



I. Introduction▲
Ce tutoriel est une introduction au scraping avec Scrapy, un module Python.
Le scraping, plus précisément le web scraping, est, selon Wikipédia :
[…] une technique d'extraction du contenu de sites Web, via un script ou un programme, dans le but de le transformer pour permettre son utilisation dans un autre contexte comme l'enrichissement de bases de données, le référencement ou l'exploration de données.
Pour faire simple, le scraping est un procédé d’extraction de données de sites web. En guise d’exemple, les robots des moteurs de recherche font du scraping sur Internet, puisqu’ils récoltent, entre autres, les URLs des sites sur la toile pour faire avec ce que bon leur semble.
II. Avertissement▲
Attention, le scraping est une activité qui pourrait frôler l’illégalité : en effet le 30 avril 2020, la CNIL a publié de nouvelles directives sur le web scraping. Les lignes directrices de la CNIL précisent que les données accessibles au public sont toujours des données personnelles et qu'elles ne peuvent pas être réutilisées à l'insu de la personne à laquelle ces données appartiennent.
III. Installation de Scrapy▲
Scrapy est une librairie Python, il faut donc au préalable avoir un environnement Python (la version 3 évidemment) d’installé.
Télécharger le dépôt git suivant : https://github.com/ABD-Z/Scrapy-startup-project.git
C’est une base de projet Scrapy pour bien démarrer le tutoriel.
Maintenant, il faut installer la librairie Scrapy :
1. Créez un environnement virtuel, dédié pour ce projet, que l’on va nommer par manque d’originalité venv : python -m venv venv.
2. Lancer la commande suivante pour rentrer dans l’environnement virtuel : source venv/Scripts/activate ou bien sur Windows : .venv\Scripts\activate.
3. Une fois rentré dans l’environnement virtuel, la console précise que nous sommes bien dans l’environnement (venv). Nous pouvons installer Scrapy : pip install Scrapy.
L’étape concernant la virtualisation de l’environnement Python pour chaque projet est certes facultative, mais elle est vivement recommandée afin de ne pas casser des dépendances entre les librairies tierces téléchargées via pip.
Une fois Scrapy installé, vous pouvez désormais lancer la commande scrapy --version.
Le dossier téléchargé est un projet Scrapy à compléter en suivant le tutoriel. Il a la structure suivante :
scrapy_startup_spider/
├─ spiders/
│ ├─ __init__.py
│ ├─ quotes.py
├─ __init__.py
├─ items.py
├─ pipelines.py
├─ middlewares.py
├─ settings.py
scrapy.cfg
Si vous souhaitiez démarrer un nouveau projet Scrapy de zéro, lancez la commande scrapy startproject <le_nom_de_votre_projet> [le_répertoire_du_projet].
Nous allons revenir sur la structure du projet et les fichiers contenus ultérieurement.
IV. Le parsing d’une page web▲
Le parsing consiste à parcourir le contenu d’une page HTML d’un site donné, d’analyser sa structure et d’en extraire des éléments.
Dans le terminal, nous allons utiliser le shell de Scrapy pour faire des petits tests de ses fonctions de parsing.
Lancer le shell de Scrapy :
scrapy shell
Nous allons utiliser ce site http://quotes.toscrape.com/ en guise d’exemple pour apprendre à « scraper » :
fetch('http://quotes.toscrape.com/')
La fonction fetch permet de récupérer une URL que l’on fournit en paramètre. L’objet renvoyé est response.
Si l’on affiche response dans le Scrapy shell, on obtient <200 http://quotes.toscrape.com/> soit le code de statut HTTP et l’URL requêtée (200 étant le code de succès).
Avant de continuer avec le terminal, observons dans un premier temps la page Web pour analyser sa structure.
|
|
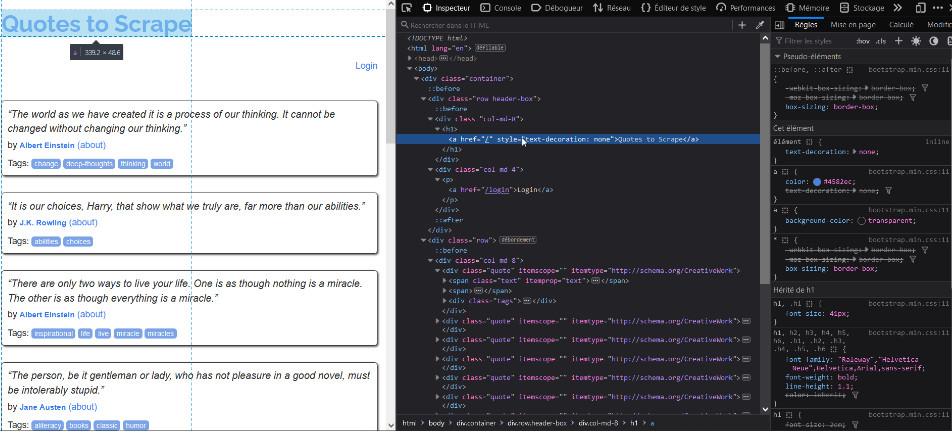
Cette tâche consiste à repérer les blocs HTML contenant les données qui sont susceptibles de nous intéresser pour pouvoir les « parser » avec Scrapy.
