



19. Applications web▲
Vous avez certainement déjà appris par ailleurs un grand nombre de choses concernant la rédaction de pages web. Vous savez que ces pages sont des documents au format HTML, que l'on peut consulter via un réseau (intranet ou internet) à l'aide d'un logiciel appelé navigateur (Firefox, Internet explorer, Safari, Opera, Galeon, Konqueror, ...).
Les pages HTML sont installées dans les répertoires publics d'un autre ordinateur où fonctionne en permanence un logiciel appelé serveur web (Apache, IIS, Xitami, Lighttpd, ...). Lorsqu'une connexion a été établie entre cet ordinateur et le vôtre, votre logiciel navigateur peut dialoguer avec le logiciel serveur en lui envoyant des requêtes(par l'intermédiaire de toute une série de dispositifs matériels et logiciels dont nous ne traiterons pas ici : lignes téléphoniques, routeurs, caches, protocoles de communication...). Les pages web lui sont expédiées en réponseà ces requêtes.
19-A. Pages web interactives▲
Le protocole HTTP qui gère la transmission des pages web autorise l'échange de données dans les deux sens. Mais dans le cas de la simple consultation de sites, le transfert d'informations a surtout lieu dans l'un des deux, à savoir du serveur vers le navigateur : des textes, des images, des fichiers divers lui sont expédiés en grand nombre (ce sont les pages consultées) ; en revanche, le navigateur n'envoie guère au serveur que de toutes petites quantités d'information : essentiellement les adresses URL des pages que l'internaute désire consulter.
Vous savez cependant qu'il existe des sites web où vous êtes invité à fournir vous-même des quantités d'information plus importantes : vos références personnelles pour l'inscription à un club ou la réservation d'une chambre d'hôtel, votre numéro de carte de crédit pour la commande d'un article sur un site de commerce électronique, votre avis ou vos suggestions, etc.
Dans ces cas là, vous vous doutez bien que l'information transmise doit être prise en charge, du côté du serveur, par un programme spécifique. Il faudra donc associer étroitement un tel programme au serveur web. Quant aux pages web destinées à accueillir cette information (on les appelle des formulaires), il faudra les doter de divers widgets d'encodage (champs d'entrée, cases à cocher, boîtes de listes, etc.), afin que le navigateur puisse soumettre au serveur une requête accompagnée d'arguments. Le serveur pourra alors confier ces arguments au programme de traitement spécifique, et en fonction du résultat de ce traitement, renvoyer une réponse adéquate à l'internaute, sous la forme d'une nouvelle page web.
Il existe différentes manières de réaliser de tels programmes spécifiques, que nous appellerons désormais applications web.
L'une des plus répandues à l'heure actuelle consiste à utiliser des pages HTML « enrichies » à l'aide de scripts écrits à l'aide d'un langage spécifique tel que PHP. Ces scripts sont directement insérés dans le code HTML, entre des balises particulières, et ils seront exécutés par le serveur web (Apache, par exemple) à la condition que celui-ci soit doté du module interpréteur adéquat. Il est possible de procéder de cette façon avec Python via une forme légèrement modifiée du langage nommée PSP (Python Server Pages).
Cette approche présente toutefois l'inconvénient de mêler trop intimement le code de présentation de l'information (le HTML) et le code de manipulation de celle-ci (les fragments de script PHP ou PSP insérés entre balises), ce qui compromet gravement la lisibilité de l'ensemble. Une meilleure approche consiste à écrire des scripts distincts, qui génèrent du code HTML « classique » sous la forme de chaînes de caractères, et de doter le serveur web d'un module approprié pour interpréter ces scripts et renvoyer le code HTML en réponse aux requêtes du navigateur (par exemple mod_python, dans le cas de Apache).
Mais avec Python, nous pouvons pousser ce type de démarche encore plus loin, en développant nous-même un véritable serveur web spécialisé, tout à fait autonome, qui contiendra en un seul logiciel la fonctionnalité particulière souhaitée pour notre application. Il est en effet parfaitement possible de réaliser cela à l'aide de Python, car toutes les bibliothèques nécessaires à la gestion du protocole HTTP sont intégrées au langage. Partant de cette base, de nombreux programmeurs indépendants ont d'ailleurs réalisé et mis à la disposition de la communauté toute une série d'outils de développement pour faciliter la mise au point de telles applications web spécifiques. Pour la suite de notre étude, nous utiliserons donc l'un d'entre eux. Nous avons choisi Cherrypy, car celui-ci nous semble particulièrement bien adapté aux objectifs de cet ouvrage.
Note : Ce que nous allons expliquer dans les paragraphes qui suivent sera directement fonctionnel sur l'intranet de votre établissement scolaire ou de votre entreprise. En ce qui concerne l'internet, par contre, les choses sont un peu plus compliquées. Il va de soi que l'installation de logiciels sur un ordinateur serveur relié à l'internet ne peut se faire qu'avec l'accord de son propriétaire. Si un fournisseur d'accès à l'internet a mis a votre disposition un certain espace où vous êtes autorisé à installer des pages web « statiques » (c'est-à-dire de simples documents à consulter), cela ne signifie pas pour autant que vous pourrez y faire fonctionner des programmes ! Pour que cela puisse marcher, il faudra donc que vous demandiez une autorisation et un certain nombre de renseignements à votre fournisseur d'accès. La plupart d'entre eux refuseront cependant de vous laisser installer des applications tout à fait autonomes du type que nous décrivons ci-après, mais vous pourrez assez facilement convertir celles-ci afin qu'elles soient également utilisables avec le module mod_python de Apache, lequel est généralement disponible(97).
19-A-1. Un serveur web en pur Python !▲
L'intérêt pour le développement web est devenu très important à notre époque, et il existe donc une forte demande pour des interfaces et des environnements de programmation bien adaptés à cette tâche. Or, même s'il ne peut pas prétendre à l'universalité de langages tels que C/C++, Python est déjà largement utilisé un peu partout dans le monde pour écrire des programmes très ambitieux, y compris dans le domaine des serveurs d'applications web. La robustesse et la facilité de mise en œuvre du langage ont séduit de nombreux développeurs de talent, qui ont réalisé des outils de développement web de très haut niveau. Plusieurs de ces applications peuvent vous intéresser si vous souhaitez réaliser vous-même des sites web interactifs de différents types.
Les produits existants sont pour la plupart des logiciels libres. Ils permettent de couvrir une large gamme de besoins, depuis le petit site personnel de quelques pages, jusqu'au gros site commercial collaboratif, capable de répondre à des milliers de requêtes journalières, et dont les différents secteurs sont gérés sans interférence par des personnes de compétences variées (infographistes, programmeurs, spécialistes de bases de données, etc.).
Le plus célèbre de ces produits est le logiciel Zope, déjà adopté par de grands organismes privés et publics pour le développement d'intranets et d'extranets collaboratifs. Il s'agit en fait d'un système serveur d'applications, très performant, sécurisé, presqu'entièrement écrit en Python, et que l'on peut administrer à distance à l'aide d'une simple interface web. Il ne nous est pas possible de décrire l'utilisation de Zope dans ces pages : le sujet est trop vaste, et un livre entier n'y suffirait pas. Sachez cependant que ce produit est parfaitement capable de gérer de très gros sites d'entreprise en offrant d'énormes avantages par rapport à des solutions plus connues telles que PHP ou Java.
D'autres outils moins ambitieux mais tout aussi intéressants sont disponibles. Tout comme Zope, la plupart d'entre eux peuvent être téléchargés librement depuis Internet. Le fait qu'ils soient écrits en Python assure en outre leur portabilité : vous pourrez donc les employer aussi bien sous Windows que sous Linux ou MacOs. Chacun d'eux peut être utilisé en conjonction avec un serveur web « classique » tel que Apache ou Xitami (c'est d'ailleurs préférable si le site à réaliser est destiné à supporter une charge de connexions importante sur l'internet), mais la plupart d'entre eux intègrent leur propre serveur, ce qui leur permet de fonctionner également de manière tout à fait autonome. Cette possibilité se révèle particulièrement intéressante au cours de la mise au point d'un site, car elle facilite la recherche des erreurs.
Une totale autonomie, alliée à une grande facilité de mise en œuvre, font de ces produits de fort bonnes solutions pour la réalisation de sites web d'intranet spécialisés, notamment dans des petites et moyennes entreprises, des administrations, ou dans des écoles. Si vous souhaitez développer une application Python qui soit accessible à distance, par l'intermédiaire d'un simple navigateur web, ces outils sont faits pour vous. Il en existe une grande variété : Django, Turbogears, Spyce, Karrigell, Webware, Cherrypy, Quixote, Twisted, Pylons, etc(98). Choisissez en fonction de vos besoins : vous n'aurez que l'embarras du choix.
