remercie LeJocelyn pour la mise à disposition de ce tutoriel. Tous nos remerciements aussi à Vincent Viale pour la mise au gabarit et Claude Leloup pour la relecture orthographique.