Afin d’extraire un bloc HTML avec Scrapy, on doit utiliser une fonction de sélecteur qui prend en paramètre la ou les balises HTML, avec éventuellement les attributs de la balise (style, lien, etc.).
Pour ce faire, il est possible de sélectionner un bloc HTML soit avec un sélecteur Xpath, soit un sélecteur CSS.
Nous voudrions par exemple sélectionner le titre de la page qui est contenu dans une balise h1 :
response.css('h1')
ou bien :
response.xpath('//h1')
Scrapy renvoie respectivement :
[<Selector query='descendant-or-self::h1' data='<h1>\n <a href="/" ...'>]
[<Selector query='//h1' data='<h1>\n <a href="/" ...'>]Les champs data renvoyés par sélecteur Xpath ou CSS sont identiques.
Pour avoir la donnée, il faut donc appeler la fonction get() :
response.css('h1').get()
ou bien :
response.xpath('//h1').get()
On obtient le même résultat :
'<h1>\n <a href="/" style="text-decoration: none">Quotes to Scrape</a>\n </h1>'La fonction get() renvoie le champ data de la sélection.
Cependant, dans notre exemple, le résultat renvoie tout le contenu de la balise <h1>, ce qui n’est pas intéressant… Il faut donc étoffer le sélecteur :
response.css('h1 a').get()
ou bien
response.xpath('//h1/a').get().
Le résultat obtenu est :
'<a href="/" style="text-decoration: none">Quotes to Scrape</a>'
On y est presque. Il faut explicitement demander au sélecteur de sélectionner uniquement le texte comme suit :
response.css('h1 a::text').get()
ou bien
response.xpath('//h1/a/text()').get().
Nous souhaitons désormais sélectionner les citations. Ceci est possible en une seule ligne de code.
Ci-dessous la structure HTML d’un bloc de citation :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>
<span>by <small class="author" itemprop="author">Albert Einstein</small>
<a href="/author/Albert-Einstein">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" itemprop="keywords" content="change,deep-thoughts,thinking,world">
<a class="tag" href="/tag/change/page/1/">change</a>
<a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a>
<a class="tag" href="/tag/thinking/page/1/">thinking</a>
<a class="tag" href="/tag/world/page/1/">world</a>
</div>
</div>
Le texte de citation se trouve dans le bloc span du bloc div dont sa classe est quote.
La sélection en CSS est plus intuitive :
response.css('div.quote span::text').get()
On obtient la première citation :
'“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”'
Cela demande de taper plus du clavier pour avoir le même résultat en Xpath :
response.xpath('//div[@class="quote"]/span/text()').get()
Ainsi, pour avoir la liste de toutes les citations, il suffit d’appeler getall() à la place de get().
V. Programmation d’une araignée▲
Désormais, comme nous connaissons la structure du site, nous pouvons attaquer la programmation du spider ou araignée.
Un spider est un bot, ou programme conçu pour parcourir les pages d’un site, suivre les liens d’une page à une autre et en extraire les données.
Pour ce tutoriel, nous allons concevoir un spider qui extrait les citations avec les données qui vont avec (nom de l’auteur, et tags).
Dans le dossier scrapy_startup_spider/spiders du projet, nous avons un début de spider dans le fichier quotes.py. En effet, la classe QuotesSpider est un spider minimal héritant de scrapy.Spider qui contient les champs :
- name: c’est le nom qui identifie le spider que l’on va utiliser pour lancer son exécution ;
- start_urls : est une liste d’URLs de site que l’araignée va parcourir ;
- allowed_domains : est une liste contenant uniquement les domaines dont le spider a le droit de parcourir. C’est en quelque sorte une mesure de sécurité pour que le spider ne s’éparpille pas lorsqu’il enchaîne l’indexation d’URLs trouvées en chemin (ce champ est assez facultatif pour démarrer notre spider pour ce tutoriel).
Le spider contient aussi une implémentation de la méthode parse, prenant en paramètre response, la réponse de la requête, que nous allons compléter.
Le programme tel quel est exécutable. Pour ce faire, lancez dans un premier temps la commande scrapy list. Cette dernière renvoie la liste des spiders ; en ce qui nous concerne, elle renvoie quotes, le nom de notre spider.
Pour exécuter, il suffit d’appeler
scrapy crawl <le_nom_du_spider> -O <nom_de_fichier>.<json|jsonl|csv|xml>.
La commande va renvoyer les résultats dans un fichier en JSON, CSV ou XML. Au choix !