Dans les lignes qui suivent, nous allons décrire pas à pas le développement d'une application web fonctionnant à l'aide de Cherrypy. Vous pouvez trouver ce système à l'adresse : http://www.cherrypy.org. Il s'agit d'une solution de développement web très conviviale pour un programmeur Python, car elle lui permet de le développer un site web comme une application Python classique, sur la base d'un ensemble d'objets. Ceux-ci génèrent du code HTML en réponse aux requêtes HTTP qu'on leur adresse via leurs méthodes, et ces méthodes sont elles-mêmes perçues comme des adresses URL ordinaires par les navigateurs.
Pour la suite de ce texte, nous allons supposer que vous possédez quelques rudiments du langage HTML, et nous admettrons également que la bibliothèque Cherrypy a déjà été installée sur votre poste de travail. (Cette installation est décrite à la page ).
19-A-2. Première ébauche : mise en ligne d'une page web minimaliste▲
Dans votre répertoire de travail, préparez un petit fichier texte que vous nommerez tutoriel.conf, et qui contiendra les lignes suivantes :
[global]
server.socket_host = "127.0.0.1"
server.socket_port = 8080
server.thread_pool = 5
tools.sessions.on = True
tools.encode.encoding = "Utf-8"
[/annexes]
tools.staticdir.on = True
tools.staticdir.dir = "annexes"Il s'agit d'un simple fichier de configuration que notre serveur web consultera au démarrage. Notez surtout le n° de port utilisé (8080 dans notre exemple). Vous savez peut-être que les logiciels navigateurs s'attendent à trouver les services web sur le n° de port 80 par défaut. Si vous êtes le propriétaire de votre machine, et que vous n'y avez encore installé aucun autre logiciel serveur web, vous avez donc probablement intérêt à remplacer 8080 par 80 dans ce fichier de configuration : ainsi les navigateurs qui se connecteront à votre serveur ne devront pas spécifier un n° de port dans l'adresse. Cependant, si vous faites ces exercices sur une machine dont vous n'êtes pas l'administrateur, vous n'avez pas le droit d'utiliser les numéros de port inférieurs à 1024 (pour des raisons de sécurité). Dans ce cas, vous devez donc utiliser un numéro de port plus élevé que 80, tel celui que nous vous proposons. Il en va de même si un autre serveur web (Apache, par exemple) est déjà en fonction sur votre machine, car ce logiciel utilise très certainement déjà le port 80, par défaut.
Remarquez également la ligne concernant l'encodage. Il s'agit de l'encodage que Cherrypy devra utiliser dans les pages web produites. Il est possible que certains navigateurs web attendent une autre norme que Utf-8 comme encodage par défaut. Si vous obtenez des caractères accentués incorrects dans votre navigateur lorsque vous expérimenterez les exercices décrits ci-après, refaites vos essais en spécifiant un autre encodage dans cette ligne.
Les 3 dernières lignes du fichier indiquent le chemin d'un répertoire où vous placerez les documents « statiques » dont votre site peut avoir besoin (images, feuilles de style, etc.).
Veuillez à présent encoder le petit script ci-dessous :
2.
3.
4.
5.
6.
7.
8.
9.
import cherrypy
class MonSiteWeb(object): # Classe maîtresse de l'application
def index(self): # Méthode invoquée comme URL racine (/)
return "<h1>Bonjour à tous !</h1>"
index.exposed = True # la méthode doit être ?publiée'
###### Programme principal : #############
cherrypy.quickstart(MonSiteWeb(), config ="tutoriel.conf")
Lancez l'exécution du script. Si tout est en ordre, vous obtenez quelques lignes d'information similaires aux suivantes dans votre terminal. Elles vous confirment que « quelque chose » a démarré, et reste en attente d'événements :
[07/Jan/2010:18:00:34] ENGINE Listening for SIGHUP.
[07/Jan/2010:18:00:34] ENGINE Listening for SIGTERM.
[07/Jan/2010:18:00:34] ENGINE Listening for SIGUSR1.
[07/Jan/2010:18:00:34] ENGINE Bus STARTING
[07/Jan/2010:18:00:34] ENGINE Started monitor thread '_TimeoutMonitor'.
[07/Jan/2010:18:00:34] ENGINE Started monitor thread 'Autoreloader'.
[07/Jan/2010:18:00:34] ENGINE Serving on 127.0.0.1:8080
[07/Jan/2010:18:00:34] ENGINE Bus STARTEDVous venez effectivement de mettre en route un serveur web !
Il ne vous reste plus qu'à vérifier qu'il fonctionne bel et bien, à l'aide de votre navigateur préféré. Si vous utilisez ce navigateur sur la même machine que le serveur, dirigez-le vers une adresse telle que : http://localhost:8080, « localhost » étant une expression consacrée pour désigner la machine locale (vous pouvez également spécifier celle-ci à l'aide de l'adresse IP conventionnelle : 127.0.0.1), et « 8080 » le numéro de port choisi dans le fichier de configuration(99). Vous devriez obtenir la page d'accueil suivante :
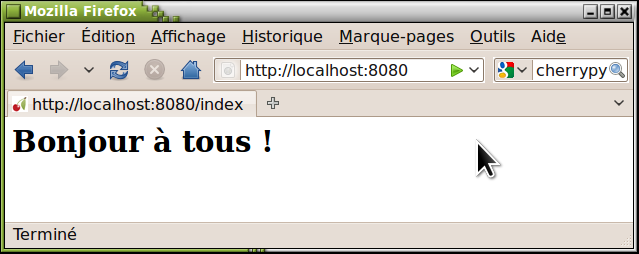
Examinons à présent notre script d'un peu plus près.
Sa concision est remarquable : seulement 6 lignes effectives !
Après importation du module cherrypy, on y définit une nouvelle classe MonSiteWeb(). Les objets produits à l'aide de cette classe seront des gestionnaires de requêtes. Leurs méthodes seront invoquées par un dispositif interne à Cherrypy, qui convertira l'adresse url demandée par le navigateur, en un appel de méthode avec un nom équivalent (nous illustrerons mieux ce mécanisme avec l'exemple suivant). Si l'url reçue ne comporte aucun nom de page, comme c'est le cas ici, c'est le nom index qui sera recherché par défaut, suivant une convention bien établie sur le web. C'est pour cette raison que nous avons nommé ainsi notre unique méthode, qui attend donc les requêtes s'adressant à la racine du site.
- Ligne 5 : Les méthodes de cette classe vont donc traiter les requêtes provenant du navigateur, et lui renvoyer en réponse des chaînes de caractères contenant du texte rédigé en HTML. Pour ce premier exercice, nous avons simplifié au maximum le code HTML produit, le résumant à un petit message inséré entre deux balises de titre (<h1> et </h1>). En toute rigueur, nous aurions dû insérer le tout entre balises <html></html> et <body></body> afin de réaliser une mise en page correcte. Mais puisque cela peut déjà fonctionner ainsi, nous attendrons encore un peu avant de montrer nos bonnes manières.
- Ligne 6 : Les méthodes destinées à traiter une requête HTTP et à renvoyer en retour une page web, doivent être « publiées » à l'aide d'un attribut exposed contenant une valeur « vraie ». Il s'agit là d'un dispositif de sécurité mis en place par Cherrypy, qui fait que par défaut, toutes les méthodes que vous écrivez sont protégées vis-à-vis des tentatives d'accès extérieurs indésirables. Les seules méthodes « accessibles » seront donc celles qui auront été délibérément rendues « publiques » à l'aide de cet attribut.
- Ligne 9 : La fonction quickstart() du module cherrypy démarre le serveur proprement dit. Il faut lui fournir en argument la référence de l'objet gestionnaire de requêtes qui sera la racine du site, ainsi que la référence d'un fichier de configuration générale.
19-A-3. Ajout d'une deuxième page▲
Le même objet gestionnaire peut bien entendu prendre en charge plusieurs pages :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
import cherrypy
class MonSiteWeb(object):
def index(self):
# Renvoi d'une page HTML contenant un lien vers une autre page
# (laquelle sera produite par une autre méthode du même objet) :
return '''
<h2>Veuillez <a href="unMessage">cliquer ici</a>
pour accéder à une information d'importance cruciale.</h2>
'''
index.exposed = True
def unMessage(self):
return "<h1>La programmation, c'est génial !</h1>"
unMessage.exposed = True
cherrypy.quickstart(MonSiteWeb(), config ="tutoriel.conf")
Ce script dérive directement du précédent. La page renvoyée par la méthode index() contient cette fois une balise-lien : <a href="unMessage"> dont l'argument est l'url d'une autre page. Si cette url est un simple nom, la page correspondante est supposée se trouver dans le répertoire racine du site. Dans la logique de conversion des url utilisée par Cherrypy, cela revient à invoquer une méthode de l'objet racine possédant un nom équivalent. Dans notre exemple, la page référencée sera donc produite par la méthode unMessage().
19-A-4. Présentation et traitement d'un formulaire▲
Les choses vont vraiment commencer à devenir intéressantes avec le script suivant :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
import cherrypy
class Bienvenue(object):
def index(self):
# Formulaire demandant son nom à l'utilisateur :
return '''
<form action="salutations" method="GET">
Bonjour. Quel est votre nom ?
<input type="text" name="nom" />
<input type="submit" value="OK" />
</form>
'''
index.exposed = True
def salutations(self, nom =None):
if nom: # Accueil de l'utilisateur :
return "Bonjour, {}, comment allez-vous ?".format(nom)
else: # Aucun nom n'a été fourni :
return 'Veuillez svp fournir votre nom <a href="/">ici</a>.'
salutations.exposed = True
cherrypy.quickstart(Bienvenue(), config ="tutoriel.conf")
La méthode index() de notre objet racine présente cette fois à l'utilisateur une page web contenant un formulaire : le code HTML inclus entre les balises <form> et </form> peut en effet contenir un ensemble de widgets divers, à l'aide desquels l'internaute pourra encoder des informations et exercer une certaine activité : champs d'entrée, cases à cocher, boutons radio, boîtes de listes, etc. Pour ce premier exemple, un champ d'entrée et un bouton suffiront :
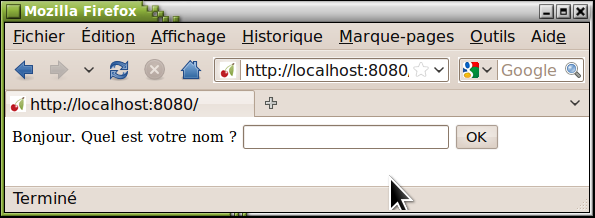
- La ligne 9 contient la balise HTML qui définit un champ d'entrée (balise <input type="text" name="nom" />). Son attribut name permet d'associer une étiquette à la chaîne de caractères qui sera encodée par l'utilisateur. Lorsque le navigateur transmettra au serveur la requête HTTP correspondante, celle-ci contiendra donc cet argument bien étiqueté. Comme nous l'avons déjà expliqué plus haut, Cherrypy convertira alors cette requête en un appel de méthode classique, dans lequel l'étiquette sera associée à son argument, de la manière habituelle sous Python.
- La ligne 10 définit un widget de type « bouton d'envoi » (balise <input type="submit">). Le texte qui doit apparaître sur le bouton est précisé par l'attribut value.
- Les lignes 15 à 20 définissent la méthode qui réceptionnera la requête, lorsque le formulaire aura été expédié au serveur. Son paramètre nom recevra l'argument correspondant, reconnu grâce à son étiquette homonyme. Comme d'habitude sous Python, vous pouvez définir des valeurs par défaut pour chaque paramètre (si un champ du formulaire est laissé vide par l'utilisateur, l'argument correspondant n'est pas transmis). Dans notre exemple, le paramètre nom contient par défaut un objet vide : il sera donc très facile de vérifier par programme, si l'utilisateur a effectivement entré un nom ou pas.
Le fonctionnement de tous ces mécanismes est finalement très naturel et très simple : les url invoquées dans les pages web sont converties par Cherrypy en appels de méthodes possédant les mêmes noms, auxquelles les arguments sont transmis de manière tout à fait classique.
19-A-5. Analyse de la communication et des erreurs▲
En expérimentant les scripts décrits jusqu'ici, vous aurez remarqué que divers messages apparaissent dans la fenêtre de terminal où vous avez lancé leur exécution. Ces messages vous renseignent (en partie) sur le dialogue qui s'est instauré entre le serveur et ses clients. Vous pourrez ainsi y suivre la connexion éventuellement établie avec votre serveur par d'autres machines (si votre serveur est relié à un réseau, bien entendu) :.
[12/Jan/2010:14:43:27] ENGINE Started monitor thread '_TimeoutMonitor'.
[12/Jan/2010:14:43:27] ENGINE Started monitor thread 'Autoreloader'.
[12/Jan/2010:14:43:27] ENGINE Serving on 127.0.0.1:8080
[12/Jan/2010:14:43:27] ENGINE Bus STARTED
127.0.0.1 - - [12/Jan/2010:14:43:31] "GET / HTTP/1.1" 200 215 "" "Mozilla/5.0
(X11; U; Linux i686; fr; rv:1.9.1.6) Gecko/20091215 Ubuntu/9.10 (karmic)
Firefox/3.5.6"
127.0.0.1 - - [12/Jan/2010:14:44:07] "GET /salutations?nom=Juliette HTTP/1.1"
200 39 "http://localhost:8080/" "Mozilla/5.0 (X11; U; Linux i686; fr;
rv:1.9.1.6) Gecko/20091215 Ubuntu/9.10 (karmic) Firefox/3.5.6"C'est dans cette fenêtre de terminal que vous trouverez également les messages d'erreur (fautes de syntaxe, par exemple) qui se rapportent à tout ce que votre programme met éventuellement en place avant le démarrage du serveur. Si une erreur est détectée en cours de fonctionnement, par contre (erreur dans une méthode gestionnaire de requêtes), le message d'erreur correspondant apparaît dans la fenêtre du navigateur, et le serveur continue de fonctionner. Voici par exemple le message que nous avons obtenu en ajoutant un ‘e' erroné au nom de la méthode format(), à la ligne 17 de notre script (formate(nom) au lieu de format(nom)) :
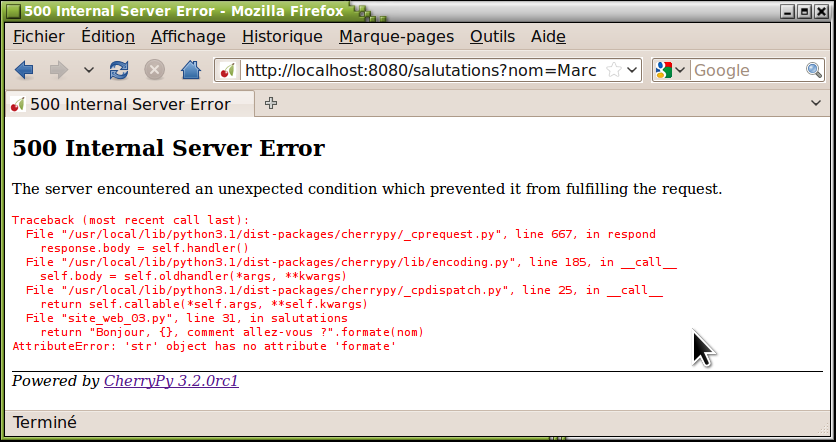
Vous pouvez vérifier que le serveur fonctionne toujours, en revenant à la page précédente et en entrant cette fois un nom vide. Cette faculté de ne pas se bloquer complètement lorsqu'une erreur est détectée est extrêmement importante pour un serveur web, car cela lui permet de continuer à répondre à la majorité des requêtes qu'il reçoit, même si certaines d'entre elles doivent être rejetées parce qu'il subsiste quelques petits défauts dans le programme. Ce comportement robuste est rendu possible par l'utilisation de threads (voir page ).
19-A-6. Structuration d'un site à pages multiples▲
Voyons à présent comment nous pouvons organiser notre site web de manière bien structurée, en établissant une hiérarchie entre les classes d'une manière analogue à celle qui lie les répertoires et sous-répertoires dans un système de fichiers.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
69.
70.
71.
72.
73.
74.
75.
76.
77.
78.
79.