Exécutons pour voir : scrapy crawl quotes -O citations.json.
Il se passe beaucoup de choses dans la console. On voit que la requête vers robots.txt du site échoue, mais que celle vers le site aboutit.
[scrapy.core.engine] DEBUG: Crawled (404) <GET http://quotes.toscrape.com/robots.txt> (referer:None)
[scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/> (referer:None)Le fichier citations.json est généré. Mais il ne contient rien, car la fonction parse est vide.
Lorsqu’on lance un spider, Scrapy va requêter les URLs stockées dans le champ start_url de la classe héritant scrapy.Spider. À chaque requête, une réponse (response) lui est associée ; et pour chaque réponse, Scrapy appelle la méthode parse. Cette méthode doit yield soit un dictionnaire, soit un objet scrapy.Item (voir le fichier scrapy_startup_spider/items.py), soit une requête scrapy.Request ou soit rien du tout (None). Mais dans la finalité, le programme doit yield un dictionnaire ou un scrapy.Item , car le retour en scrapy.Request se fait pour scraper une autre page lorsqu’on tombe sur une URL pendant le scraping d’une page courante.
Renvoyer un dictionnaire peut sembler être l’option la plus intuitive, mais je conseille d’éviter cette pratique et d’utiliser l’optionscrapy.Item car elle offre plus de flexibilité.
Notre classe scrapy.Item, définie sous le nom de QuoteItem dans le fichier scrapy_startup_spider/items.py, est composée de trois attributs – text, author et tags – définis en tant que scrapy.Field().
Voici la méthode parse (je préfère le sélecteur CSS) :
2.
3.
4.
5.
for quote_bloc in response.css('div.quote'):
quote = quote_bloc.css('span.text::text').get()
author = quote_bloc.css('small.author::text').get()
tags = quote_bloc.css('a.tag::text').getall()
yield QuoteItem(text=quote, author=author, tags=tags)
La fonction css('div.quote') renvoie tous les éléments des blocs de citations dans une liste. On itère sur cette dernière pour extraire la citation, l’auteur et les tags où l’on applique un getall() , car un bloc de citation peut contenir plusieurs tags. Enfin on yield avec notre objet qui a en « paramètre » les champs.
Les objets héritant de scrapy.Item sont en quelque sorte des tableaux associatifs. En effet, ils peuvent recevoir leur valeur de cette manière également :
2.
3.
4.
qi = QuoteItem()
qi['text'] = quote
qi['author'] = author
qi['tags'] = tags
VI. Scraper plusieurs pages avec start_requests▲
On a vu précédemment que dans notre spider, le champ start_urls permet à Scrapy de lancer des requêtes aux URLs stockées dans cette liste. Dans notre site d’étude, nous avons dix pages contenant des citations dont l’URL est sous cette forme : http://quotes.toscrape.com/page/<N>/
Cependant, rapporter à la main toutes les URLs peut s’avérer assez fastidieux. La méthode à implémenter start_request permet d’automatiser ce processus. Cette méthode doit yield une requête scrapy.Request :
2.
3.
4.
def start_requests(self):
for i in range(10):
url_page = f'http://quotes.toscrape.com/page/{i+1}/'
yield scrapy.Request(url=url_page, callback=self.parse)
Dans cet exemple, l’initialisation de l’objet scrapy.Request prend en paramètre l’URL que Scrapy va requêter et le callback qui va s’occuper du parsing.
Lancez la commande d’exécution : le fichier comporte les cent citations.
Mais avec cette manière de faire, si le concepteur du site décide d’ajouter une onzième page, notre spider ne pourra pas la prendre en compte. Une amélioration peut donc être faite.
Si l’on accède à la onzième page qui n’existe pas (http://quotes.toscrape.com/page/11), le site nous renvoie une belle page (code de statut HTTP 200) indiquant qu’aucune citation n’a été trouvée. Ce genre de pages a donc une structure HTML différente et ne contient alors pas le bloc div.quote. L’idée est donc de parcourir jusqu’à N infini les pages de cette URL http://quotes.toscrape.com/page/<N>/ et d’indiquer au programme de casser la boucle de parcours de pages lorsque le bloc div.quote n’est pas trouvé :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
break_requests = False
def start_requests(self):
i = 0
while True:
if self.break_requests:
break
url_page = f'http://quotes.toscrape.com/page/{i+1}/'
i += 1
yield scrapy.Request(url=url_page, callback=self.parse)
def parse(self, response):
quotes = response.css('div.quote')
if bool(quotes):
for quote_bloc in quotes:
yield QuoteItem(text=quote_block.css('span.text::text').get(),
author=quote_block.css('small.author::text').get(),
tags=quote_block.css('a.tag::text').getall())
else:
self.break_requests = True
Ouvrez le fichier de sortie JSON, vous verrez qu’on a toujours nos cent citations.