80.
import cherrypy
class HomePage(object):
def __init__(self):
# Les objets gestionnaires de requêtes peuvent instancier eux-mêmes
# d'autres gestionnaires "esclaves", et ainsi de suite :
self.maxime = MaximeDuJour()
self.liens = PageDeLiens()
# L'instanciation d'objets gestionnaires de requêtes peut bien entendu
# être effectuée à n'importe quel niveau du programme.
def index(self):
return '''
<h3>Site des adorateurs du Python royal - Page d'accueil.</h3>
<p>Veuillez visiter nos rubriques géniales :</p>
<ul>
<li><a href="/entreNous">Restons entre nous</a></li>
<li><a href="/maxime/">Une maxime subtile</a></li>
<li><a href="/liens/utiles">Des liens utiles</a></li>
</ul>
'''
index.exposed = True
def entreNous(self):
return '''
Cette page est produite à la racine du site.<br />
[<a href="/">Retour</a>]
'''
entreNous.exposed =True
class MaximeDuJour(object):
def index(self):
return '''
<h3>Il existe 10 sortes de gens : ceux qui comprennent
le binaire, et les autres !</h3>
<p>[<a href="../">Retour</a>]</p>
'''
index.exposed = True
class PageDeLiens(object):
def __init__(self):
self.extra = LiensSupplementaires()
def index(self):
return '''
<p>Page racine des liens (sans utilité réelle).</p>
<p>En fait, les liens <a href="utiles">sont plutôt ici</a></p>
'''
index.exposed = True
def utiles(self):
# Veuillez noter comment le lien vers les autres pages est défini :
# on peut procéder de manière ABSOLUE ou RELATIVE.
return '''
<p>Quelques liens utiles :</p>
<ul>
<li><a href="http://www.cherrypy.org">Site de CherryPy</a></li>
<li><a href="http://www.python.org">Site de Python</a></li>
</ul>
<p>D'autres liens utiles vous sont proposés
<a href="./extra/"> ici </a>.</p>
<p>[<a href="../">Retour</a>]</p>
'''
utiles.exposed = True
class LiensSupplementaires(object):
def index(self):
# Notez le lien relatif pour retourner à la page maîtresse :
return '''
<p>Encore quelques autres liens utiles :</p>
<ul>
<li><a href="http://pythomium.net">Le site de l'auteur</a></li>
<li><a href="http://ubuntu-fr.org">Ubuntu : le must</a></li>
</ul>
<p>[<a href="../">Retour à la page racine des liens</a>]</p>
'''
index.exposed = True
racine = HomePage()
cherrypy.quickstart(racine, config ="tutoriel.conf")
Lignes 4 à 10 : La méthode constructeur des objets racine est l'endroit idéal pour instancier d'autres objets « esclaves ». On accédera aux méthodes gestionnaires de requêtes de ceux-ci exactement comme on accède aux sous-répertoires d'un répertoire racine (voir ci-après).
Lignes 12 à 22 : La page d'accueil propose des liens vers les autres pages du site. Remarquez la syntaxe utilisée dans les balises-liens, utilisée ici de manière à définir un chemin absolu :
- les méthodes de l'objet racine sont référencées par un caractère / suivi de leur nom seul. Le caractère / indique que le « chemin » part de la racine du site. Exemple : /entreNous.
- les méthodes racines des objets esclaves sont référencées à l'aide d'un simple / suivant le nom de ces autres objets. Exemple : /maxime/
- les autres méthodes des objets esclaves sont référencées à l'aide de leur nom inclus dans un chemin complet : Exemple : /liens/utiles
Lignes 36, 62 et 75 : Pour retourner à la racine du niveau précédent, on utilise cette fois un chemin relatif, avec la même syntaxe que celle utilisée pour remonter au répertoire précédent dans une arborescence de fichiers (deux points).
Lignes 41-42 : Vous aurez compris qu'on installe ainsi une hiérarchie en forme d'arborescence de fichiers, en instanciant des objets « esclaves » les uns à partir des autres. En suivant cette logique, le chemin absolu complet menant à la méthode index() de cette classe devrait être par conséquent /liens/extra/index.
19-A-7. Prise en charge des sessions▲
Lorsqu'on élabore un site web interactif, on souhaite fréquemment que la personne visitant le site puisse s'identifier et fournir un certain nombre de renseignements tout au long de sa visite dans différentes pages (l'exemple type est le remplissage d'un caddie au cours de la consultation d'un site commercial), toutes ces informations étant conservées quelque part jusqu'à la fin de sa visite. Et il faut bien entendu réaliser cela indépendamment pour chaque client connecté, car nous ne pouvons pas oublier qu'un site web est destiné à être utilisé en parallèle par toute une série de personnes.
Il serait possible de transmettre ces informations de page en page, à l'aide de champs de formulaires cachés (balises <INPUT TYPE="hidden">), mais ce serait compliqué et très contraignant. Il est donc préférable que le serveur soit doté d'un mécanisme spécifique, qui attribue à chaque client une session particulière, dans laquelle seront mémorisées toutes les informations particulières à ce client. Cherrypy réalise cet objectif par l'intermédiaire de cookies.
Lorsqu'un nouveau visiteur du site se présente, le serveur génère un cookie (c'est-à-dire un petit paquet d'informations contenant un identifiant de session unique sous la forme d'une chaîne aléatoire d'octets) et l'envoie au navigateur web, qui l'enregistre. En relation avec le cookie généré, le serveur va alors conserver durant un certain temps un objet-session dans lequel seront mémorisées toutes les informations spécifiques du visiteur. Lorsque celui-ci parcourt les autres pages du site, son navigateur renvoie à chaque fois le contenu du cookie au serveur, ce qui permet à celui-ci de l'identifier et de retrouver l'objet-session qui lui correspond. L'objet-session reste donc disponible tout au long de la visite de l'internaute : il s'agit d'un objet Python ordinaire, dans lequel on mémorise un nombre quelconque d'informations sous forme d'attributs.
Au niveau de la programmation, voici comment cela se passe :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
import cherrypy
class CompteurAcces(object):
def index(self):
# Exemple simplissime : incrémentation d'un compteur d'accès.
# On commence par récupérer le total actuel du comptage :
count = cherrypy.session.get('count', 0)
# ... on l'incrémente :
count += 1
# ... on mémorise sa nouvelle valeur dans le dictionnaire de session :
cherrypy.session['count'] = count
# ... et on affiche le compte actuel :
return '''
Durant la présente session, vous avez déjà visité
cette page {} fois ! Votre vie est bien excitante !
'''.format(count)
index.exposed = True
cherrypy.quickstart(CompteurAcces(), config='tutoriel.conf')
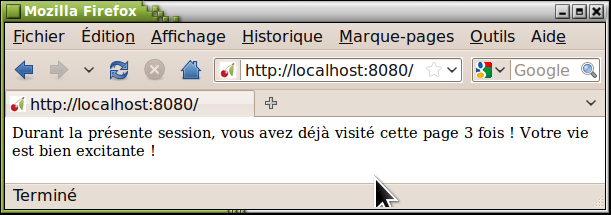
Il vous suffit de redemander la page produite par ce script à plusieurs reprises. Vous constaterez qu'à chaque fois le compteur de visites est bien incrémenté :
Le script lui-même devrait être assez explicite. On y remarquera que le module cherrypy est doté d'un objet session qui se comporte (apparemment) comme un dictionnaire classique. Nous pouvons lui ajouter des clefs à volonté, et associer à ces clefs des valeurs quelconques.
À la ligne 7 de notre exemple, nous utilisons la méthode get() des dictionnaires, pour retrouver la valeur associée à la clef count (ou zéro, si la clef n'existe pas encore). À la ligne 11 nous ré-enregistrons ensuite cette valeur, incrémentée, dans le même dictionnaire. Ainsi nous pouvons constater une fois de plus que Cherrypy met à notre disposition un environnement de programmation tout à fait familier pour un habitué de Python.
Remarquons toutefois que l'objet session, qui se comporte pour nous comme un simple dictionnaire, est en réalité l'interface d'une machinerie interne complexe, puisqu'il nous « sert » automatiquement les informations qui correspondent à un client particulier de notre site, identifié par l'intermédiaire de son cookie de session.
Pour bien visualiser cela, faites donc l'expérience d'accéder à votre serveur depuis deux navigateurs différents(100) (Firefox et Opera, par exemple) : vous constaterez que le décompte des visites est bel et bien différent pour chacun d'eux.
19-B. Réalisation concrète d'un site web interactif▲
Avec tout ce que vous avez appris jusqu'ici, vous devriez désormais pouvoir envisager la réalisation d'un projet d'une certaine importance. C'est ce que nous vous proposons ci-après en vous détaillant la mise en place d'une ébauche d'un site web quelque peu élaborée, utilisable pour la réservation en ligne de places de spectacle(101) :
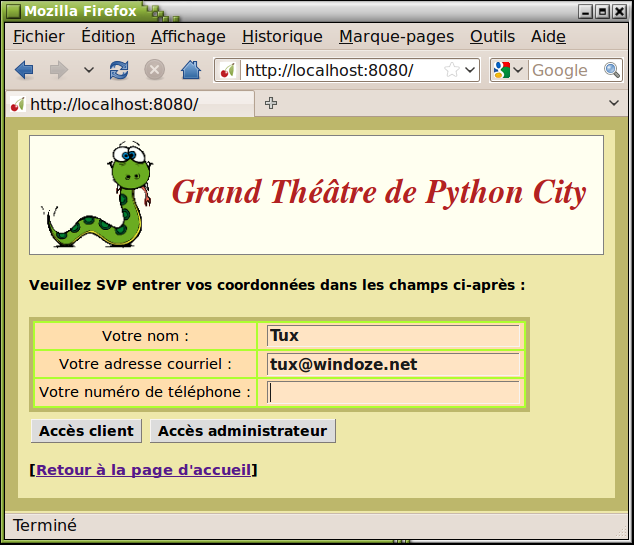
Les « administrateurs » du site peuvent ajouter de nouveaux spectacles à la liste et visionner les réservations déjà effectuées. Les « clients » peuvent s'enregistrer, réserver des places pour l'un ou l'autre des spectacles annoncés, et lister les places qu'ils ont déjà achetées.