VII. Scraper des pages récursivement▲
Nous avons vu précédemment que nous pourrions à l’avance demander à Scrapy de parcourir des pages dont les URLs ont été présélectionnées. Qu’en est-il des URLs que l’on peut rencontrer en cours de route ? Comment les parcourir en cours de route ?
Au lieu de yield un objet scrapy.Item directement, on yield une requête scrapy.Request avec en paramètres :
- l’URL rencontrée ;
- un nouveau callback dédié pour parser la page de l’URL renseignée ;
- un ensemble de données qui seront complétées dans le callback.
Dans notre cas d’étude, chaque bloc de citation contient un lien qui renvoie vers une page contenant des informations additionnelles liées à l’auteur qu’on aimerait bien parser.
Enfin, le lien qui nous ramène vers la page de biographie de l’auteur se trouve dans le bloc de citation adjacent le bloc small contenant le nom de l’auteur.
quote_bloc = response.xpath('//div[@class="quote"]')
lien = quote_bloc.xpath('//span/a/@href').get()ou bien
quote_bloc = response.css('div.quote')
lien =quote_bloc.css('span a::attr(href)').get()Le lien de l’URL n’est pas entier, il faut donc le concaténer avec l’URL du domaine.
La fonction urljoin est implémentée dans l’objet response :
response.urljoin(lien).
Afin d’éviter de joindre à la main l’URL comme ci-dessus et faire du code à rallonge, nous pouvons aussi utiliser la méthode follow de l’objet response qui renvoie une requête Scrapy.
Dans notre exemple, nous souhaitons parser la page de chaque auteur. Pour ce faire, nous allons dans un premier temps étudier la structure d’une page de ce genre :(http://quotes.toscrape.com/author/Albert-Einstein/)
J’utilise Scrapy shell dans un premier temps pour m’assurer que mes sélecteurs HTML renvoient bien les blocs souhaités.
|
|
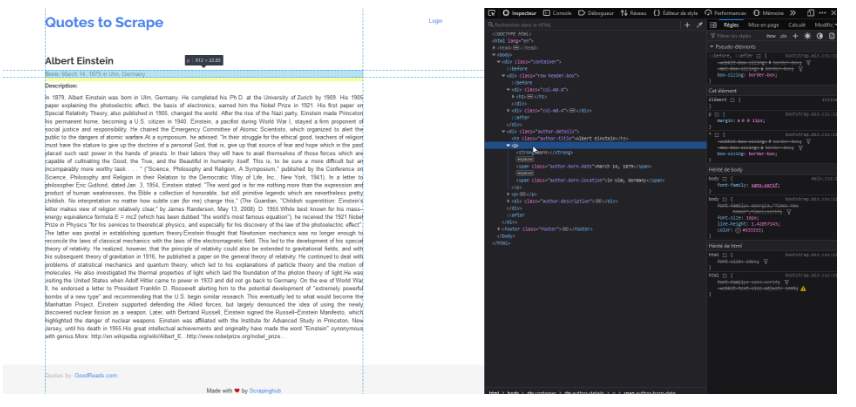
Le bloc surligné ci-dessus contient les informations liées à l’auteur que l’on voudrait extraire.
À l’intérieur de ce bloc nous avons une class "author-born-date" dans un bloc span, elle nous permettra de sélectionner la date de naissance :
response.xpath('//span[@class="author-born-date"]/text()').get()
ou bien
response.css('span.author-born-date::text').get().
L’autre information sur la même ligne est le lieu de naissance qui se trouve dans le span contenant la class "author-born-location" :
response.xpath('//span[@class="author-born-location"]/text()').get()
ou bien
response.css('span.author-born-location::text').get()
Cependant, le résultat est assez médiocre, car il inclut des chaînes de caractères en trop. Un petit replace fera l’affaire : <expression>.replace('in ', '').
Enfin, pourquoi ne pas également scraper la biographie tant qu’on y est ?
response.xpath('//div[@class="author-description"]/text()').get()
ou bien
response.css('div.author-description::text').get().
Une fois assurés de notre pratique de sélection, nous pouvons implémenter les modifications à notre spider.
Dans un premier temps, la première étape consiste à enrichir notre scrapy.Item QuoteItem en rajoutant les champs qui gèrent la date et le lieu de naissance ainsi que la biographie :
2.
3.
birthdate = scrapy.Field()
birthplace = scrapy.Field()
authorbio = scrapy.Field()
Ensuite, dans la fonction parse, au lieu de yield directement un scrapy.Item, nous allons yield une requête vers la page de l’auteur.
2.
3.
qi = QuoteItem(text=quote_bloc.css('span.text::text').get(),
author=quote_bloc.css('small.author::text').get(), tags=quote_bloc.css('a.tag::text').getall())
yield response.follow(url=quote_bloc.css('span a::attr(href)').get(), callback=self.parse_bio, cb_kwargs={'quote_item':qi})
Remarquez que l’on transfère notre item via cb_kwargs. C’est la méthode parse_bio qui recevra en paramètres non seulement la réponse de la requête, mais aussi l’item qu’on lui a transmis et c’est à son tour de yield cet item dûment complété.
2.
3.
4.
5.
def parse_bio(self, response, quote_item):
quote_item['birthdate'] = response.css('span.author-born-date::text').get()
quote_item['birthplace'] = response.css('span.author-born-location::text').get()
quote_item['authorbio'] = response.css('div.author-description::text').get()
yield quote_item
Exécutez le programme. Vous verrez que vous n’aurez pas toutes vos cent citations !
Si vous cherchez un peu (commentez la ligne qui s’occupe de renseigner la biographie pour avoir plus de visibilité dans la console), vous verrez que vous avez au moins une cinquantaine de codes de retour HTTP 308, et que dans les dernières lignes des logs, vous comprendrez que vous n’avez scrapé que 50 fois ('item_scraped_count': 50). En fait, Scrapy a ignoré les requêtes qui ont déjà été faites ('dupefilter/filtered': 50). Pas mal comme optimisation ! Cependant, cette option peut être désactivée dans le fichier de paramétrage settings.py afin d’avoir toutes nos citations.
VIII. Paramétrage du moteur Scrapy▲
Le fichier settings.py contient tous les paramètres globaux permettant d’apporter des modifications sur le comportement de l’exécution du scraping.
On a quelques paramètres déjà prédéfinis comme le nom du bot (BOT_NAME) et les modules (SPIDER_MODULES) et d’autres en bas. Les autres paramètres sont commentés avec quelques indications que vous pourriez lire pour apprendre plus.
Afin de fixer le problème de code 308, nous allons rajouter cette ligne :
DUPEFILTER_CLASS = 'scrapy.dupefilters.BaseDupeFilter'
Exécutez le programme : nous avons bien nos cent citations.
Cependant, mettre cette ligne en dur dans settings.py n’est pas en réalité une bonne pratique ; il est conseillé de renseigner le paramètre dont_filter à True lors de la création d’un objet scrapy.Request.
Assure-vous que cette ligne FEED_EXPORT_ENCODING = "utf-8" est présente dans les paramètres afin de pouvoir déchiffrer des caractères non ASCII (pas besoin de la rajouter dans notre cas, car elle est présente tout à la fin du fichier).
Voici une petite liste non exhaustive de paramètres :
- NEWSPIDER_MODULE : ce paramètre contient le dossier, ou plutôt le package, où Scrapy doit créer un nouveau spider avec la commande genspider. La commande genspider -l liste les différents types de spider (basic, crawl, csvfeed, xmlfeed). Nous avons dans ce tutoriel travaillé avec un spider de type basic. Pour générer une nouvelle classe d’araignée dans votre module, il suffit de lancer la commande qui suit : scrapy genspider -t <type> <nom_du_spider> <URL ou domaine à scraper>.
- USER_AGENT : cette option permet de modifier le nom du user agent, soit l’agent utilisateur en français, qui n’est en fait que l’application logicielle, le médium utilisant le protocole réseau. Cette information se transmet via l’en-tête des requêtes. En effet, pour afficher l’agent utilisateur d’une requête response de type scrapy.Request, il suffit d’afficher la valeur de response.request.headers[
'User-Agent']. Par défaut la valeur de USER_AGENT est comme ceci :"Scrapy/VERSION (+https://scrapy.org)". L’intérêt de changer ce paramètre et d’opter pour un agent utilisateur convaincant, tels ceux des navigateurs, est que certains sites pourraient bloquer votre activité de scraping, car vous ne correspondez pas à un utilisateur réel. Enfin, spécifier un agent utilisateur dans settings.py est peut-être mieux que rien, mais il est préférable d’effectuer une rotation d’agents utilisateurs pour que le serveur ne vous bloque pas en raison d’un nombre élevé et suspect de requêtes provenant du même agent. Vous l’aurez compris, les sites web n’aiment pas le scraping parce que ce genre d’activités surcharge les serveurs de requêtes ; au moindre doute, ils pourraient vous bloquer, voire vous bannir ! -
ROBOTSTXT_OBEY : il est renseigné dans le fichier à
True. Le fichier robots.txt est un fichier que les propriétaires peuvent mettre à la racine de leur site web permettant de donner des directives aux robots web, comme notre araignée, quant aux comportements à adopter vis-à-vis du site pour, par exemple, empêcher de visiter le site. Obéir au fichier robots.txt peut représenter un frein à notre activité de scraping, mieux vaut assigner la valeurFalseà ROBOTSTXT_OBEY. En ce qui concerne le site que nous avons scrapé, comme il est à but éducatif, il ne comporte pas de fichier robots.txt ; en effet, vous remarquerez dans la console la présence de ces lignes :- au début : [scrapy.core.engine] DEBUG: Crawled (404) <GET http://quotes.toscrape.com/robots.txt> (referer: None)
-
vers la fin : 'robotstxt/response_status_count/404': 1,
Le code de retour HTTP 404 confirme bien l’inexistence du fichier en question.