Du fait qu'il ne s'agit toujours que d'un exercice, les fonctionnalités de cette petite application sont forcément très incomplètes. Il y manque notamment un dispositif de contrôle d'accès pour les administrateurs (via un système de login/mot de passe par exemple), la possibilité de supprimer ou modifier des spectacles existants, une gestion correcte des dates, des adresses courriel et des numéros de téléphone (ce sont ici de simples chaînes de caractères), etc., etc.
L'application intègre cependant une petite base de données relationnelle comportant trois tables, liées par deux relations de type « un à plusieurs ». Les pages web produites possèdent une mise en page commune, et leur décoration utilise une feuille de style CSS. Le code python de l'application et le code HTML « patron » sont bien séparés dans des fichiers distincts.
Nous avons donc intégré dans cet exemple un maximum de concepts utiles, mais délibérément laissé de côté tout le code de contrôle qui serait indispensable dans une véritable application pour vérifier les entrées de l'utilisateur, détecter les erreurs de communication avec la base de données, etc., afin de ne pas encombrer la démonstration.
- Le traitement des données est assuré par le script Python que nous décrivons ci-après. Il est entièrement inclus dans un seul
fichier (spectacles.py), mais nous vous le présenterons en plusieurs morceaux afin de faciliter les explications et d'aérer quelque peu le texte.
Ce script fait appel au mécanisme des sessions pour garder en mémoire les coordonnées de l'utilisateur pendant tout le temps que dure sa visite du site. - La présentation des données est assurée par un ensemble de pages web, dont le code HTML est rassemblé pour sa plus grande partie dans un fichier texte distinct (spectacles.htm). Par programme, on extraira de ce fichier des chaînes de caractères qui seront formatées par insertion de valeurs issues de variables, suivant la technique décrite au chapitre 10. Ainsi le contenu statique des pages n'encombrera pas le script lui-même. Nous reproduisons le contenu de ce fichier à la page .
-
19-B-1. Le script▲
Le script spectacles.py commence par définir une classe Glob() qui servira uniquement de conteneur pour des variables que nous voulons traiter comme globales. On y trouve notamment la description des tables de la base de données dans un dictionnaire, suivant une technique similaire à celle que nous avons expliquée au chapitre précédent :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
import os, cherrypy, sqlite3
class Glob(object):
"Données à caractère global pour l'application"
patronsHTML ="spectacles.htm" # Fichier contenant les "patrons" HTML
html ={} # Les patrons seront chargés dans ce dictionnaire
# Structure de la base de données. Dictionnaire des tables & champs :
dbName = "spectacles.sq3" # nom de la base de données
tables ={"spectacles":(("ref_spt","k"), ("titre","s"), ("date","t"),
("prix_pl","r"), ("vendues","i")),
"reservations":(("ref_res","k"), ("ref_spt","i"), ("ref_cli","i"),
("place","i")),
"clients":(("ref_cli","k"), ("nom","s"), ("e_mail","s"),
("tel", "i")) }
Viennent ensuite les définitions de deux fonctions. La première (lignes 16 à 32) ne sera utilisée qu'une seule fois au démarrage. Son rôle consiste à lire l'intégralité du fichier texte spectacles.htm afin d'en extraire les « patrons » HTML qui seront utilisés pour formater les pages web. Si vous examinez la structure de ce fichier (nous avons reproduit son contenu à la page ), vous constaterez qu'il contient une série de sections, clairement délimitées chacune par deux repères : une balise d'ouverture (elle-même formée d'un libellé inclus entre deux astérisques et des crochets), et une ligne terminale constituée d'au moins 5 caractères #. Chaque section peut donc ainsi être extraite séparément, et mémorisée dans un dictionnaire global (glob.html). Les clés de ce dictionnaire seront les libellés trouvés, et les valeurs les sections correspondantes, chacune d'elles contenant donc une « page » de code HTML, avec des balises de conversion {} qui pourront être remplacées par les valeurs de variables.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
def chargerPatronsHTML():
# Chargement de tous les "patrons" de pages HTML dans un dictionnaire :
fi =open(Glob.patronsHTML,"r")
try: # pour s'assurer que le fichier sera toujours refermé
for ligne in fi:
if ligne[:2] =="[*": # étiquette trouvée ==>
label =ligne[2:] # suppression [*
label =label[:-1].strip() # suppression LF et esp évent.
label =label[:-2] # suppression *]
txt =""
else:
if ligne[:5] =="#####":
Glob.html[label] =txt
else:
txt += ligne
finally:
fi.close() # fichier refermé dans tous les cas
La seconde fonction, quoique toute simple, effectue un travail remarquable : c'est elle en effet qui va nous permettre de donner à toutes nos pages un aspect similaire, en les insérant dans un patron commun. Ce patron, comme tous les autres, provient à l'origine du fichier spectacles.htm, mais la fonction précédente l'aura déjà mis à notre disposition dans le dictionnaire Glob.html, sous le libellé "miseEnPage" :
35.
36.
37.
def mep(page):
# Fonction de "mise en page" du code HTML généré : renvoie la <page>
# transmise, agrémentée d'un en-tête et d'un bas de page adéquats.
return Glob.html["miseEnPage"].format(page)
Vient ensuite la définition d'une classe d'objets-interfaces pour l'accès à la base de données. Cette classe est certainement très perfectible(102). Vous y retrouverez l'application de quelques principes décrits au chapitre précédent. Si vous effacez le fichier spectacles.sq3 qui contient la base de données, celle-ci sera recréée automatiquement par la méthode creaTables() :
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
69.
70.
71.
72.
73.
74.
75.
76.
77.
78.
79.
80.
81.
82.
83.
84.
85.
86.
class GestionBD(object):
"Mise en place et interfaçage d'une base de données SQLite"
def __init__(self, dbName):
"Établissement de la connexion - Création du curseur"
self.dbName =dbName
def executerReq(self, req, param =()):
"Exécution de la requête <req>, avec détection d'erreur éventuelle"
connex =sqlite3.connect(self.dbName)
cursor =connex.cursor()
try:
cursor.execute(req, param)
except Exception as err:
# renvoyer la requête et le message d'erreur système :
msg ="Requête SQL incorrecte :\n{}\nErreur détectée :".format(req)
return msg +str(err)
if "SELECT" in req.upper():
return cursor.fetchall() # renvoyer une liste de tuples
else:
connex.commit() # On enregistre systématiquement
cursor.close()
connex.close()
def creaTables(self, dicTables):
"Création des tables de la base de données si elles n'existent pas déjà"
for table in dicTables: # parcours des clés du dictionnaire
req = "CREATE TABLE {} (".format(table)
pk =""
for descr in dicTables[table]:
nomChamp = descr[0] # libellé du champ à créer
tch = descr[1] # type de champ à créer
if tch =="i":
typeChamp ="INTEGER"
elif tch =="k":
# champ 'clé primaire' (entier incrémenté automatiquement)
typeChamp ="INTEGER PRIMARY KEY AUTOINCREMENT"
pk = nomChamp
elif tch =="r":
typeChamp ="REAL"
else: # pour simplifier, nous considérons
typeChamp ="TEXT" # comme textes tous les autres types
req += "{} {}, ".format(nomChamp, typeChamp)
req = req[:-2] + ")"
try:
self.executerReq(req)
except:
pass # La table existe probablement déjà
Le script se poursuit avec la définition de la classe qui assure la fonctionnalité du site web. Comme nous l'avons expliqué dans les pages précédentes, Cherrypy convertit chacune des url demandées par le navigateur web en un appel de méthode de cette classe.
89.
90.
91.
92.
93.
94.
class WebSpectacles(object):
"Classe générant les objets gestionnaires de requêtes HTTP"
def index(self):
# Page d'entrée du site web - renvoi d'une page HTML statique :
return mep(Glob.html["pageAccueil"])
index.exposed =True
La page d'entrée du site est une page statique, dont le texte a donc été chargé dans le dictionnaire Glob.html (sous le libellé "pageAccueil") pendant la phase d'initialisation du programme. La méthode index() doit donc simplement renvoyer ce texte, préalablement « habillé » à l'aide de la fonction mep() pour lui donner l'aspect commun à toutes les pages.