-
CONCURRENT_REQUESTS : ce paramètre, prenant un nombre entier, gère le nombre de requêtes concurrentes, c.-à-d. exécutées en même temps. Par défaut, Scrapy est paramétré pour lancer par paquet de seize requêtes. Mettez 1 comme valeur et remarquez le changement de la vitesse d’exécution.
- DOWNLOAD_DELAY : c’est le temps d’attente minimum en secondes entre deux requêtes consécutives opérant sur le même domaine web. Ce paramètre a son importance afin de soulager les serveurs de requêtes. DOWNLOAD_DELAY est affecté par le paramètre RANDOMIZE_DOWNLOAD_DELAY qui par défaut est à
Truepermettant de générer un temps d’attente aléatoire entre0.5*DOWNLOAD_DELAY et1.5*DOWNLOAD_DELAY.
Pour les paramètres importants qui restent – tels que SPIDER_MIDDLEWARES, DOWNLOADER_MIDDLEWARES, EXTENSIONS et ITEM_PIPELINES – il est nécessaire, dans un premier temps, de s’imprégner de l’architecture de Srapy afin de comprendre le rôle de chaque composant qui peut être activé ou désactivé dans le fichier settings.py.
IX. Un mot sur l’architecture de Scrapy▲
Vous l’aurez compris, nous n’avons en réalité manipulé qu’une partie des spiders représentant elle-même un bout de l’ensemble des composants de Scrapy.
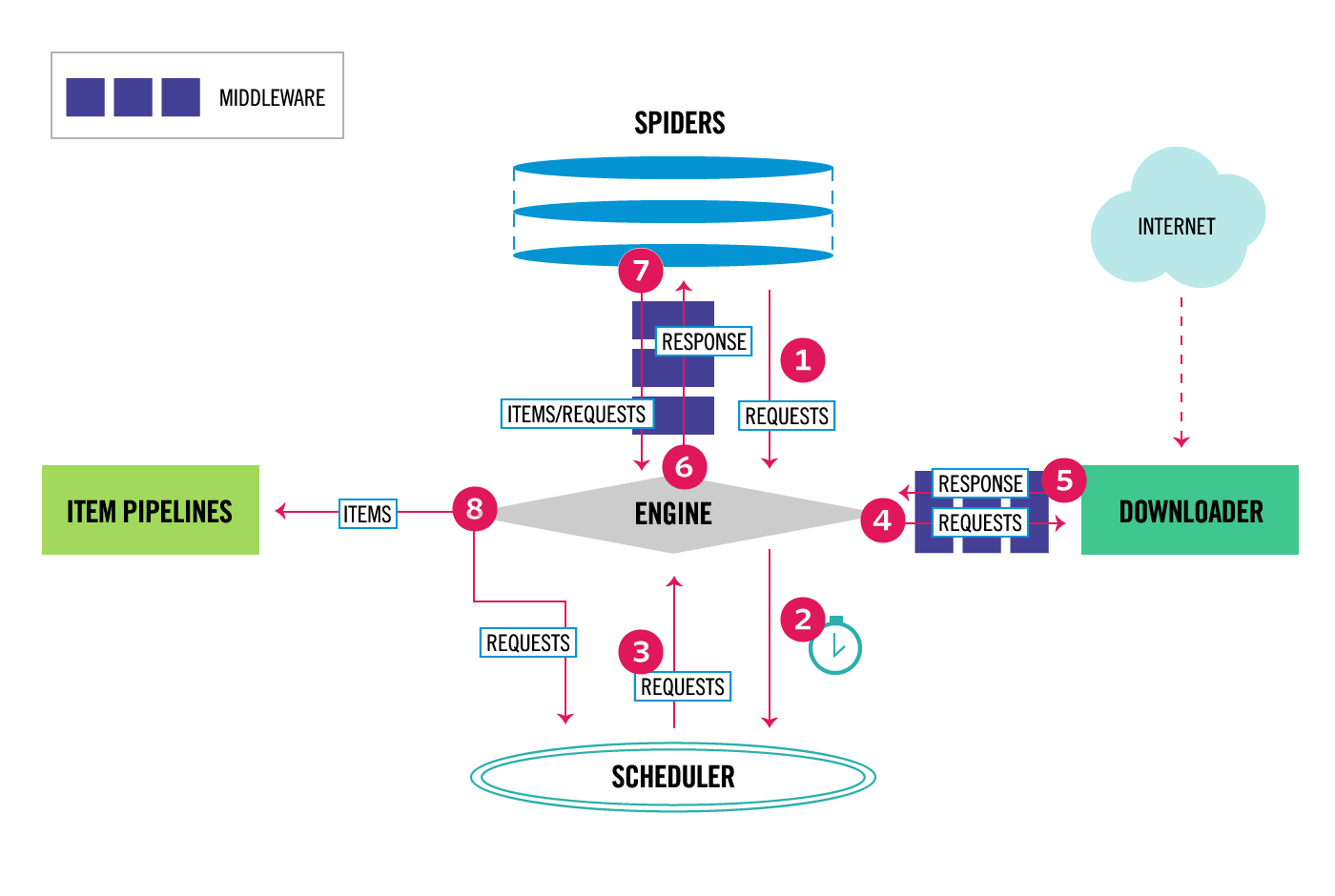
Le diagramme suivant présente un aperçu de l'architecture de Scrapy avec ses composants et une vue d'ensemble du flux de données, numéroté et indiqué par des flèches rouges, qui se déroule à l'intérieur du système :
|
|
|
https://docs.scrapy.org/en/latest/topics/architecture.html |
Le flux de données dans Scrapy est contrôlé par le moteur d'exécution et se déroule de la manière suivante :
- Le moteur récupère les demandes initiales à parcourir depuis l’araignée (spider).