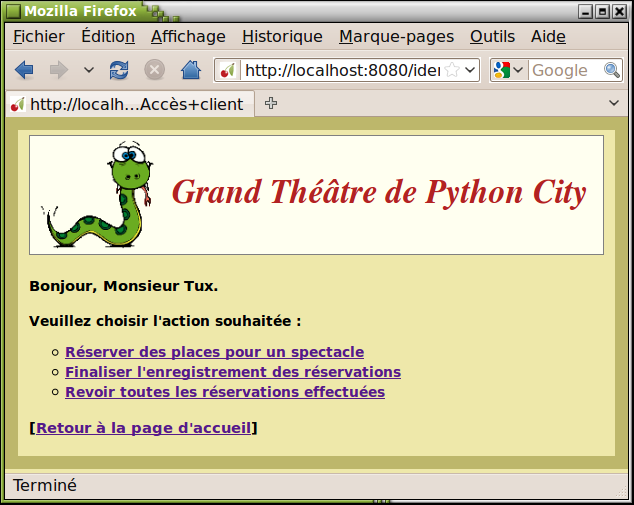
La méthode suivante est un peu plus complexe. Pour bien comprendre son fonctionnement, il est préférable d'examiner d'abord le contenu la page web qui aura été renvoyée à l'utilisateur par la méthode index() (cf. ligne 93). Cette page contient un formulaire HTML, que nous reproduisons ci-après. Un tel formulaire est délimité par les balises <form> et </form> :
<form action="/identification" method=GET>
<h4>Veuillez SVP entrer vos coordonnées dans les champs ci-après :</h4>
<table>
<tr><td>Votre nom :</td><td><input name="nom"></td></tr>
<tr><td>Votre adresse courriel :</td><td><input name="mail"></td></tr>
<tr><td>Votre numéro de téléphone :</td><td><input name="tel"></td></tr>
</table>
<input type=submit class="button" name="acces" value="Accès client">
<input type=submit class="button" name="acces" value="Accès administrateur">
</form>L'attribut action utilisé dans la balise <form> indique indique l'url qui sera invoquée lorsque le visiteur du site aura cliqué sur l'un des boutons de type submit. Cette url sera convertie par Cherrypy en un appel de la méthode de même nom, à la racine du site puisque le nom est précédé d'un simple /. C'est donc la méthode identification() de notre classe principale qui sera appelée. Les balises de type <input name= "..."> définissent les champs d'entrée, chacun avec son libellé spécifique signalé par l'attribut name. Ce sont ces libellés qui permettront à Cherrypy de transmettre les valeurs encodées dans ces champs, aux paramètres de mêmes noms de la méthode identification(). Examinons à présent celle-ci :
96.
97.
98.
99.
100.
101.
102.
103.
104.
105.
106.
107.
def identification(self, acces="", nom="", mail="", tel=""):
# On mémorise les coord. de l'utilisat. dans des variables de session :
cherrypy.session["nom"] =nom
cherrypy.session["mail"] =mail
cherrypy.session["tel"] =tel
if acces=="Accès administrateur":
return mep(Glob.html["accesAdmin"]) # renvoi d'une page HTML
else:
# Une variable de session servira de "caddy" pour les réservations :
cherrypy.session["caddy"] =[] # (liste vide, au départ)
# Renvoi d'une page HTML, formatée avec le nom de l'utilisateur :
return mep(Glob.html["accesClients"].format(nom))
identification.exposed =True
Les arguments reçus sont donc réceptionnés dans les variables locales acces, nom, mail et tel. Si nous souhaitons que ces valeurs restent mémorisées spécifiquement pour chaque utilisateur durant sa visite de notre site, il nous suffit de les confier aux bons soins de l'objet cherrypy.session, qui se présente à nous sous l'apparence d'un simple dictionnaire (Lignes 98-100).
Ligne 101 : Le paramètre acces aura reçu la valeur correspondant au bouton submit qui aura été utilisé par le visiteur, à savoir la chaîne « Accès administrateurs » ou « Accès client ». Cela nous permet donc d'aiguiller ce visiteur vers d'autres pages.
Ligne 104 : Nous allons mémoriser les réservations envisagées par le visiteur dans une liste de tuples, qu'il pourra remplir à sa guise. Par analogie avec ce qui se pratique sur les sites de commerce électronique en ligne, nous appellerons cette liste son « panier » ou « caddy ». L'enregistrement de ces réservations dans la base de données aura lieu plus tard, dans une étape distincte, et seulement lorsqu'il en exprimera le souhait. Nous devrons donc conserver cette liste tout au long de la visite, dans une variable de session libellée "caddy" (Nous appellerons désormais variables de session les valeurs mémorisées dans l'objet cherrypy.session).
La ligne 107 combine deux formatages successifs, le premier pour fusionner le code HTML produit localement (le nom entré par l'utilisateur) avec celui d'un patron extrait du dictionnaire glob.html, et le second pour « envelopper » l'ensemble dans un autre patron, commun à toutes les pages celui-là, par l'intermédiaire de la fonction mep().
La page web ainsi renvoyée est une simple page statique, qui fournit les liens menant à d'autres pages. La suite du script contient les méthodes correspondantes :
111.
112.
113.
114.
115.
116.
117.
118.
119.
120.
121.
122.
123.
124.
125.
126.
127.
128.
129.
130.
131.
132.
133.
134.
135.
136.
137.
138.
139.
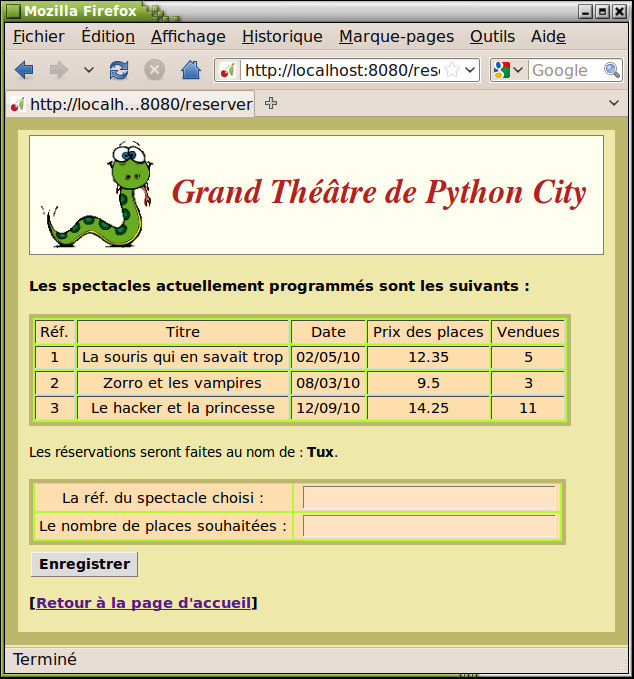
def reserver(self):
# Retouver le nom utilisateur dans les variables de session :
nom =cherrypy.session["nom"]
# Retrouver la liste des spectacles proposés :
req ="SELECT ref_spt, titre, date, prix_pl, vendues FROM spectacles"
res =BD.executerReq(req) # On obtient une liste de tuples
# Construire un tableau html pour lister les infos trouvées :
tabl ='<table border="1" cellpadding="5">\n'
ligneTableau ="<tr>" +"<td>{}</td>"*5 +"</tr>\n"
# Ajouter une ligne en haut du tableau avec les en-têtes de colonnes :
tabl += ligneTableau.\
format("Réf.", "Titre", "Date", "Prix des places", "Vendues")
for ref, tit, dat, pri, ven in res:
tabl +=ligneTableau.format(ref, tit, dat, pri, ven)
tabl +="</table>"
# Renvoyer une page HTML (assemblage d'un "patron" et de valeurs) :
return mep(Glob.html["reserver"].format(tabl, nom))
reserver.exposed =True
def reservations(self, tel="", spect="", places=""):
# Mémoriser les réservations demandées, dans une variable de session :
spect, places = int(spect), int(places) # conversion en nombres
caddy =cherrypy.session["caddy"] # récupération état actuel
caddy.append((spect, places)) # ajout d'un tuple à la liste
cherrypy.session["caddy"] =caddy # mémorisation de la liste
nSp, nPl = len(caddy), 0
for c in caddy: # totaliser les réservations
nPl += c[1]
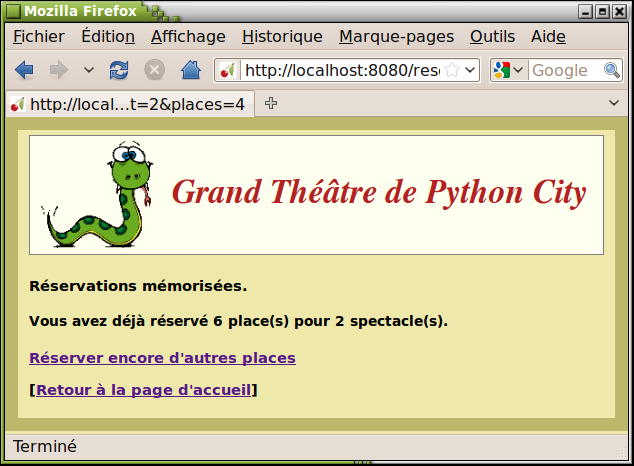
return mep(Glob.html["reservations"].format(nPl, nSp))
reservations.exposed =True
Lignes 110-127 : Cette méthode fait appel à la base de données pour pouvoir afficher la liste des spectacles déjà encodés. Examinez particulièrement les lignes 116 à 124, qui vous montrent comment vous pouvez très efficacement construire par programme tout le code HTML décrivant un tableau, en vous servant des techniques de création et de formatage des chaînes de caractères que nous avons vues au chapitre 10. À la ligne 126, on se sert à nouveau de la même technique pour fusionner le code produit localement avec un patron HTML.