- Le moteur planifie les demandes dans l'ordonnanceur (scheduler) et demande les prochaines requêtes à parcourir.
- L'ordonnanceur renvoie les prochaines requêtes au moteur.
- Le moteur envoie les requêtes au téléchargeur (downloader), en passant par les middleware du téléchargeur (voir le chapitre suivant).
- Une fois que la page est téléchargée, le téléchargeur génère une réponse de la page requêtée et l'envoie au moteur, en passant par les middlewares du téléchargeur (voir le chapitre suivant).
- Le moteur reçoit la réponse du downloader et l'envoie au spider, en passant par les middlewares d'araignée (voir le chapitre XI), pour effectuer du scraping.
- Le spider traite la réponse et renvoie les éléments extraits ainsi que de nouvelles requêtes à suivre au moteur, en passant par les middlewares d'araignée (voir le chapitre XI).
- Le moteur envoie les éléments traités aux pipelines d'éléments, puis envoie les requêtes traitées à l'ordonnanceur et demande les prochaines requêtes possibles à parcourir.
- Le processus se répète à partir de l'étape 3 jusqu'à ce qu'il n'y ait plus de requêtes provenant de l'ordonnanceur.
Par analogie avec le code que nous avions écrit, nous nous sommes occupés que de l’interface spiders-engine correspondant aux étapes numéro 1, 6 et 7 du diagramme :
- l’étape numéro 1 équivaut dans le code à l’appel de la méthode start_requests qui yield des requêtes ;
- l’étape numéro 2 c’est lorsque l’on reçoit l’objet response dans le callback de la requête (parse et parse_bio) ;
- et l’étape numéro 3 correspond dans le code à la réponse, pouvant être un item ou une requête, envoyée via yield par le callback de la requête (parse et parse_bio).
Le terme middleware désigne tout simplement une couche logicielle se situant entre deux composants.
Cependant, les étapes 1, 6 et 7 ont certes été abordées, mais nous avions fait abstraction de ce que l’on peut faire entre une araignée et le moteur Scrapy : implémenter un middleware d’araignées (voir le fichier middlewares.py).
X. Enrichir un spider avec un spider middleware▲
Le middleware d’araignée est la couche intermédiaire s’interposant entre le moteur de Scrapy et le spider. Son rôle principal est de traiter les réponses entrantes et les requêtes/items sortantes avant qu’elles soient envoyées au moteur.
Les middlewares d’araignées sont principalement utilisés pour :
- effectuer un post-traitement sur la sortie des araignées, que ce soit une requête ou un item ;
- effectuer un post-traitement sur les requêtes de départ (start_requests) ;
- gérer les exceptions.
Par défaut, Scrapy active des middleware d’araignées codés en interne dans la librairie. Ils sont activés comme suit dans la variable globale de paramétrage SPIDER_MIDDLEWARE_BASE :
2.
3.
4.
5.
6.
7.
{
"scrapy.spidermiddlewares.httperror.HttpErrorMiddleware": 50,
"scrapy.spidermiddlewares.offsite.OffsiteMiddleware": 500,
"scrapy.spidermiddlewares.referer.RefererMiddleware": 700,
"scrapy.spidermiddlewares.urllength.UrlLengthMiddleware": 800,
"scrapy.spidermiddlewares.depth.DepthMiddleware": 900,
}
Pour activer un middleware (comme par exemple celui qui est disponible dans le fichier middlewares.py et qui ne fait que d’afficher un texte au démarrage du spider), il suffit de renseigner dans un dictionnaire, dans le champ SPIDER_MIDDLEWARES du fichier settings.py, en tant que clef, le nom complet de la classe du middleware (<modules>.<nom_de_la_classe>) en chaîne de caractères suivi d’une valeur chiffrée correspondant à la priorité d’exécution. Une plus petite valeur signifie une meilleure priorité.