Lignes 129-139 : La page web produite ainsi est à nouveau un formulaire. L'examen de son code HTML (voir page ) nous indique que c'est cette fois la méthode reservations() qui sera invoquée lorsque l'utilisateur actionnera le bouton « Enregistrer ». Cette méthode réceptionne les valeurs entrées dans le formulaire et les rassemble dans un tuple, puis ajoute celui-ci à la liste contenue dans la variable de session "caddy". Elle renvoie ensuite à l'utilisateur une petite page qui l'informe sur l'évolution de ses demandes.
Ligne 131 : Tous les arguments transmis par un formulaire HTML sont des chaînes de caractères. Si ces arguments représentent des valeurs numériques, il faut donc les convertir dans le type adéquat avant de les utiliser comme telles.
Le reste du script est reproduit ci-après. Vous y trouverez les méthodes qui permettent à l'utilisateur « client » de clôturer sa visite du site en demandant l'enregistrement de ses réservations, ou de revoir des réservations qu'il aurait effectuées précédemment. Les méthodes concernant les fonctions réservées aux « administrateurs » viennent ensuite. Elles sont construites sur les mêmes principes et ne nécessitent guère de commentaires.
Les requêtes SQL figurant dans les lignes suivantes devraient être assez explicites. Leur description détaillée sort du cadre de cet ouvrage, et nous ne nous y attarderons donc pas. Si elles vous paraissent quelque peu complexes, ne vous découragez pas : l'apprentissage de ce langage peut être très progressif. Sachez cependant qu'il s'agit d'un passage obligé si vous souhaitez acquérir une vraie compétence de développeur.
142.
143.
144.
145.
146.
147.
148.
149.
150.
151.
152.
153.
154.
155.
156.
157.
158.
159.
160.
161.
162.
163.
164.
165.
166.
167.
168.
169.
170.
171.
172.
173.
174.
175.
176.
177.
178.
179.
180.
181.
182.
183.
184.
185.
186.
187.
188.
189.
190.
191.
192.
193.
194.
195.
196.
197.
198.
199.
200.
201.
202.
203.
204.
205.
206.
207.
208.
209.
210.
211.
212.
213.
214.
215.
216.
217.
218.
219.
220.
221.
222.
223.
224.
225.
226.
227.
228.
229.
230.
231.
232.
233.
234.
235.
236.
237.
238.
239.
240.
241.
242.
243.
244.
245.
246.
247.
248.
def finaliser(self):
# Finaliser l'enregistrement du caddy.
nom =cherrypy.session["nom"]
mail =cherrypy.session["mail"]
tel =cherrypy.session["tel"]
caddy =cherrypy.session["caddy"]
# Enregistrer les références du client dans la table ad hoc :
req ="INSERT INTO clients(nom, e_mail, tel) VALUES(?,?,?)"
res =BD.executerReq(req, (nom, mail, tel))
# Récupérer la réf. qui lui a été attribuée automatiquement :
req ="SELECT ref_cli FROM clients WHERE nom=?"
res =BD.executerReq(req, (nom,))
client =res[0][0] # extraire le 1er élément du 1er tuple
# Parcours du caddy - enregistrement des places pour chaque spectacle :
for (spect, places) in caddy:
# Rechercher le dernier N° de place déjà réservée pour ce spect. :
req ="SELECT MAX(place) FROM reservations WHERE ref_spt =?"
res =BD.executerReq(req, (int(spect),))
numP =res[0][0]
if numP is None:
numP =0
# Générer les numéros de places suivants, les enregistrer :
req ="INSERT INTO reservations(ref_spt,ref_cli,place) VALUES(?,?,?)"
for i in range(places):
numP +=1
res =BD.executerReq(req, (spect, client, numP))
# Enregistrer le nombre de places vendues pour ce spectacle :
req ="UPDATE spectacles SET vendues=? WHERE ref_spt=?"
res =BD.executerReq(req, (numP, spect))
cherrypy.session["caddy"] =[] # vider le caddy
return self.accesClients() # Retour à la page d'accueil
finaliser.exposed =True
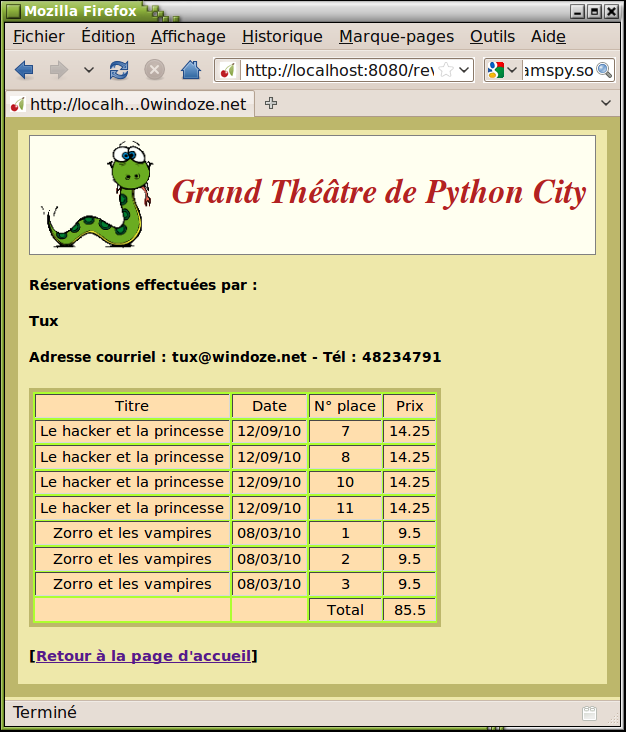
def revoir(self):
# Retrouver les infos concernant un client particulier.
# On retrouvera sa référence à l'aide de son adresse courriel :
mail =cherrypy.session["mail"]
req ="SELECT ref_cli, nom, tel FROM clients WHERE e_mail =?"
res =BD.executerReq(req, (mail,))
client, nom, tel =res[0]
# Spectacles pour lesquels il a acheté des places :
req ="SELECT titre, date, place, prix_pl "\
"FROM reservations JOIN spectacles USING (ref_spt) "\
"WHERE ref_cli =? ORDER BY titre, place"
res =BD.executerReq(req, (client,))
# Construction d'un tableau html pour lister les infos trouvées :
tabl ='<table border="1" cellpadding="5">\n'
ligneTableau ="<tr>" +"<td>{}</td>"*4 +"</tr>\n"
# Ajouter une ligne en haut du tableau avec les en-têtes de colonnes :
tabl += ligneTableau.format("Titre", "Date", "N° place", "Prix")
tot =0 # compteur pour prix total
for titre, date, place, prix in res:
tabl += ligneTableau.format(titre, date, place, prix)
tot += prix
# Ajouter une ligne en bas du tableau avec le total en bonne place :
tabl += ligneTableau.format("", "", "Total", str(tot))
tabl += "</table>"
return mep(Glob.html["revoir"].format(nom, mail, tel, tabl))
revoir.exposed =True
def accesClients(self):
nom =cherrypy.session["nom"]
return mep(Glob.html["accesClients"].format(nom))
accesClients.exposed =True
def entrerSpectacles(self):
return mep(Glob.html["entrerSpectacles"])
entrerSpectacles.exposed =True
def memoSpectacles(self, titre ="", date ="", prixPl =""):
# Mémoriser un nouveau spectacle
if not titre or not date or not prixPl:
return '<h4>Complétez les champs ! [<a href="/">Retour</a>]</h4>'
req ="INSERT INTO spectacles (titre, date, prix_pl, vendues) "\
"VALUES (?, ?, ?, ?)"