Pour désactiver les spiders middlewares activés par défaut par Scrapy, il suffit de reprendre le nom des classes en leur collant la valeur de None comme ci-dessous ;
2.
3.
4.
5.
6.
7.
{
"scrapy.spidermiddlewares.httperror.HttpErrorMiddleware": None,
"scrapy.spidermiddlewares.offsite.OffsiteMiddleware": None,
"scrapy.spidermiddlewares.referer.RefererMiddleware": None,
"scrapy.spidermiddlewares.urllength.UrlLengthMiddleware": None,
"scrapy.spidermiddlewares.depth.DepthMiddleware": None,
}
Le mécanisme d’ajout et de désactivation des middleware d’araignées activés par défaut par Scrapy est identique pour les middlewares du téléchargeur et les pipelines d’items.
Le spider middleware HttpErrorMiddleware permet de filtrer les réponses HTTP infructueuses pour que le spider n’ait pas à les gérer. Les réponses HTTP à succès ont un code compris entre 200 et 300.
OffsiteMiddleware permet de ne pas prendre les requêtes dont l’URL correspond à un domaine qui n’est pas autorisé par l’araignée. C’est le champ allowed_domains, défini dans l’araignée, qui permet de spécifier les domaines autorisés. Dans notre cas, nous autorisons uniquement le domaine quotes.toscrape.com. Ainsi, les requêtes dont le domaine est différent seront rejetées.
XI. Enrichir le téléchargeur avec un middleware▲
Le middleware du téléchargeur est une couche intermédiaire située entre le moteur de Scrapy et le téléchargeur (downloader). Son rôle principal est de traiter les requêtes sortantes du moteur avant qu'elles ne soient envoyées au téléchargeur, ainsi que les réponses entrantes du téléchargeur avant qu'elles ne soient renvoyées au moteur. Les downloader middleware peuvent effectuer des actions telles que la gestion des en-têtes, l'ajout de délais entre les requêtes, la gestion des proxies, la gestion de la mise en cache, etc. Ils agissent principalement au niveau du processus de téléchargement des pages.
Pour activer un downloader middleware, il faut renseigner le module et la classe dans le champ DOWNLOADER_MIDDLEWARE.
Les downloader middleware activés par défaut (DOWNLOADER_MIDDLEWARES_BASE) sont les suivants :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
{
"scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware": 100,
"scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware": 300,
"scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware": 350,
"scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware": 400,
"scrapy.downloadermiddlewares.useragent.UserAgentMiddleware": 500,
"scrapy.downloadermiddlewares.retry.RetryMiddleware": 550,
"scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware": 560,
"scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware": 580,
"scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware": 590,
"scrapy.downloadermiddlewares.redirect.RedirectMiddleware": 600,
"scrapy.downloadermiddlewares.cookies.CookiesMiddleware": 700,
"scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware": 750,
"scrapy.downloadermiddlewares.stats.DownloaderStats": 850,
"scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware": 900,
}
XII. Récupération de données avec les pipelines d’items▲
Le pipeline d’items se trouve à la fin de la chaîne où peuvent s’effectuer une série de traitements et de transformations sur les éléments, extraits par le spider, avant d’être éventuellement stockés en base de données ou employés pour un autre usage.
Les pipelines d’items sont typiquement utilisés pour :
- nettoyer les données HTML ;
- valider les données extraites (vérifier si l’item contient certains champs) ;
- vérifier si l’item n’a pas été dupliqué ;
- stocker les données extraites dans une base de données.
Le fichier pipelines.py contient une classe jouant le rôle de pipeline. Pour l’activer, il suffit de décommenter la ligne EXTENSIONS contenant le module dans le fichier settings.py
Pour exemple, notre pipeline va enrichir l’item en rajoutant un champ date qui stocke la date et heure lorsque l’item renvoyé arrive dans le pipeline. Il faut donc dans un premier temps importer datetime. Avant de stocker la date, il faut s’assurer de convertir l’item en dictionnaire avec la méthode asdict de la classe ItemAdapter.
2.
3.
4.
5.
6.
7.
8.
from itemadapter import ItemAdapter
from datetime import datetime
class ScrapyStartupSpiderPipeline:
def process_item(self, item, spider):
item_dic = ItemAdapter(item).asdict()
item_dic['date'] = datetime.now().strftime("%d/%m/%Y %H:%M:%S")
return item_dic
XIII. Conclusion▲
Vous venez de voir les bases du scrapping avec Scrapy. C’est un outil puissant permettant de faire beaucoup de choses en matière de récupération de données sur la toile pour ensuite faire ce que vous voulez avec. Cependant, il faut ne pas oublier que l’envoi excessif de requêtes vers un site assez sécurisé peut vous interrompre en vous interdisant l’accès au site et que c’est avant tout une activité qui frôle l’illégalité.