msg =BD.executerReq(req, (titre, date, float(prixPl), 0))
return self.index() # Retour à la page d'accueil
memoSpectacles.exposed =True
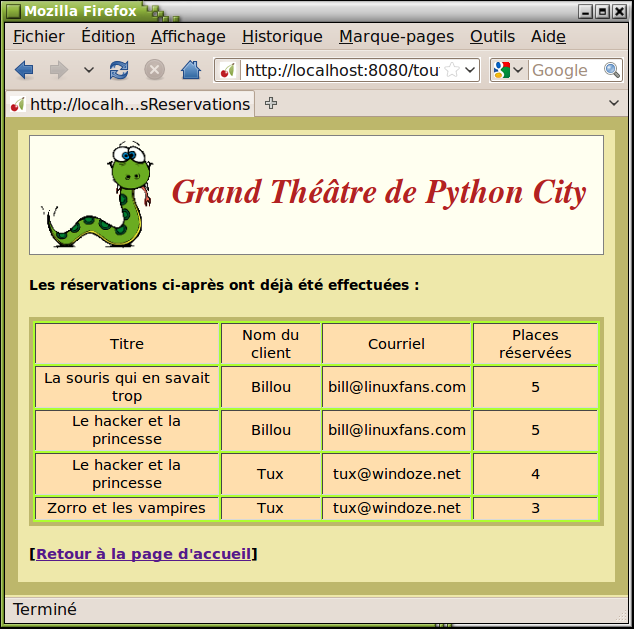
def toutesReservations(self):
# Lister les réservations effectuées par chaque client
req ="SELECT titre, nom, e_mail, COUNT(place) FROM spectacles "\
"LEFT JOIN reservations USING(ref_spt) "\
"LEFT JOIN clients USING (ref_cli) "\
"GROUP BY nom, titre "\
"ORDER BY titre, nom"
res =BD.executerReq(req)
# Construction d'un tableau html pour lister les infos trouvées :
tabl ='<table border="1" cellpadding="5">\n'
ligneTableau ="<tr>" +"<td>{}</td>"*4 +"</tr>\n"
# Ajouter une ligne en haut du tableau avec les en-têtes de colonnes :
tabl += ligneTableau.\
format("Titre", "Nom du client", "Courriel", "Places réservées")
for tit, nom, mail, pla in res:
tabl += ligneTableau.format(tit, nom, mail, pla)
tabl +="</table>"
return mep(Glob.html["toutesReservations"].format(tabl))
toutesReservations.exposed =True
# === PROGRAMME PRINCIPAL ===
# Ouverture de la base de données - création de celle-ci si elle n'existe pas :
BD =GestionBD(Glob.dbName)
BD.creaTables(Glob.tables)
# Chargement des "patrons" de pages web dans un dictionnaire global :
chargerPatronsHTML()
# Reconfiguration et démarrage du serveur web :
cherrypy.config.update({"tools.staticdir.root":os.getcwd()})
cherrypy.quickstart(WebSpectacles(), config ="tutoriel.conf")
19-B-2. Les « patrons » HTML▲
Les « patrons » HTML utilisés par le script (en tant que chaînes de caractères à formater) sont tous contenus dans un seul fichier texte, que nous reproduisons intégralement ci-après :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
69.
70.
71.
72.
73.
74.
75.
[*miseEnPage*]
<html>
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type">
<link rel=stylesheet type=text/css media=screen href="/annexes/spectacles.css">
</head>
<body>
<h1><img src="/annexes/python.gif">Grand Théâtre de Python City</h1>
{}
<h3>[<a href="/">Retour à la page d'accueil</a>]</h3>
</body>
</html>
##########
[*pageAccueil*]
<form action="/identification" method=GET>
<h4>Veuillez SVP entrer vos coordonnées dans les champs ci-après :</h4>
<table>
<tr><td>Votre nom :</td><td><input name="nom"></td></tr>
<tr><td>Votre adresse courriel :</td><td><input name="mail"></td></tr>
<tr><td>Votre numéro de téléphone :</td><td><input name="tel"></td></tr>
</table>
<input type=submit class="button" name="acces" value="Accès client">
<input type=submit class="button" name="acces" value="Accès administrateur">
</form>
##########
[*accesAdmin*]
<h3><ul>
<li><a href="/entrerSpectacles">Ajouter de nouveaux spectacles</a><Li>
<li><a href="/toutesReservations">Lister les réservations</a></li>
</ul></h3>
##########
[*accesClients*]
<h3>Bonjour, Monsieur {}.</h3>
<h4>Veuillez choisir l'action souhaitée :<ul>
<li><a href="/reserver">Réserver des places pour un spectacle</a></li>
<li><a href="/finaliser">Finaliser l'enregistrement des réservations</a></li>
<li><a href="/revoir">Revoir toutes les réservations effectuées</a></li>
</ul></h4>
##########
[*reserver*]
<h3>Les spectacles actuellement programmés sont les suivants : </h3>
<p>{}</p>
<p>Les réservations seront faites au nom de : <b>{}</b>.</p>
<form action="/reservations" method=GET>
<table>
<tr><td>La réf. du spectacle choisi :</td><td><input name="spect"></td></tr>
<tr><td>Le nombre de places souhaitées :</td><td><input name="places"></td></tr>
</table>
<input type=submit class="button" value="Enregistrer">
</form>
##########
[*reservations*]
<h3>Réservations mémorisées.</h3>
<h4>Vous avez déjà réservé {} place(s) pour {} spectacle(s).</h4>
<h3><a href="/reserver">Réserver encore d'autres places</a></h3>
##########
[*entrerSpectacles*]
<form action="/memoSpectacles">
<table>
<tr><td>Titre du spectacle :</td><td><input name="titre"></td></tr>
<tr><td>Date :</td><td><input name="date"></td></tr>
<tr><td>Prix des places :</td><td><input name="prixPl"></td></tr>
</table>
<input type=submit class="button" value="Enregistrer">
</form>
##########
[*toutesReservations*]
<h4>Les réservations ci-après ont déjà été effectuées :</h4>
<p>{}</p>
##########
[*revoir*]
<h4>Réservations effectuées par :</h4>
<h3>{}</h3><h4>Adresse courriel : {} - Tél : {}</h4>
<p>{}</p>
##########
Avec cet exemple un peu élaboré, nous espérons que vous aurez bien compris l'intérêt de séparer le code Python et le code HTML dans des fichiers distincts, comme nous l'avons fait, afin que l'ensemble de votre production conserve une lisibilité maximale. Une application web est en effet souvent destinée à grandir et à devenir de plus en plus complexe au fil du temps. Vous devez donc mettre toutes les chances de votre côté pour qu'elle reste toujours bien structurée et facilement compréhensible. En utilisant des techniques modernes comme la programmation par objets, vous êtes certainement sur la bonne voie pour progresser rapidement et acquérir une maîtrise très productive.
Exercices
Le script précédent peut vous servir de banc d'essai pour exercer vos compétences dans un grand nombre de domaines.
.Comme expliqué précédemment, on peut structurer un site web en le fractionnant en plusieurs classes. Il serait judicieux de séparer les méthodes concernant les « clients » et les « administrateurs » de ce site dans des classes différentes.
.Le script tel qu'il est ne fonctionne à peu près correctement que si l'utilisateur remplit correctement tous les champs qui lui sont proposés. Il serait donc fort utile de lui ajouter une série d'instructions de contrôle des valeurs encodées, avec renvoi de messages d'erreur à l'utilisateur lorsque c'est nécessaire.
.L'accès « administrateurs » permet seulement d'ajouter de nouveaux spectacles, mais non de modifier ou de supprimer ceux qui sont déjà encodés. Ajoutez donc des méthodes pour implémenter ces fonctions.
.L'accès administrateur est libre. Il serait judicieux d'ajouter au script un mécanisme d'authentification par mot de passe, afin que cet accès soit réservé aux seules personnes possédant le sésame.
.L'utilisateur « client » qui se connecte plusieurs fois de suite, est à chaque fois mémorisé comme un nouveau client, alors qu'il devrait pouvoir ajouter d'autres réservations à son compte existant, éventuellement modifier ses données personnelles, etc. Toutes ces fonctionnalités pourraient être ajoutées.
.Vous aurez probablement remarqué que les tableaux HTML générés dans le script sont produits à partir d'algorithmes très semblables. Il serait donc intéressant d'écrire une fonction généraliste capable de produire un tel tableau, dont on recevrait la description dans un dictionnaire ou une liste.
.La décoration des pages web générées par le script est définie dans une feuille de style annexe (le fichier spectacles.css). Libre à vous d'examiner ce qui se passe si vous enlevez le lien activant cette feuille de style (5e ligne du fichier spectacles.htm), ou si vous modifiez son contenu, lequel décrit le style à appliquer à chaque balise.
19-C. Autres développements▲
Si vous cherchez à réaliser un site web très ambitieux, prenez également la peine d'étudier d'autres offres logicielles, comme par exemple Karrigell, Django, Pylons, TurboGears, Twisted, Zope, Plone, ... associés à Apache pour le système serveur, et MySQL ou PostgreSQL pour le gestionnaire de bases de données. Vous aurez compris qu'il s'agit d'un domaine très vaste, où vous pourrez exercer votre créativité pendant longtemps…
